






卷积层的优势
参数共享:卷积带来参数量骤减
深度学习的模型总是需要大规模计算和训练来达到商业使用标准,计算量一直都是深度学习领域的痛,而巨大的计算量在很多时候都与巨量参数有关。在卷积神经网络诞生之前,人们一直使用普通全连接的DNN来训练图像数据。对于一张大小中等,尺寸为(600,400)的图像而言,若要输入全连接层的DNN,则需要将像素拉平至一维,在输入层上就需要600*400 = 24万个神经元,这就意味着我们需要24万个参数来处理这一层上的全部像素。如果我们有数个隐藏层,且隐藏层上的神经元个数达到10000个,那DNN大约需要24亿个参数(2.4*10^9个)才能够解决问题。
然而,卷积神经网络却有“参数共享”(Parameter Sharing)的性质,可以令参数量骤减。一个通道虽然可以含有24万个像素点,但图像上每个“小块”的感受野都使用相同的卷积核来进行过滤。卷积神经网络要求解的参数就是卷积核上的所有数字,所以24万个像素点共享卷积核就等于共享参数。假设卷积核的尺寸是5x5,那处理24万个像素点就需要25个参数。假设卷积中其他需要参数层也达到10000个,那CNN所需的参数也只有25万。参数量的巨大差异,让卷积神经网络的计算非常高效。
稀疏交互:获取更深入的特征
在任何神经网络中,一个神经元都只能够储存一个数字。所以在CNN中,一个像素就是一个神经元(实际上就是我们在类似如下的视图中看到的每个正方形小格子)。很容易理解,输入的图像/通道上的每个小格子就是输入神经元feature map上的每个格子就是输出神经元。在DNN中,上层的任意神经元都必须和下层的每个神经元都相连,所以被称之为“全连接”(fuly connected),但在CNN中,下层的一神经元只和上层中被扫描的那些神经元有关,在图上即表示为,feature map上的绿格子只和原图上绿色覆盖的部分有关。这种神经元之间并不需要全链接的性质被称为稀疏交互(Sparse Interaction)。人们认为,稀疏交互让CNN获得了提取更深特征的能力。
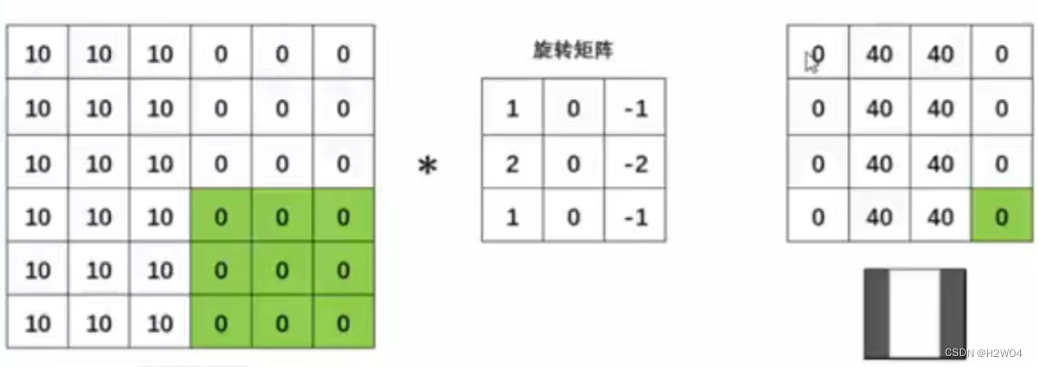
CNN的“稀疏交互”的属性允许神经元只包含上一层图像”局部”的信息,这就与人眼的简单细胞只提取简单线条的属性很相似。因此我们有理由相信,当图像被输入网络后,前端的卷积神经网络提取到的特征都是浅层的 (和sobel算子等方法一样),将这些浅层特征继续输入后续的网络,再次进行提取和学习,就能够将浅层特征逐渐组合成深层特征。而图像天生就可以通过不断变换、被提取出更多的特征
相对的,自然语言就没有这个性质,所以NLP领域的CNN往往没有CV领域的CNN深
在Pytorch中构建卷积神经网络
按照卷积的操作和效果,又可分为普通卷积、转置卷积、延迟初始化的lazyConv等等。最常用的是处理图像的普通卷积nn.Conv2d。其类及其包含的超参数参数内容如下
torch.nn.Conv2d (in_channels, out_channels, kernel_size, stride=1, padding=0,dilation=1, groups=1, bias=True, padding mode='zeros')
需要说明的是,参数groups和dilation分别代表着分组卷积(Grouped Convolution) 与膨胀卷积(Dilated Convolution),本文的介绍还是专注于普通卷积的参数介绍
二维卷积层nn.Conv2d
卷积核尺寸kernel_size
无默认值,必填,可输入整数或数组,输入整数则代表卷积和的形状为正方形,输入数组则代表卷积核的形状与数组一致
卷积核尺寸常选择的
卷积核尺寸一般选择边长为奇数的正方形。
如果原始图像的尺寸很宽或者很长可以考虑选择跟原始图像比例相近的卷积核尺寸。
而边长为奇数的设置可以保证扫描区域是中心对称的,不易使得图像在多轮卷积操作后失真。但这种说法缺乏有效的理论基础,也可能存在偶数卷积核能使得模型效果更好的情况。
在计算机视觉中,一般选择较小的卷积核,其所需的训练参数会更少。在NLP中许多网络的卷积核的尺寸都可以很大。
特征图/卷积核的数目:in_channels,out_channels,bias
in_channels是输入卷积层的图像的通道数或上一层传入特征图的数量,out_channels是指这一层输出的特征图的数量。
设置参数bias=True,则会将偏差值加到特征图的每一元素中,相当于进行一次矩阵+常数的计算
特征图的尺寸:stride,padding,padding_mode
stride:步长:可以对特征图进行降维,通常设置为1~3之间的数字
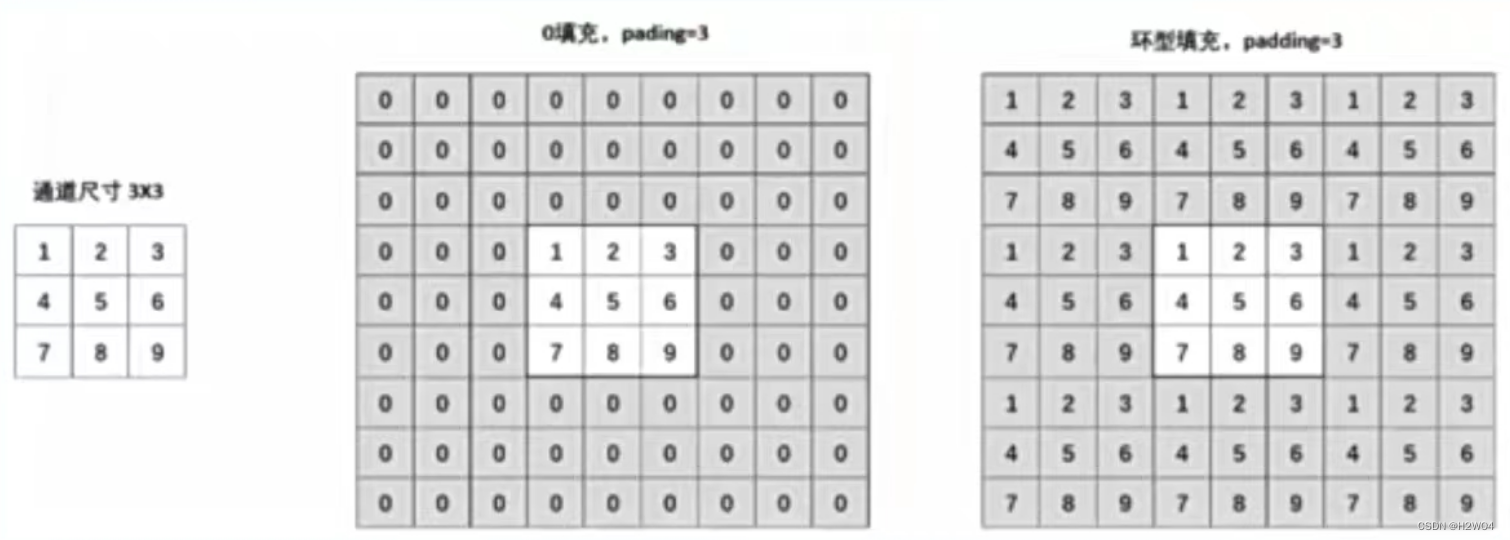
padding_mode可以控制填充的内容,Pytorch中提供了两种填充方式:0填充与环形填充。padding_mode='circular'则调用环形填充
但是padding操作也不能保证图像被完全扫描,对于无法扫描完全的情况,有“valid”和“same”两种处理方式。但Pytorch中只能实现“valid”方式,也就是对扫描不到的部分直接丢弃
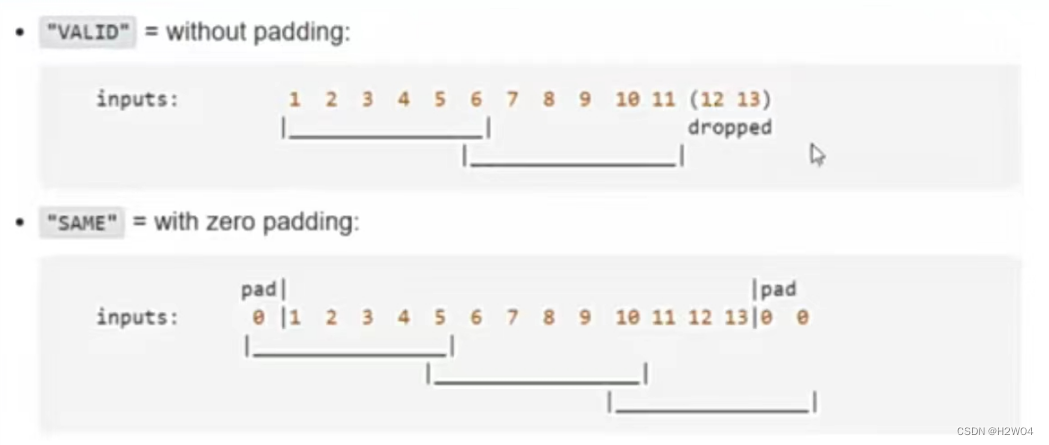 如果想尽量避免出现扫描不完全的情况,可以进行如下设置:
如果想尽量避免出现扫描不完全的情况,可以进行如下设置:
- 卷积核尺寸控制在5*5以下,并且设置kernel_size>stride
- 令2*padding>stride
常用stride=3,padding=1
卷积操作后特征图的尺寸:
输出特征图的高/宽=(输入特征图的高/宽+2*padding-kernel_size)/stride+1
池化层
不会改变通道数目,只会改变特征图的大小,常跟在卷积层后实现降维。常见最大池化和平均池化
池化层只有尺寸没有值,步长默认等于核尺寸,以此保证扫描特征图时不出现重叠。如果需要也可以设置步长与核尺寸不相等,即重叠池化(overlapping pooling),但不是很常用。
Pytorch中可以给定需要的输出特征图的尺寸来自动设置池化层
from torch import nn
pool = nn.AdaptiveAvgPool2d(output_size=(3,7))
# 让最后输出的特征图尺寸是3*7池化层的特点:
- 对数据进行非线性变换,为模型带来一些活力
- 有一定的平移不变性(神经网络对物体在图像哪个位置不敏感)
- 池化层不涉及需要学习的参数,不会增加参数量。但是池化层不会随着算法一起进步
- 对所有的特征图用同一个规则进行降维,可能会引起大规模的信息损失
Dropout与BN
Dropout与BN是神经网络中非常经典的用于控制过拟合,提升模型泛化能力的技巧。
Dropout:进行训练时,当整体神经元个数为N时,随机挑选p*N个神经元关闭,将其权重设为0,可以减弱全体神经元之间的联合适应性。p一般设置在0.2~0.5。在进行测试时,dropout会对所有神经元上的系数都乘以概率p,以模拟在训练中这些神经元只有p的概率呗用于向前传播的状况。
Dropout2d会以p的概率直接沉默整个通道。
复现经典网络:LeNet5与AlexNet
现代CNN的奠基者:LeNet5
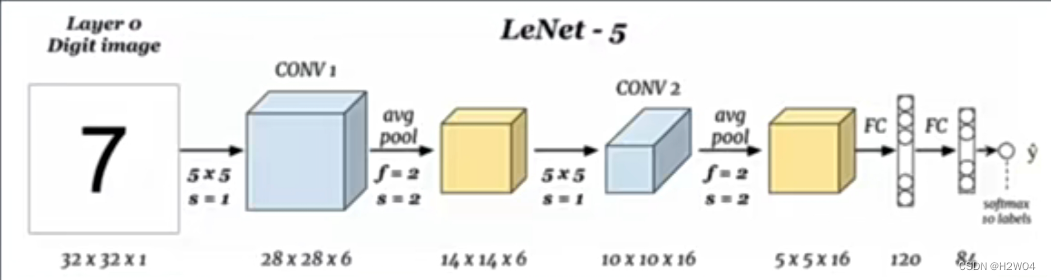
每个卷积层和全连接层后都使用了激活函数tanh或sigmoid(图中未标出)
Pytorch实现
导库
import torch
from torch import nn
from torch.nn import functional as F设置神经网络架构
data=torch.ones(size=(10,1,32,32))
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1=nn.Conv2d(1,6,5)
self.pool1=nn.AvgPool2d(2)
self.conv2=nn.Conv2d(6,16,5)
self.pool2=nn.AvgPool2d(2)
self.fc1=nn.Linear(5*5*16,120) # 线性层
self.fc2=nn.Linear(120,84)
def forward(self,x):
x=F.tanh(self.conv1(x))
x=self.pool1(x)
x=F.tanh(self.conv2(x))
x=self.pool2(x)
x=x.view(-1,5*5*16) # 将要输入全连接层,将数据拉平
x=F.tanh(self.fc1(x))
output=F.softmax(self.fc2(x),dim=1)使用torchinfo中的summary函数来查看网络架构
from torchinfo import summary
net=Model()
summary(net,input_size=(10,1,32,32))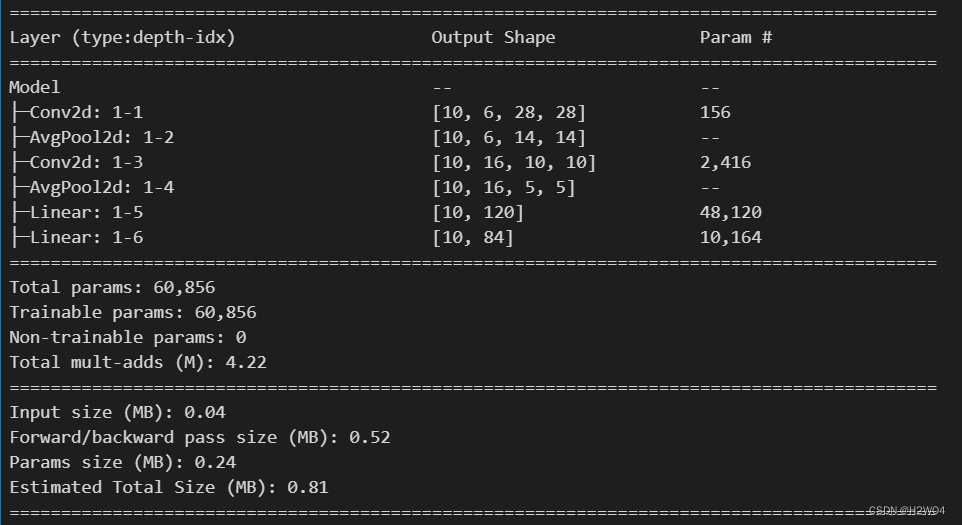
从浅层到深层:AlexNet
网络架构为:(卷积+池化)+(卷积+池化)+(卷积*3+池化)+线性层*3

在全连接层中使用了dropout层
使用更大的步长,尽快将特征量缩小。为了避免特征的损失,增大通道数量
在网络中间让特征量缩小的速度减慢,使得网络层次更深,以期待挖掘更多信息
代码如下
data=torch.ones(size=(10,3,227,227))
class Model(nn.Module):
def __init__(self):
super().__init__()
# 为了处理尺寸较大的原始图片,使用11*11的卷积核和较大的步长来快速降低特征图的尺寸
# 同时,使用较多通道数来弥补降低特征图尺寸造成的数据损失
self.conv1=nn.Conv2d(3,96,kernel_size=11,stride=4)
self.pool1=nn.MaxPool2d(kernel_size=3,stride=2) # overlap pooling
# 填充使得特征图的大小没有减小
self.conv2=nn.Conv2d(96,256,kernel_size=5,padding=2)
self.pool2=nn.MaxPool2d(kernel_size=3,stride=2)
# 连续使用卷积层疯狂提取特征
self.conv3=nn.Conv2d(256,384,kernel_size=3,padding=1)
self.conv4=nn.Conv2d(384,384,kernel_size=3,padding=1)
self.conv5=nn.Conv2d(384,256,kernel_size=3,padding=1)
self.pool3=nn.MaxPool2d(kernel_size=3,stride=2)
# 进入全连接层进行信息汇总
self.fc1=nn.Linear(6*6*256,4096)
self.fc2=nn.Linear(4096,4096)
self.fc3=nn.Linear(4096,1000)
def forward(self,x):
x=F.relu(self.conv1(x))
x=self.pool1(x)
x=F.relu(self.conv2(x))
x=self.pool2(x)
x=F.relu(self.conv3(x))
x=F.relu(self.conv4(x))
x=F.relu(self.conv5(x))
x=self.pool3(x)
x=x.view(-1,6*6*256) # 将要输入全连接层,将数据拉平
x=F.dropout(x,p=0.5) # 在池化和第一个线性层之间dropout
x=F.relu(F.dropout(self.fc1(x),p=0.5))
x=F.relu(self.fc2(x))
output=F.softmax(self.fc3(x),dim=1)使用torchinfo中的summary函数查看网络架构
from torchinfo import summary
net=Model()
summary(net,input_size=(10,3,227,227))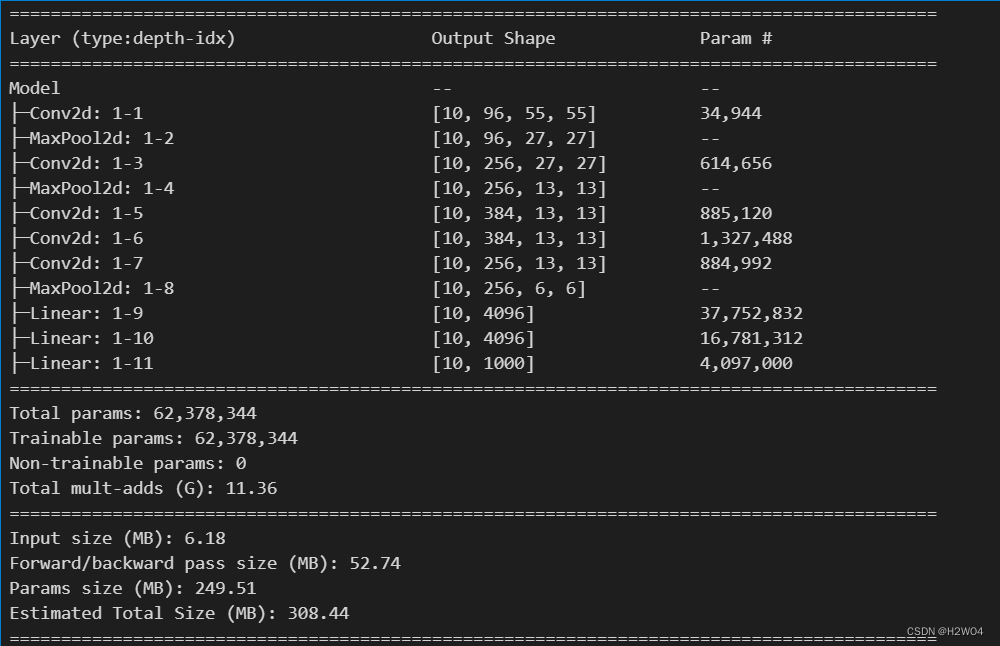















 992
992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









