






正向传播
正向传播(Forward Propagation)是神经网络中的一个过程,它是神经网络从输入数据到输出结果的推导过程。在正向传播过程中,输入数据通过神经网络的各个层,逐层进行计算和变换,最终得到神经网络的输出结果。
具体来说,正向传播包括以下步骤:
1. 输入数据传入输入层:将输入数据传入神经网络的输入层。
2. 加权求和:输入数据通过连接输入层的神经元到下一层的连接权重,进行加权求和。每个神经元都有一个偏置项,用于调整加权求和的结果。
3. 激活函数:对每个神经元的加权求和结果应用激活函数,将其转换为非线性的输出。这个非线性变换是神经网络引入非线性映射的关键。
4. 传递到下一层:将激活函数的输出作为下一层的输入,继续进行加权求和和激活函数操作。
5. 重复直至输出层:重复步骤 2 和 3,直到数据通过所有隐藏层(中间层)传递到输出层。输出层的输出即为神经网络的最终预测结果。
正向传播是一个顺序的过程,数据从输入层经过各层逐步传递,最终到达输出层。在这个过程中,神经网络会根据每一层的连接权重和激活函数,将输入数据映射到更高维度的空间,并逐步提取和学习数据的特征和模式。这使得神经网络能够在处理复杂的非线性问题时具有强大的表达能力。
反向传播
反向传播(Backpropagation)是神经网络中的一种训练算法,用于调整神经网络的参数(权重和偏置),使得神经网络能够更好地拟合训练数据,并提高在未见过的数据上的泛化能力。通过反向传播算法,神经网络可以自动地根据训练数据的误差,逐层地更新参数,从而减少预测结果与真实结果之间的误差。
反向传播的过程可以分为以下几个步骤:
1. 正向传播:首先,将一个训练样本输入到神经网络中,通过正向传播算法计算神经网络的输出结果。
2. 计算损失函数:将神经网络的输出结果与真实结果进行比较,计算损失函数(Loss Function),用于衡量预测结果与真实结果之间的差异。
3. 反向传播误差:根据损失函数的值,通过反向传播算法计算每个参数(权重和偏置)对损失函数的影响。这是通过链式法则(Chain Rule)来实现的,即将损失函数对参数的导数从输出层向输入层进行传播。
4. 更新参数:根据反向传播算法计算得到的参数梯度(即损失函数对参数的导数),使用优化算法(如梯度下降法)来更新每个参数,使得损失函数尽可能地减小。
5. 重复直至收敛:重复执行上述步骤,将多个训练样本输入神经网络进行反向传播和参数更新,直至损失函数收敛或达到预定的训练轮数。
通过反向传播算法,神经网络可以不断地调整参数,最小化损失函数,从而使得神经网络在训练数据上表现更好。这样,神经网络可以学习到数据的特征和模式,从而在未见过的数据上也能够有良好的预测能力,达到泛化的效果。反向传播算法是训练神经网络的核心算法之一,它使得神经网络能够逐渐优化并适应各种复杂的问题。
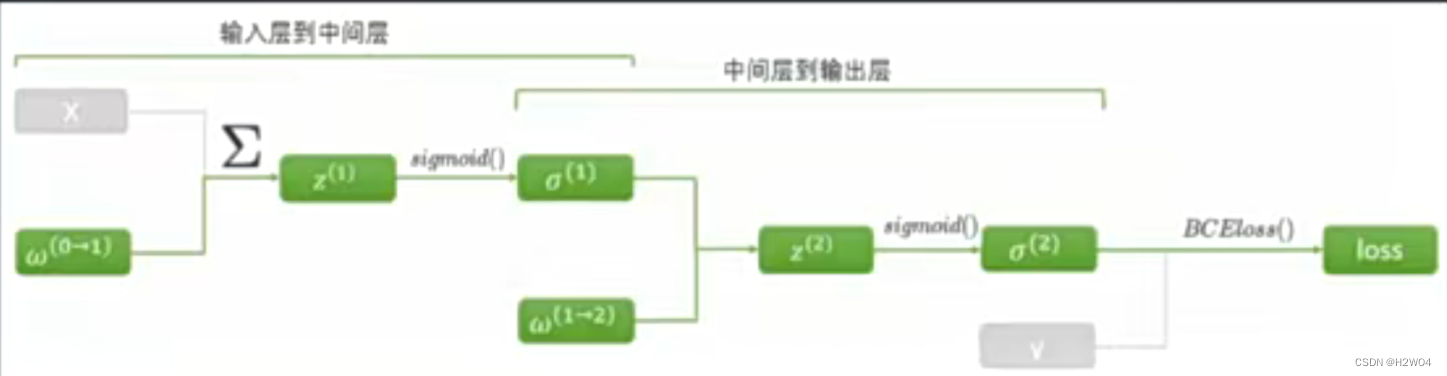
对于上图,正向传播就是从输入数据X向右计算得到结果。反向传播则是通过loss函数求对
每一层参数
的偏导,是从右向左的过程。首先计算第二层的
的偏导,再向左计算第一层的
的偏导。计算
时偏导链中有部分已经在计算
的偏导时算过了,计算量不会很大。
使用pytorch求梯度(aotugrad)
import torch
x=torch.tensor(1,requires_grad=True #默认是False,用于指示创建的 Tensor 是否需要计算梯度
,dtype=torch.float32)
y=x**3
torch.autograd.grad(y,x)在pytorch中,每一次正向传播都会生成一张计算图,运行过一次反向传播后这张计算图就会被释放(为了节省内存),所以不能在一张计算图上重复计算反向传播,否则会报错
backward()进行反向传播
import torch
from torch.nn import functional as F
import torch.nn as nn
#随机生成数据
torch.manual_seed(212)
X=torch.rand((500,20),dtype=torch.float32)*100
y=torch.randint(low=0,high=3
,size=(500,) #交叉熵损失函数要求y是一维的
,dtype=torch.float32) #交叉熵损失函数要求y是int64类型,调用时再转int
#定义输入及输出的特征量
input_=X.shape[1]
output_=len(y.unique())
#定义神经网络架构
#3分类,500个样本,20个特征,共3层,第一层13个神经元,第二层8个神经元
#第一层激活函数ReLU,第二层sigmoid
class Model(nn.Module):
def __init__(self,in_features=40,out_features=2):
super().__init__()
self.linear1=nn.Linear(in_features,13,bias=False)
self.linear2=nn.Linear(13,8,bias=False)
self.output=nn.Linear(8,out_features,bias=True)
def forward(self,x):
sigma1=torch.relu(self.linear1(x))
sigma2=torch.sigmoid(self.linear2(sigma1))
zhat=self.output(sigma2)
return zhat
net=Model(in_features=input_,out_features=output_)
zhat=net.forward(X)
#定义损失函数,使用交叉熵CrossEntropyLoss
criterion=nn.CrossEntropyLoss()
loss=criterion(zhat,y.long()) #要求y是int64类型
loss.backward()
net.linear1.weight.grad #查看梯度值在使用backward()进行反向传播时,不需要给数据设定requires_grad=True
首先backward只会识别叶子节点(就是左侧没有结点的点),不在叶子上的变量是不会被backward考虑的。对于全部叶子节点来说,只有属性requires_grad=True的节点,才会被计算。在设置X与y时,我们都没有写requires_grad参数,也就是默认让“允许求解梯度”这个选项为False,所以backward在计算的时候就只会计算关于的部分。
当然,我们也可以将X和y或者任何除了权重以及截距的量的requires grad打开,一旦我们设置为True,backward就会在帮助我们计算的导数的同时,也帮我们计算以X或y为自变量的导数。在正常的梯度下降和反向传播过程中,我们是不需要这些导数的,因此我们一律不去管requires_grad的设置,就让它默认为False,以节约计算资源。
对于backward(),有参数retain_graph可以设置。设置为True后会保存计算图,可以重复调用backward函数。若未设置则只能运行一次















 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









