






这两年的时间里,AI界的进展主要集中在AIGC领域,AIGC就是人工智能生成内容(Artificial Intelligence Generative Content),也就是用自然语言让AI帮你创作各种各样的内容,比如图片、视频、音乐、文字等等。而创造这些内容的主要是XLM,包括LLM(Large Language Model,超参数数量 ≥ 7B的语言模型), SLM(Small Language Model,超参数数量 < 7B的语言模型),两个VLM(Vision-Language Model, 视觉语言模量模型 和 Video-LanguageModel, 视频语言模型),MLLM(Multimodal Large Language Model, 多模态大语言模)。还有一些生成图像和视频的扩散视频(Diffusion Model)。

截止目前,AIGC领域大半壁江山还是文字类通用模型的。通用模型最擅长的是文字创作,其中最擅长的细分领域是(1)各种语言之间的翻译,(2)各种长篇大论的机器阅读并总结,(3)各种命题作文的撰写。
2024年9月OpenAI发布了o系列推理模型,拉开了业界文理分科的帷幕。推理模型擅长的创作领域是逻辑推理、数学、代码生成这些理工科的创作领域。
然后是图片,各种图片大模型大多可以实现文字生图和以图生图,主要的应用领域是logo设计,插画设计这种需要头脑风暴创意无限但精确度要求比较低的领域。
根据自然语言生成视频和音频的大模型也陆续有问世,性能也不断地提高,已经可以满足部分C端用户的需求,相信不久的将来也可以达到满足B端生产的性能。
----- 国外部分 -----
经过了两年的发展,国内外AI大模型的差距在不断缩小,但整体国外仍有一个身位的领先优势,尤其是通用模型,OpenAI,Google,Anthropic这三家公司除了性能交替领先,更重要的是行业趋势目前仍然一直由这几家公司把握。
国外的大模型大多数都需要架梯翻墙才能访问,而且由于生成的内容相对自由,国内企业使用起来可能会要注意合规风险。
闭源组
文字类(含多模态)
ChatGPT: https://chatgpt.com OpenAI研发的大模型系列。2025年2月推出最新的通用模型**GPT-4.5,2025年1月推出最新的推理模型Open AI o3-mini-high。**作为一直以来的龙头企业,今年O社头把交椅的地位有点动摇。
Claude: https://claude.ai/ Anthropic研发的大模型,卷上下文长度的开山怪,2025年2月发布了3.7 Sonnet,3月发布3.7 Sonnet Extended(推理模型)。目前Haiku版本仍是3.5,Opus版本仍是3.0,上下文长度均稳定为200K token。曾经有一小段时间在LMSYS Arena跑分占据过首位,但后续并不热衷于刷分,版本更新也比较佛系。目前它公认最强的领域是Coding。
Gemini(Bard): https://gemini.google.com google研发的大模型,前身为Bard。
12月发布了Gemini 2.0 Flash,1月发布推理模型2.0 Flash Thinking,这是一个All in one自带Agent架构的多模态模型,可以实时接收文字、语音、图像、视频信息并进行推理反馈。3月份发布了Gemin 2.5 Pro Experimental,默认采用thinking模式拥有地表最长上下文10M(2M稳定) token,相当于2小时视频、22小时音频、60,000行代码、1,400,000个单词。比较公认的强项是翻译和OCR。

Grok: https://grok.x.ai/ 一龙马斯克旗下的xAI研发的大模型,采用最新版本闭源早期版本开源的策略。2025年2月发布最新版本v3.0。早期版本登陆LMSYS的排名第一,xAI也已经跻身了大模型第一集团的行列,详见【LLM新品速递】Grok 3 Beta — 理性智能体的新纪元。其中v2.0版本已经开源。根据用户反馈,Grok生成硬件(如单片机)代码有独有的优势。
Mistral Large: https://mistral.ai/news/mistral-large-2407/ 法国Mistral AI发布的闭源大模型,2024年7月发布了v2.0,拥有128K 上下文,参数**123B,**详见《Large Enough》——Mistral Large 2简介。尽管作为欧洲独苗,MistralAI最近不太参与通用模型的竞争,专注于小模型和一些细分领域的小创新,但业内人士应该还记得Mixtral 8x7B发布时对行业的贡献。
图片类
DALL·E 3: https://openai.com/dall-e-3 OpenAI研发的AI图像生成器。
Imagen 3: https://deepmind.google/technologies/imagen-3/ Google Deepmind 2024年5月发布的AI图像生成模型。在LMSYS竞技场Image
Imagine with Meta AI: https://imagine.meta.com/ Meta研发的AI图像生成器,目前免费。
Midjourney: https://www.midjourney.com/ Midjourney研究实验室开发的人工智能程序,可以实现文字生图和图生图。2025年3月发布v7.0。和Stable Diffusion一起出道的生图元老,但是更新太过缓慢,听闻主程已离职,不知是否要退出历史年舞台了。
音乐类
Suno AI: https://suno.ai anthropic研发的音频大模型,可以根据prompt和歌词完成谱曲和编曲。2024年11月发布了v4.0。
音频类
Stable Audio: https://www.stableaudio.com/ Stablility AI发布的AI音频生成模型。
MuseNet: https://openai.com/research/musenet OpenAI研发的AI音频生成模型。
V2A: Generating audio for video - DeepMind Google Deepmind 2024年6月研发的音频生成大模型,可以根据源视频和文字prompt给源视频配上合适的BGM。详见Generating audio for video——Google V2A简介
视频类
Gen-4: https://app.runwayml.com/ Runway在2025年4月发布的AI视频生成模型,在3.0的基础上,大幅增强了角色、场景的一致性, 让生成视频可以支持更长的叙事,从前几代的创意玩具开始变得更接近可用的生产力工具。
Pika: https://www.pika.art/ Glen Pika在2023年11月发布的AI视频生成产品,支持文生视频、图生视频和视频生视频,2025年2月推出2.2版本,生成效果提升,加入了好玩但没啥实用性的Pikaafferts。
Luma: https://www.lumalabs.ai/dream-machine/ Luma Labs在2024年6月发布的视频生成产品,生成视频时长约5秒。2024年10月提升了生成速度至20秒以内
Stable Video Diffusion: https://stability.ai/stable-video Stablility AI发布的AI视频生成模型,以两个图像到视频模型的形式发布,能够以每秒 3 到 30 帧的可定制帧速率生成 14 帧和 25 帧,生成视频时长2-5秒。需下载代码布署本机使用,对电脑硬件配置有一定的要求。
Sora: https://openai.com/sora OpenAI在2024年12月发布的AI视频生成模型,plus会员可生成10秒时长的视频,pro会员可生成20秒。
Veo: https://deepmind.google/technologies/veo/ Google Deepmind在2024年5月发布的AI视频生成模型,时长可达1分钟。
Movie Gen Video: Meta AI 2024年10月发布的一个拥有30B参数量的transformer模型,可以通过单个文本prompt生成高质量、高分辨率的图像和视频。该模型能够根据生成或现有的视频以及文本指令进行精确的局部编辑,还能够通过一个人的图像和文本prompt生成视频,在人物特征保留和动作的自然表现方面都达到了最先进的水平。
开源组
语言类
Llama: https://llama.meta.com/llama3/ Meta研发的开源大模型,2025年4月发布了4.0版本,三个版本均为MoE架构,参数量分别为17B╳16(Scout)/17B╳128(Marverick)/288B╳16(Behemoth)。
Mistral: https://mistral.ai/ 法国的大模型初创企业MistralAI于2023年9月份发布的模型系列。2023年12月发布了Mixtral-of-Expert-7B,是一个拥有8个专家层的MoE模型,详见《Mixtral of Expert》精华摘译。2024年4月发布了Mixtral-of-Expert-22B。2024年11月发布了多模态大模型Pixtral Large,124B参数,支持128K上下文,具备前沿级图像理解能力,能理解文本、图表和图像。2025年3月发布Mistral Small 3.1,参数量24B。
Gemma: Gemma 3: Google’s new open model based on Gemini 2.0 Google Deepmind发布的开源小语言模型,2025年3月发布了3.0版本,包括1B, 4B, 12B和27B几个大小。详见【LLM技术报告】Gemma 3技术报告(全文)

Phi: Introducing Phi-4: Microsoft’s Newest Small Language Model Specializing in Complex Reasoning 微软发布的大语言模型,2024年12月发布了v4.0,截止目前只发布了14B参数的版本,虽然架构和phi-3类似但通过改进的数据质量、优化的训练课程以及创新的后期训练方案**,展现出相较其参数规模的卓越表现,详见《Phi-4技术报告》。
其v3.0版本于2024年4月发布版本,有 mini(3.8B)、small(7B)和 medium(14B)三个版本。其中Phi-3-mini在6月份进行了一次升级,加强上下文理解能力、指令遵循能力和推理能力**,基准测试平均分由之前的25.7提高至37.3。v3.5版本于2024年8月发布,包括Phi-3.5-mini-instruct(3.8B)、Phi-3.5-MoE-instruct(41.9B) 以及 Phi-3.5-vision-instruct(4.15B),详见《【LLM新品速递】微软发布Phi-3.5系列》 和《Phi-3 技术报告(全文)》 ;
DBRX: Introducing DBRX | Databricks Mosaic AI 2024年3月发布的开源大语言混合专家(MoE)模型,参数量为132B,每次输入激活的参数36B,拥有16个专家层每次激活4个。详见《Databricks发布开源MoE模型——DBRX(全文)》
Nemotron-4 340B: Nemotron-4 340B | Research Nvidia 2024年6月发布的开源大语言模型,参数量为340B,包含Nemotron-4-340B-Base, Nemotron-4-340B-Instruct 和 Nemotron-4-340B-Reward 三个版本。值得一提的是模型有**98%**的训练数据是合成数据,详见《Nvidia Nemotron-4-340B 技术报告》
图片类
Flux.1: https://github.com/black-forest-labs/flux 由Stable Diffusion的原班离职人马创立的Black Forrest Lab开发,和SD3一样对硬件的要求偏高。优势是开源后量化和LoRA比较方便,有探索精神的科研工作者可以实现一些大胆的想法。
Stable Diffusion: https://stability.ai/stable-diffusion/ 由CompVis、Stability AI 和 LAION 的研究人员创建文本到图像潜在扩散模型,需下载代码布署本机使用,对电脑硬件配置有一定的要求,目前更新到了3.5版本。
----- 国内部分 -----
国内的大语言模型一开始都是为了想在这个市场中分一杯羹赶鸭子上架陆续上线的,不过在经历了一年多的发展后,和国外领先团队的差距在缩小,尤其是在多模态和推理模型这两个细分领域大有赶超之势。
闭源组
综合类
深度求索:http://www.deepseek.com 幻方量化团队核心成员创立的AI大模型公司。目前语言模型为3.0版,推理模型为R1版本,拥有Web和APP端。服务能力普通,没有多余的应用生态,全凭模型实力出圈。
智谱清言:https://chatglm.cn/ 清华大学 KEG 实验室和智谱 AI 公司于2023年共同训练的语言模型,目前版本为4.0,支持文字聊天,图片。2024年7月更新加入了互联网搜索RAG功能。9月初向所有用户开放视频(实时多模态)聊天功能。模型性能和应用开发能力并存,综合实力较强。
字节豆包:https://www.doubao.com/ 字节跳动研发的大语言模型应用,目前2.0版本。2025年3月底上线了推理模型,独创边搜边想模式。比较擅长的领域是K12教育。
Kimi: https://kimi.moonshot.cn/ 月之暗面研发的大语言模型应用,最近上线了K1.6推理版。国内的长文档阅读之王。
通义千问:https://qianwen.aliyun.com/(国内版)https://chat.qwen.ai/(海外版) 阿里云研发的大语言模型应用,目前2.5版本,分为Turbo(长上下文)、Plus(处理复杂问题)、Max(最强)三个版本,2025年3月发布推理模型QwQ-Max和视觉推理模型QvQ-Max。模型能力挺强,但产品端略显傲慢。
腾讯元宝(混元):https://yuanbao.tencent.com/ 腾讯研发的大语言模型应用,前身为腾讯混元。2024年5月应用品牌升级为腾讯元宝,加入了微信公众号文章RAG搜索功能;2024年8月加入深度阅读功能。2025年2月接入DeepSeek-R1后,下载量飚升,目测自研模型Hunyuan系列的战略权重会下降。
**海螺AI:**https://hailuoai.com/ MiniMax研发的大语言模型应用,主打出海C端用户。
跃问:https://yuewen.cn/ 阶跃星辰研发的大语言模型应用,对应的语言模型为Step-2。
文心一言:https://yiyan.baidu.com/ 百度研发的国内首个大语言模型应用,2024年9月移动端APP品牌升级为“文小言”发力“新搜索”,目前最新版本4.5,2025年3月发布推理模型X1,所有版本(被逼)免费使用。起了个大早,赶了个晚集。目前在国内团队中也是全方位落后
百川智能:https://www.baichuan-ai.com/ 搜狗系研发的大语言模型应用,2024年5月发布4.0版本,应用品牌升级为百小应,加入联网搜索RAG功能。近一年了没有什么动静,存在感比较薄弱
万知:https://www.wanzhi.com/ 零一万物在2024年5月推出一站式AI工作平台,目前2.0版本。曾经也是AI明星企业,2025年初曝出停止预训练,后续发展存疑。
讯飞星火:https://xinghuo.xfyun.cn/ 科大讯飞研发的大语言模型应用。2025年3月发布推理模型X1(和百度撞衫了,不如趁着26个英文字母还没被抢注完改一下),在国内算是起步较早,而后劲有限。
视频类
快手可灵:https://kling.kuaishou.com/ 快手2024年6月发布的视频生成大模型,多次升级后目前已经能够支持文生视频、图生视频、首尾帧生成视频三种视频生成模式,默认生成视频时长10秒钟,支持扩展生成长达3分钟、30fps、1080p分辨率的超长视频,并支持多种宽高比。目前地表最强视频大模型。
像素跳动(生视频):https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo 字节豆包的视频生成模型,目前体验需要去以上地址申请。该模型能够理解和执行复杂的指令,实现多个主体间的交互,并能在视频主体的大动态和镜头间进行炫酷切换。此外,它还能够在多镜头切换中保持一致性,10秒内讲述一个完整的故事,并支持多种风格和比例,如黑白、3D动画、国画等。
海螺视频:https://hailuoai.com/video MiniMax推出的视频生成模型,海外用户反响不错。
智谱清影:https://chatglm.cn/video 智谱AI推出的视频生成模型,默认生成视频时长为6秒钟,支持视频风格、情感氛围、运镜方式这些进阶参数。
通义万相(生视频): https://tongyi.aliyun.com/wanxiang/videoCreation 阿里通义团队发布的视频生成模型产品,目前模型版本是2025年2月发布的v2.1。支持文生视频、图生视频、视频音效。
音乐类
Music-01: Music-01 - MiniMax Minimax在2024年8月推出的端到端音乐生成模型。可以自动学习样例的人声、伴奏的节奏和风格,再输入歌词,就可以得到一份自动生成、完整的音乐作品。目前版本可生成最长60秒的音乐。
音频类
海螺语音(Speech-01-HD): T2A-01-HD - MiniMax Minimax在2025年1月推出的文转语音模型,支持17个语种,可以通过最短6秒原声进行声音克隆。
图片类
快手可图:https://kolors.kuaishou.com/ 快手2024年6月发布的图像生成大模型,一期支持文生图,AI形象定制。
**像素跳动(生图):**https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenImage 字节豆包的图像生成模型,目前体验需要去以上地址申请。
通义万相(生图):https://tongyi.aliyun.com/wanxiang/creation 阿里通义团队发布的图像生成模型产品,目前模型版本是2025年2月发布的v2.1。支持多种图像生成模板,即将支持图生图。
开源组
综合类
DeepSeek: https://www.deepseek.com/ 深度求索团队开发的开源大模型,2024年12月发布了v3.0,详见【LLM技术报告】DeepSeek-V3技术报告(全文)。2025年1月发布了R1正式版,产品定位为对标OpenAI o1的理科状元。详见【LLM技术报告】DeepSeek-R1技术报告(全文)。
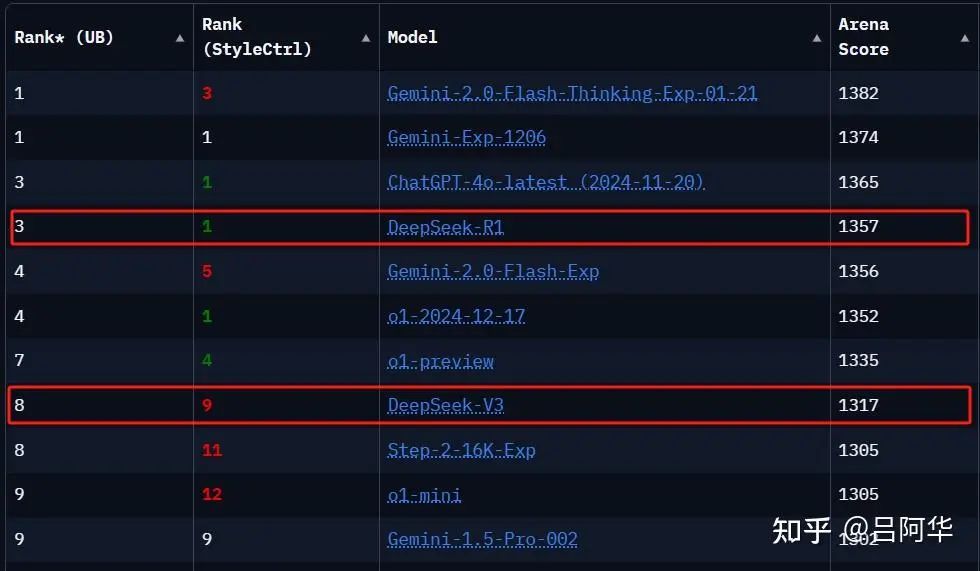
LMSYS竞技场总榜(2025/01/23快照)
Qwen: https://github.com/QwenLM/Qwen2.5 通义千问开源版本。2024年9月发布最新版本v2.5,参数数量在Qwen2 0.5B/1.5B/7B/57B(总参数量)-A14B(激活参数量)/72B 的基础上增加了14B和32B,同时发布了Qwen2.5-Coder和Qwen2.5-Math,11月发布了Qwen2.5-Turbo(上下文长度增加为1M token)。2025年3月发布QwQ-32B推理模型(《QwQ-32B: 领略强化学习之力》),多模态推理模型QvQ-Max(《QVQ-Max:有依据地思考》)以及All in one的多模态 模型Qwen2.5-Omini(《Qwen2.5-Omni Readme》)。Qwen2.5的介绍详见【LLM技术报告】Qwen2.5技术报告(全文),
GLM: https://github.com/THUDM/GLM-4 继2023年3月开源ChatGLM3-6B后,智谱团队于2024年6月开源GLM-4-9B。8月底发布4.0 plus系列,除了语言模型GLM-4-Plus还包括文生图模型CogView-3-Plus、图像/视频理解模型GLM-4V-Plus、视频生成模型 CogVideoX。
Hunyuan:https://llm.hunyuan.tencent.com/ 腾讯2024年11月发布开源MoE模型——Hunyuan-Large,该模型总参数量约389B,激活参数量约52B ,上下文长度达256k。详见【LLM技术报告】《Hunyuan-Large: 腾讯推出的拥有52B激活参数的开源MoE模型》。 2025年3月推出了推理模型Hunyuan-T1。
MiniMax:https://www.minimaxi.com/news/minimax-01 去年专注出海业务的MiniMax在2025年1月发布的开源语言模型MiniMax-Text-01,采用MoE架构,总参数量456B,激活参数45.9B,专家数量32个。同时发布视觉语言模型MiniMax-VL-01,详见【LLM技术报告】MiniMax-01技术报告(全文)
Yi:https://www.lingyiwanwu.com/ 李开复牵头搞的开源大模型,目前版本为v2.0,LMSYS排名不错,参数数量为6B/9B/34B,有基座版、Chat版和VL版。团队最近没有动作,谨慎选择。
视频类
Hunyuan Video:https://aivideo.hunyuan.tencent.com/ 腾讯发布的开源视频生成模型,超过13B参数,号称表现超越了之前的SOTA模型。详见《Hunyuan Video:用于大型视频生成模型的系统化框架》
Wan: https://github.com/Wan-Video/Wan2.1 阿里通义团队发布的开源视频生成模型,最新版是2025年2月发布的v2.1,有1.3B和14B两个版本,2月底在VBench获得SOTA考分。
原文链接:https://zhuanlan.zhihu.com/p/670574382
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









