







yolov3_tiny模型转换与开发板上进行推理
承接前面的环境配置,今天将一个在开发板上已经部署的比较成功的yolov3_tiny模型给分享出来,主要介绍部署的过程和对实际推理效果进行展示,由于目前在对其他模型进行转换部署时,遇到了诸多问题,所以希望同有对RK3399开发需求的朋友们也多留下些自己的开发心得,大家能相互讨论和学习下。
一、yolov3_tiny原理简介
1.结构展示
网上有关yolo系列原理详解的文章数不胜数,其中许多都讲解的比较清晰易懂,所以这里就不在进行详细的叙述,大家可以去查看一些相关的比较优秀的博文学习一下,借鉴下其设计思路,下面主要针对其模型在进行推理时的数据处理过程进行简单介绍。
 yolov3-tiny相较于yolov3最主要的特点便是速度,所以在开发速度要求比较高的项目时,yolov3_tiny才是首选,其就是在yolov3的基础上去掉了一些特征层,只保留了2个独立的预测分支,分别对应大目标和中目标检测。由于项目中在运用时只需对一类目标进行检测,所以在对网络结构进行简单修改后,2个分支的输出尺寸分别是:13x13x(1+5)x3和26x26x(1+5)x3
yolov3-tiny相较于yolov3最主要的特点便是速度,所以在开发速度要求比较高的项目时,yolov3_tiny才是首选,其就是在yolov3的基础上去掉了一些特征层,只保留了2个独立的预测分支,分别对应大目标和中目标检测。由于项目中在运用时只需对一类目标进行检测,所以在对网络结构进行简单修改后,2个分支的输出尺寸分别是:13x13x(1+5)x3和26x26x(1+5)x3
2.输出数据后处理过程
(1)对数空间变换

看完公式便一目了然,其中的激活函数为sigmoid函数,在获得其置信度和类别时,同样也是有sigmod函数解码即可,tx, ty, tw, th为模型输出,cx, cy是物体中心所在格子索引,pw, ph为对应anchors box的宽高,具体看下图的展示可能会更清楚些。

(2)阈值过滤
阈值过滤的作用是选取一个置信度阈值,过滤掉低阈值的box。此部分涉及到一个阈值参数,可在代码中进行调节。
(3)非极大值抑制(NMS)
NMS主要解决同一图像的多重检测问题,里面一个重要的概念就是IoU,即交并比,原理上很容易理解,如下图:
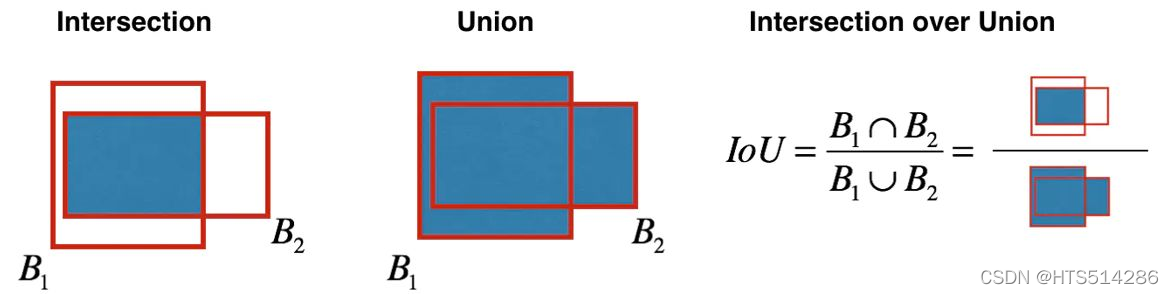
具体算法原理为:选择一个最高分数的框;计算它和其他框的重合度,去除重合度超过IoU阈值的框;回到步骤1迭代直到没有比当前所选框低的框。在一篇官方的博文中发现了一个比较清晰的算法举例,在这里可以给大家分享下。
A、B、C、D、E、F
…从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
…假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的
…从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈 值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。

二、算法部署
1.模型转换
这里我个人尝试过用训练后生成的.pth文件直接进行转换,实际效果不是很好,并且会报错,对应的API为rknn.load_pytorch,官方文档中的函数注释为:

各项参数都介绍的比较清楚,但实际运用时,效果不是很好,可能是API设计时优化的问题,反正个人感觉rknn.load_pytorch很不好用,包括用在其他.pth模型转换时,总是会报错。其实现原理应该是.pth->onnx->rknn。
由于效果不太好,所以最后还是直接选用了darknet专用的API,为rknn.load_darknet:

rknn_transform.py
from rknn.api import RKNN
import torch
import cv2
import numpy as np
class Rknn_transform():
"""
实现onnx,pytorch,tensorflow,darknet模型向RKNN模型的转换
"""
def __init__(self):
super(Rknn_transform, self).__init__()
self.rknn = RKNN()
def pth_to_onnx(self, torch_net, input_list, Output_path):
"""
实现pytorch模型向onnx模型的转换
Args:
torch_net: 一个定义完成的pytorch网络
input_list: 随机输入一个符合网络输入格式的数据
weights_file:
Returns: onnx格式的模型文件
"""
if not Output_path.endswith('.onnx'):
print('Warning! The onnx model name is not correct,\
please give a name that ends with \'.onnx\'!')
return 0
torch.onnx.export(torch_net, input_list, Output_path, verbose=True) # 指定模型的输入,以及onnx的输出路径
print("Exporting .pth model to onnx model has been successful!")
def pth_to_pt(self, torch_net, Input_list, Output_path):
"""
实现.pth文件向脚本文件.pt的转换,以便在C++环境下运行
:param torch_net: 一个定义完成的pytorch网络
:param Input_list: 随机输入一个符合网络输入格式的数据 例:torch.Tensor(1, 3, 224, 160)
:param Output_path:
:return:
"""
trace_model = torch.jit.trace(torch_net, Input_list)
trace_model.save(Output_path)
def onnx_to_rknn(self, channel_mean_value, Ionnx_path, Orknn_path):
"""
onnx exchange to rknn
Args:
channel_mean_value: 前三个为通道各数据所要减去的值,最后一位为减去后要除以的值 例: '123.675 116.28 103.53 58.395'
dataset: test file path
Ionnx_path: input of onnx model path
Orknn_path: output of rknn model path
Returns:
None
"""
# pre-process config
print('--> config model')
self.rknn.config(channel_mean_value=channel_mean_value, reorder_channel='0 1 2')
print('config done')
# Load onnx model
print('--> Loading model')
ret = self.rknn.load_onnx(model=Ionnx_path)
if ret != 0:
print('Load onnx model failed!')
exit(ret)
print('Load onnx done')
# Build model
print('--> Building model')
ret = self.rknn.build(do_quantization=False)
if ret != 0:
print('Build onnx failed!')
exit(ret)
print('Build onnx done')
# Export rknn model
print('--> Export RKNN model')
ret = self.rknn.export_rknn(Orknn_path)
if ret != 0:
print('Export onnx_rknn failed!')
exit(ret)
print('Export onnx_rknn done')
# def pt_to_rknn(self, mean_values, std_values, input_list, Ipt_path, Orknn_path):
def pt_to_rknn(self, input_list, Ipt_path, Orknn_path):
"""
.pt file convert to .rknn file
Args:
mean_values: 前三个为通道各数据所要减去的值,最后一位为减去后要除以的值 例: '123.675 116.28 103.53 58.395'
std_values:
dataset: test file path
input_list: input data format
Ipth_path: input of torch model path
Opt_path: output of .pt file path
Orknn_path: output of rknn model path
Returns:
None
"""
# pre-process config
print('--> config model')
self.rknn.config(reorder_channel='0 1 2')
print('config done')
# Load pytorch model
print('--> Loading model')
ret = self.rknn.load_pytorch(model=Ipt_path, input_size_list=input_list)
if ret != 0:
print('Load pytorch model failed!')
exit(ret)
print('Load pytorch done')
# Build model
print('--> Building model')
ret = self.rknn.build(do_quantization=False)
if ret != 0:
print('Build pytorch failed!')
exit(ret)
print('Build pytorch done')
# Export rknn model
print('--> Export RKNN model')
ret = self.rknn.export_rknn(Orknn_path)
if ret != 0:
print('Export pt_to_rknn failed!')
exit(ret)
print('Export pt_to_rknn done')
def dark_to_rknn(self, dataset, cfg_file, weight_file, Orknn_path):
"""
yolo convert to .rknn file
Args:
dataset: test file path
cfg_file:
weight_file:
Orknn_path: output of rknn model path
Returns: None
"""
# pre-process config
print('--> config model')
self.rknn.config(channel_mean_value='0 0 0 255', reorder_channel='0 1 2')
print('config done')
# Load darknet model
print('--> Loading model')
ret = self.rknn.load_darknet(model=cfg_file, weight=weight_file)
if ret != 0:
print('Load darknet model failed!')
exit(ret)
print('Load darknet done')
# Build model
print('--> Building model')
ret = self.rknn.build(do_quantization=True, dataset=dataset)
if ret != 0:
print('Build darknet failed!')
exit(ret)
print('Build darknet done')
# Export rknn model
print('--> Export RKNN model')
ret = self.rknn.export_rknn(Orknn_path)
if ret != 0:
print('Export dark_to_rknn failed!')
exit(ret)
print('Export dark_to_rknn done')
转换时类的实例调用:
yolov3_cfg = './yolov3_tiny_file/yolov3-tiny-onecls.cfg'
yolov3_weight = "./yolov3_tiny_file/yolov3_tiny_onecls.weights"
dataset = './yolov3_tiny_file/dateset'
rknn_yolov3 = './yolov3_tiny_file/yolov3_tiny_onecls.rknn'
rknn = Rknn_transform()
rknn.dark_to_rknn(dataset, yolov3_cfg, yolov3_weight, rknn_yolov3)
2.模型推理
代码是打算分层设计,因此单独定义一个能接触到最底层的,用于rknn初始化和加载以及推理的rknn模型的类:rknn_run.py
from rknn.api import RKNN
import torch
import cv2
import numpy as np
from rknn_transform import Rknn_transform
class Rknn_run(Rknn_transform):
"""
加载模型,预测模型,NPU初始化
"""
def __init__(self):
super(Rknn_transform, self).__init__()
def load_model(self, RKNN_MODEL_PATH):
"""
Load the converted rknn model.
# Argument:
Crknn: rknn class
RKNN_MODEL_PATH: The path where the rknn model is located.
"""
# Direct load rknn model
print('Loading RKNN model')
ret = self.rknn.load_rknn(RKNN_MODEL_PATH)
if ret != 0:
print('load rknn model failed.')
exit(ret)
print('load rknn model done')
print('init runtime')
# ret = rknn.init_runtime()
ret = self.rknn.init_runtime()
if ret != 0:
print('init runtime failed.')
exit(ret)
print('init runtime done')
def predict(self, input_data):
print('Inference model')
output = self.rknn.inference(inputs=input_data)
print('Inference done')
return output
面向对象定义各种具体算法模型的类,本文只限于yolov3_tiny,后续是可以扩展的,类似yolov5这种:rknn_model.py
from rknn.api import RKNN
import torch
import cv2
import numpy as np
from rknn_run import Rknn_run
class Yolov3_tiny(Rknn_run):
"""
rknn中的yolov3_tiny类
"""
def __init__(self, rknn_path):
super(Rknn_run, self).__init__()
self.masks = [[3, 4, 5], [0, 1, 2]]
self.anchors = [[10, 14], [23, 27], [37, 58], [81, 82], [135, 169], [344, 319]]
self.CLASSES = ( "person", "bicycle", "car", "motorbike ", "aeroplane ", "bus ", "train", "truck ", "boat", "traffic light",
"fire hydrant", "stop sign ", "parking meter", "bench", "bird", "cat", "dog ", "horse ", "sheep", "cow","elephant",
"bear", "zebra ", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis","snowboard", "sports ball", "kite",
"baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup","fork", "knife ",
"spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza ", "donut","cake", "chair", "sofa",
"pottedplant", "bed", "diningtable", "toilet ", "tvmonitor", "laptop ", "mouse ", "remote ", "keyboard ","cell phone", "microwave ",
"oven ", "toaster", "sink", "refrigerator ", "book", "clock", "vase", "scissors ", "teddy bear ", "hair drier","toothbrush ")
self.OBJ_THRESH = 0.4
self.NMS_THRESH = 0.25
self.GRID0 = 13
self.GRID1 = 26
self.LISTSIZE = 6
self.SPAN = 3
self.NUM_CLS = 80
self.MAX_BOXES = 500
self.model = Rknn_run.load_model(self, RKNN_MODEL_PATH=rknn_path)
print("load yolo finished")
def sigmoid(self, x):
return 1 / (1 + np.exp(-x))
def process(self, input, mask, anchors):
anchors = [anchors[i] for i in mask]
grid_h, grid_w = map(int, input.shape[0:2])
box_confidence = self.sigmoid(input[..., 4])
box_confidence = np.expand_dims(box_confidence, axis=-1)
box_class_probs = self.sigmoid(input[..., 5:])
box_xy = self.sigmoid(input[..., :2])
box_wh = np.exp(input[..., 2:4])
box_wh = box_wh * anchors
col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w)
row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h)
col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
grid = np.concatenate((col, row), axis=-1)
box_xy += grid
box_xy /= (grid_w, grid_h)
box_wh /= (416, 416)
box_xy -= (box_wh / 2.)
box = np.concatenate((box_xy, box_wh), axis=-1)
return box, box_confidence, box_class_probs
def filter_boxes(self, boxes, box_confidences, box_class_probs):
"""Filter boxes with object threshold.
# Arguments
boxes: ndarray, boxes of objects.
box_confidences: ndarray, confidences of objects.
box_class_probs: ndarray, class_probs of objects.
# Returns
boxes: ndarray, filtered boxes.
classes: ndarray, classes for boxes.
scores: ndarray, scores for boxes.
"""
box_scores = box_confidences * box_class_probs
box_classes = np.argmax(box_scores, axis=-1)
box_class_scores = np.max(box_scores, axis=-1)
pos = np.where(box_class_scores >= self.OBJ_THRESH)
boxes = boxes[pos]
classes = box_classes[pos]
scores = box_class_scores[pos]
return boxes, classes, scores
def nms_boxes(self, boxes, scores):
"""Suppress non-maximal boxes.
# Arguments
boxes: ndarray, boxes of objects.
scores: ndarray, scores of objects.
# Returns
keep: ndarray, index of effective boxes.
"""
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2]
h = boxes[:, 3]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= self.NMS_THRESH)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def draw(self, image, boxes, scores, classes):
"""Draw the boxes on the image.
# Argument:
image: original image.
boxes: ndarray, boxes of objects.
classes: ndarray, classes of objects.
scores: ndarray, scores of objects.
all_classes: all classes name.
"""
for box, score, cl in zip(boxes, scores, classes):
x, y, w, h = box
# print('******score********')
# print(score)
# print('******score********')
# print('class: {}, score: {}'.format(CLASSES[cl], score))
# print('box coordinate left,top,right,down: [{}, {}, {}, {}]'.format(x, y, x+w, y+h))
x *= image.shape[1]
y *= image.shape[0]
w *= image.shape[1]
h *= image.shape[0]
top = max(0, np.floor(x - 20).astype(int))
left = max(0, np.floor(y - 20).astype(int))
right = min(image.shape[1], np.floor(x + w + 20).astype(int))
bottom = min(image.shape[0], np.floor(y + h + 20).astype(int))
cv2.rectangle(image, (top, left), (right, bottom), (255, 0, 0), 1)
cv2.putText(image, "{0} {1:.2f}".format(self.CLASSES[cl], score),
(top, left - 6),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 1)
def Oinferent(self, inputdata):
out_boxes1, out_boxes2 = Rknn_run.predict(self, inputdata)
out_boxes1 = out_boxes1.reshape(self.SPAN, self.LISTSIZE, self.GRID0, self.GRID0)
out_boxes2 = out_boxes2.reshape(self.SPAN, self.LISTSIZE, self.GRID1, self.GRID1)
input_data = []
input_data.append(np.transpose(out_boxes1, (2, 3, 0, 1)))
input_data.append(np.transpose(out_boxes2, (2, 3, 0, 1)))
boxes, classes, scores = [], [], []
for input, mask in zip(input_data, self.masks):
b, c, s = self.process(input, mask, self.anchors)
b, c, s = self.filter_boxes(b, c, s)
boxes.append(b)
classes.append(c)
scores.append(s)
boxes = np.concatenate(boxes)
classes = np.concatenate(classes)
scores = np.concatenate(scores)
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b = boxes[inds]
c = classes[inds]
s = scores[inds]
keep = self.nms_boxes(b, s)
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if not nclasses and not nscores:
return None, None, None
boxes = np.concatenate(nboxes)
classes = np.concatenate(nclasses)
scores = np.concatenate(nscores)
return boxes, classes, scores
通过前面一直面向对象的设计,主函数只是涉及到一些类的实例化调用和视频以及图片的读取,这也是面向对象代码设计的好处,主函数文件为:rknn_camara.py
from PIL import Image
import numpy as np
from numpy.ma.bench import timer
from threading import Timer
import cv2
from rknn.api import RKNN
from rknn_model import Yolov3_tiny
from rknn_transform import Rknn_transform
video_path = "./video_data/video_(1).avi"
if __name__ == '__main__':
# yolov3_cfg = './yolov3_tiny_file/yolov3-tiny-onecls.cfg'
# yolov3_weight = "./yolov3_tiny_file/yolov3_tiny_onecls.weights"
# dataset = './yolov3_tiny_file/dateset'
# rknn_yolov3 = './yolov3_tiny_file/yolov3_tiny_onecls.rknn'
#
# rknn = Rknn_transform()
#
# rknn.dark_to_rknn(dataset, yolov3_cfg, yolov3_weight, rknn_yolov3)
# rknn model path
rknn_yolov3 = './yolov3_tiny_file/yolov3_tiny_onecls.rknn'
yolo_net = Yolov3_tiny(rknn_yolov3)
font = cv2.FONT_HERSHEY_SIMPLEX
capture = cv2.VideoCapture(video_path)
# capture = cv2.VideoCapture(0)
accum_time = 0
curr_fps = 0
# prev_time = timer()
fps = "FPS: ??"
ret = True
try:
while (ret):
ret, frame = capture.read()
print('ret', ret)
if ret == True:
image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (416, 416)) # 修改为自己的尺寸
boxes, classes, scores = yolo_net.Oinferent([image])
if boxes is not None:
yolo_net.draw(frame, boxes, scores, classes)
curr_fps += 1
a = 1.0 / (time.time() - curr_fps)
a = round(a ,2)
fps = "FPS: " + str(a)
curr_fps = time.time()
if accum_time > 1:
accum_time -= 1
fps = "FPS: " + str(curr_fps)
curr_fps = 0
cv2.putText(frame, text=fps, org=(3, 15), fontFace=cv2.FONT_HERSHEY_SIMPLEX,fontScale=0.50, color=(255, 0, 0), thickness=2)
cv2.imshow("results", frame)
c = cv2.waitKey(5) & 0xff
if c == 27:
cv2.destroyAllWindows()
capture.release()
break
except KeyboardInterrupt:
cv2.destroyAllWindows()
capture.release()
yolo_net.rknn.release()
三、运行效果
1.运行环境依赖
# 这里偷个懒,直接给出pip list结果
Package Version
---------------------- ---------------
absl-py 1.0.0
astor 0.8.1
attrs 21.4.0
cachetools 4.2.4
certifi 2021.10.8
chardet 3.0.4
click 8.0.4
cycler 0.11.0
decorator 5.1.1
dill 0.2.8.2
Flask 1.0.2
flatbuffers 1.10
fonttools 4.31.2
future 0.18.2
gast 0.2.2
google-auth 1.35.0
google-auth-oauthlib 0.4.6
google-pasta 0.2.0
grpcio 1.36.1
h5py 2.8.0
idna 2.8
importlib-metadata 4.11.3
itsdangerous 2.1.1
Jinja2 3.0.3
Keras-Applications 1.0.8
Keras-Preprocessing 1.1.2
kiwisolver 1.4.0
lmdb 0.93
Markdown 3.3.6
MarkupSafe 2.1.1
matplotlib 3.5.1
networkx 1.11
numpy 1.16.3
oauthlib 3.2.0
onnx 1.6.0
onnx-tf 1.2.1
opencv-contrib-python 3.4.17.63
opencv-python-headless 4.3.0.38
opt-einsum 3.3.0
packaging 21.3
Pillow 9.0.1
pip 22.0.4
pkg_resources 0.0.0
ply 3.11
protobuf 3.19.4
psutil 5.6.2
pyasn1 0.4.8
pyasn1-modules 0.2.8
pyparsing 3.0.7
python-dateutil 2.8.2
PyYAML 6.0
requests 2.22.0
requests-oauthlib 1.3.1
rknn-toolkit 1.6.0
rsa 4.8
ruamel.yaml 0.15.81
scipy 1.5.4
setuptools 60.10.0
six 1.16.0
tensorboard 2.0.2
tensorflow 2.0.0
tensorflow-estimator 2.0.1
termcolor 1.1.0
torch 1.5.0a0+923085e
torchvision 0.6.0a0+fe36f06
typing_extensions 4.1.1
urllib3 1.25.11
Werkzeug 2.0.3
wheel 0.37.1
wrapt 1.14.0
zipp 3.7.0
2.运行
在命令行下调出自己创建的环境,主要参考前面文章中提到的virtualenv软件操作,当然安装conda都是可以的:
source venv/bin/activate # 即activate文件所在的文件路径
cd xxx # 工程文件所在路径
python rknn_camera.py
3.运行结果
1080P视频跑5帧左右,可自行测试。
四、总结
本文主要进行了yolov3_tiny在3399Pro上的部署,运行效果还算可以,但在后面进行openpose等模型转换部署的时候,在不进行量化的前提下,推理生成的数据,数据格式(指shape)虽然是正确的,但经过ndarray list转tensor后的数据与GPU处理后的数据相差太多,所以导致后续的数据处理步骤无法进行。个人感觉既然已经不经过量化,那么数据精度应该不会再丢失太多,但实际效果并非如此,所以现在也一直在寻找解决方案,希望有相关开发经验的人能多出些完整文章,大家相互学习下。最后附上工程的百度网盘链接:https://pan.baidu.com/s/1fEAP1XorNum6mBHWnkAWVA 提取码:q512
五、参考文献
https://zhuanlan.zhihu.com/p/345073218
https://blog.csdn.net/SMF0504/article/details/108645100














 4570
4570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









