






大家好,我是海文,AI洞察,AI智能体,AI工作流分享
大家应该在小红书都刷到过这样的爆款认知觉醒的视频吧?

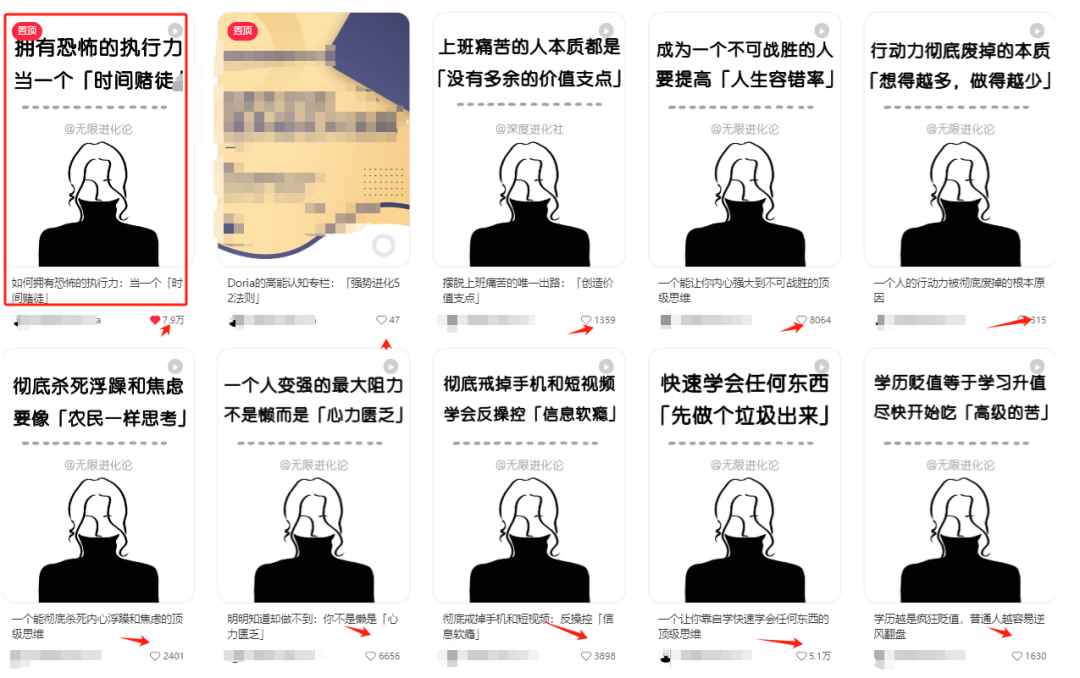
今天我就不和大家讲这次工作流的需求分析了,毕竟大家都知道这类爆款视频的变现方式,出书,教程,训练营等等,我就不多此一举了。
而是讲讲这类视频曾经给我带来的帮助。
这个账号的内容我是在去年十二月的时候刷到的,当时我刚开始做公众号,不会创作内容,也不会写作。
所以当时的我每天不知道写什么,每天就是啥火抄啥,偶尔还用 AI 糊弄一下大家。
但当时我刷到了这个博主的第一条视频时,我红色框出来的那条视频,当时这条视频给了我莫大的鼓励。
视频的大致内容说的是,只选一件事,然后下重注,押上自己所有时间,不顾一切的去做。
这条视频内容质量很好,我推荐各位可以看一看。
这个博主很厉害,当时不到一个月,涨了 10W 粉丝,也是看完它的那条视频那时起,我开始认真学习写作,开始看写作的课程,开始模仿写作的方式。
当时的我,因为没有钱报课程,只能去 PDD 上买 dao 版的来看,看了两遍,然后又看了本写作相关的书籍,并将方法用于实践,一段时间后,我的水平就上来了。
其实我想说,无论你现在在做什么,你都不要因为短期没有效果而陷入情绪内耗,从而开始有逃避的想法。
当你开始心无旁骛,专心致志的去做一件事情,你会发现,其实赛道一点也不拥挤,因为我相信你可以。
好了,励志篇幅不宜过长,开始我们今天的教学内容,跟我一起学下去吧!
工作流分析
整体的流程如下,一共六步。
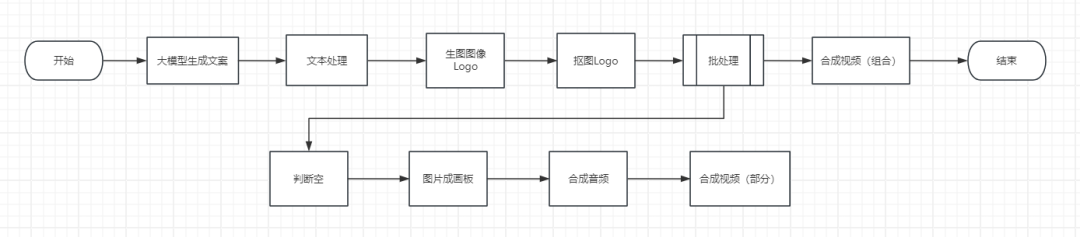
整体的 Coze 流程如下。
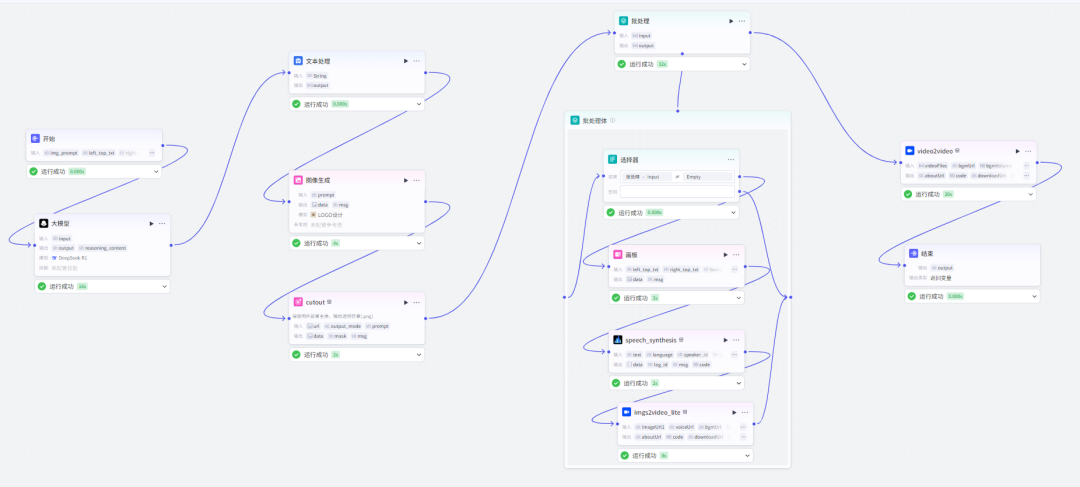
说实话,看着挺复杂的,其实也确实挺复杂的。
保姆级工作流教程,李奶奶不一定能学会
本次的教程说实话比较难,如果看不懂的话,就多看几次,或者你后台加我,找我给你看看。
第一步,开始节点
开始节点一共有四个参数,分别是 img_prompt , left_top_txt , right_top_txt , bottom_txt 。
以上这四个参数分别代表的意思为,视频内容主题(内容主题图像生成 logo 图片),视频左侧顶部文章,视频右侧顶部文字,视频底部文字。
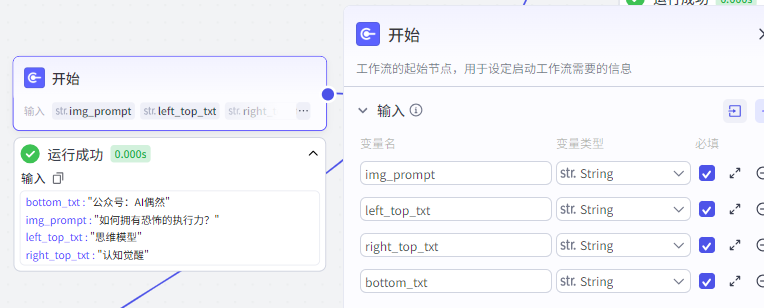
比如这几个参数我输入了以下这个值,那么获得的对应的视频如下,上下左右效果就是这样。
bottom_txt : “公众号:AI偶然”
img_prompt : “如何拥有恐怖的执行力?”
left_top_txt : “思维模型”
right_top_txt : “认知觉醒”

第二步,大模型生成文案节点
大模型选择 DeepSeek-R1 ,直接选择最好的,这样生成的相应主题文案看起来比较像人写的,毕竟 DeepSeek R1 是国产大模型,懂中国人。
它的输入值 input 来源为开始节点的 img_prompt 。
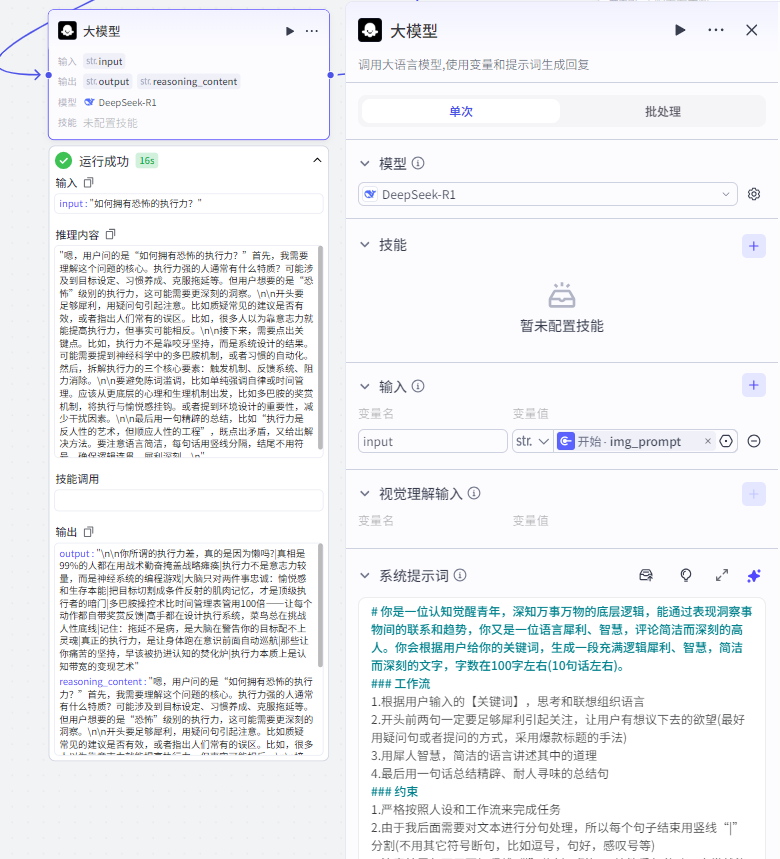
这个节点的提示词加我就给你,哈哈哈。
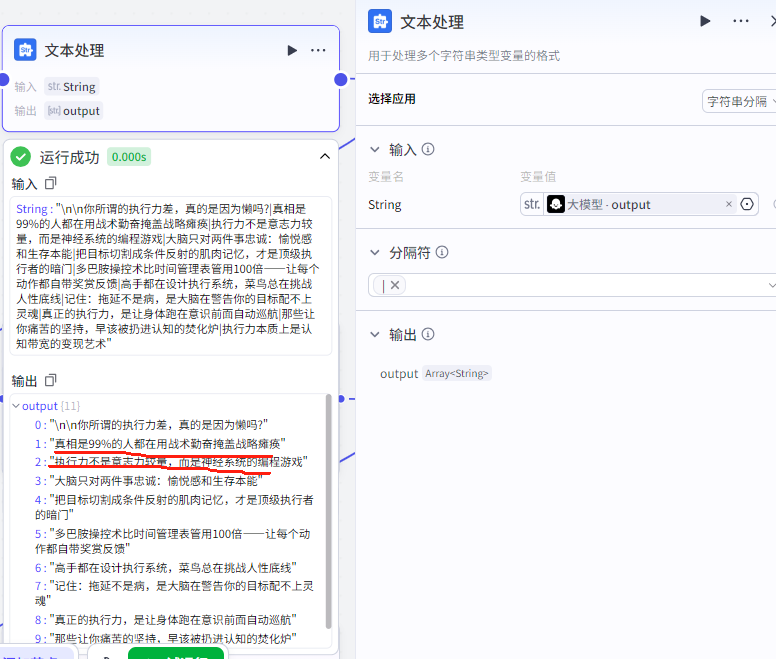
第三步,文本处理节点
这一步的作用主要是将大模型生成的文案进行分隔,这样的话在视频中看起来就是一句话一两秒这样。
它的输入值来源是大模型的 output ,分隔符为 | 。
第四步,图像生成节点
这个节点的作用,就是生成视频中间的那个图像 logo 的图片,它的变量名 prompt 数值来源于开始节点的 img_prompt 。
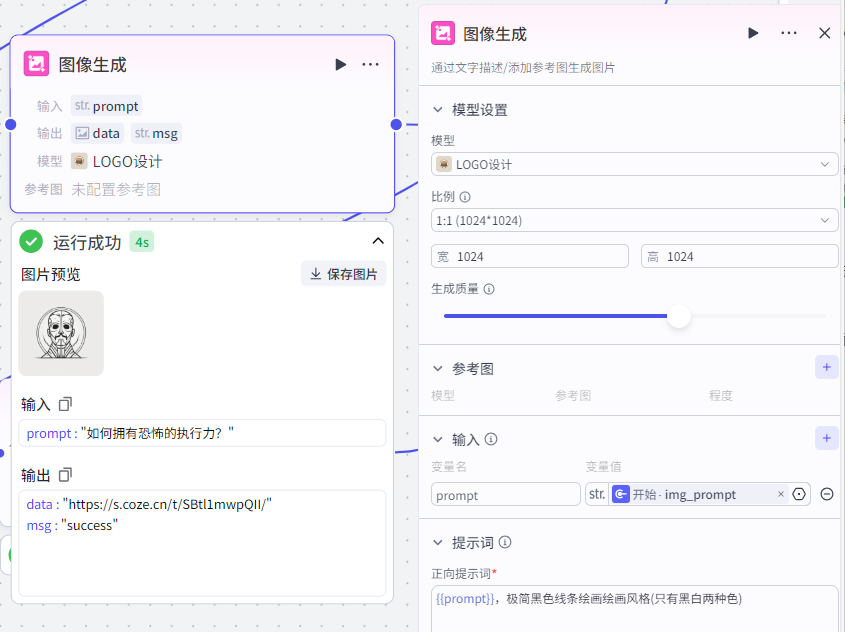
正向提示词
{{prompt}},极简黑色线条绘画绘画风格(只有黑白两种色)
第五步,抠图节点
这个抠图节点就是把上一个节点生成的完整图片,把里面的那个图像 logo 抠出来,它的数值来源就是图像生成节点的 data 。
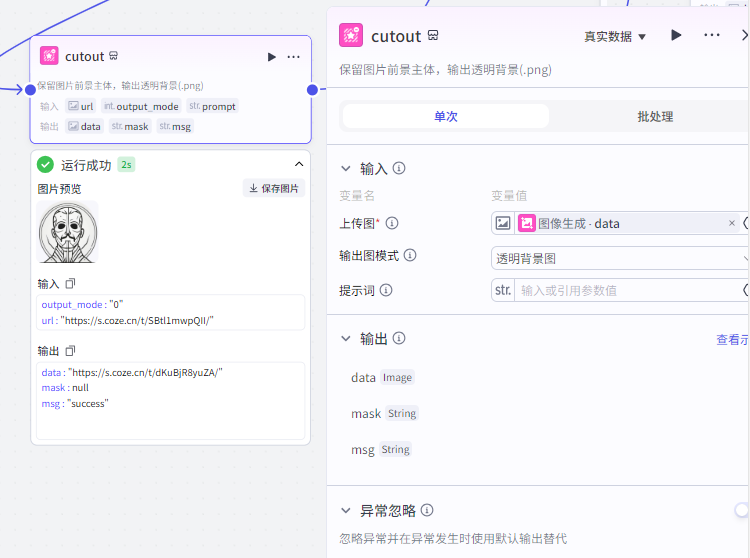
第六步,批处理节点。
这个节点的作用主要是将刚刚那些生成图片以及文案,变成一个个短视频,并且将这些短视频片段组装打包成一个短视频的数组,为下一步把这些短视频组装成一个完整的视频做准备。
注:数组你可以把它理解为超市门口那种储物柜的柜子,它的值就是每个格子,懂吧兄弟?
批处理(外部),外部的输入值为 input 变量值的来源为文本处理节点的 output ,输出值为 imgs2video_lite 节点的 [videoUrl]*n 。
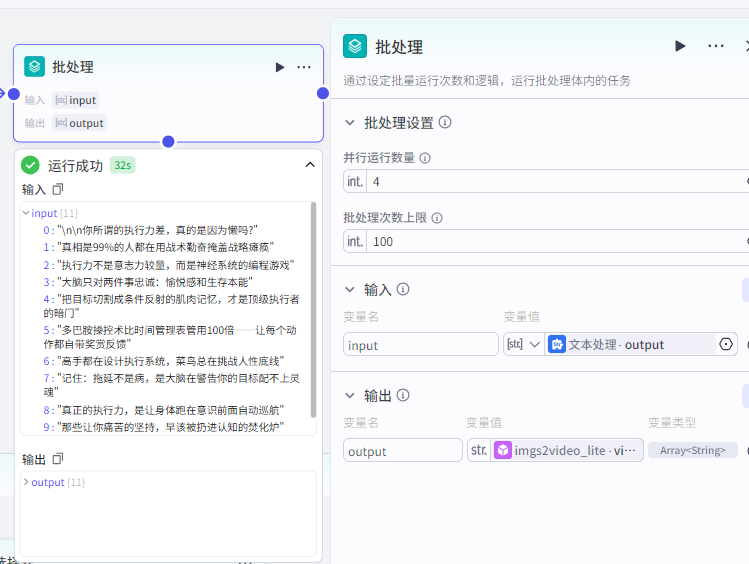
批处理(内部),内部有四个节点,分别是选择器(第一),画板(第二),音频(第三),视频(第四)。
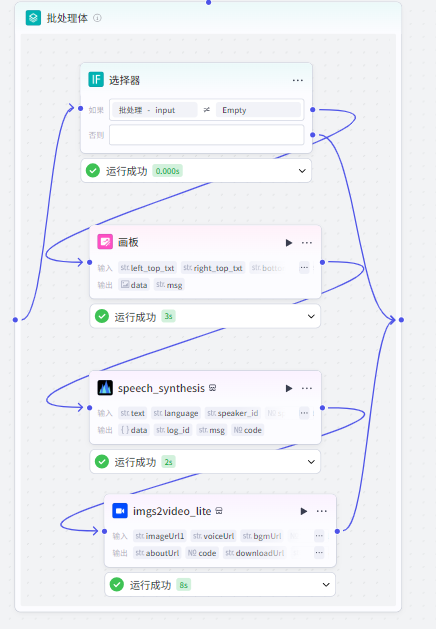
选择器节点(内部)
它的作用主要是用来过滤一些空数据以及作为终止条件,这里的空数据,意思就是那些没有内容的段落。
如果这个位置不进行空数据的判断的话,会在后面合成视频的时候出现 bug 。
判断输入值,如果输入值不为空进入下一步,如果为空的话结束。
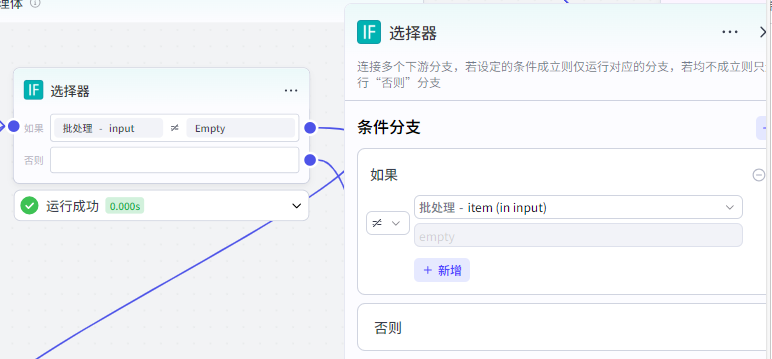
画板节点(内部)
它作用的话就是源源不断生成视频片段的图片,为下一步将这些图片转成片段短视频做准备。
它的输入值一共有 6 个,前 3 个讲过了,这里我讲一下后面三个,image_back_txt,video_txt,img,分别为,背景文字,视频文本内容,图片。
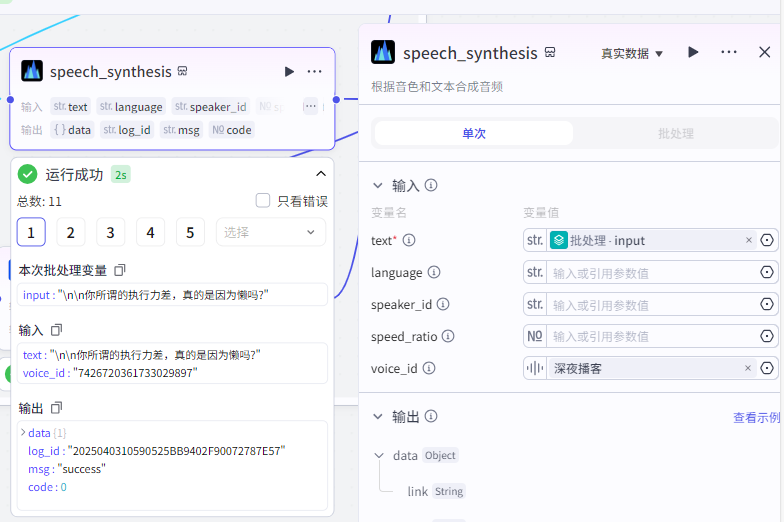
音频节点(内部)
它的作用主要是把那些一段段的文本,转化为语音的形式,其中 voice_id 可以更换不同的声音。
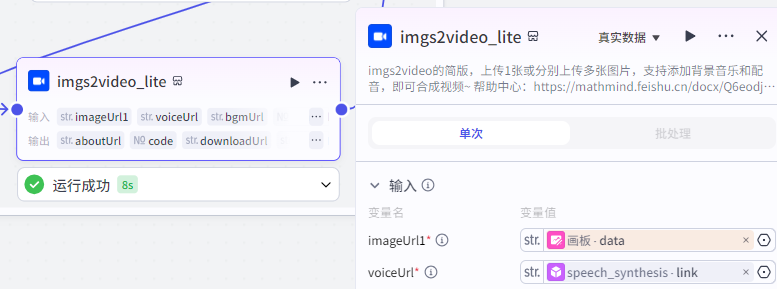
视频节点(内部)
把上面那些图片,音频,打包成一段段的视频装进数组(刚刚解释过了)里面。
注意这个节点是要收费的,每天免费 API 调用量为 100 ,应该是够你用的了。
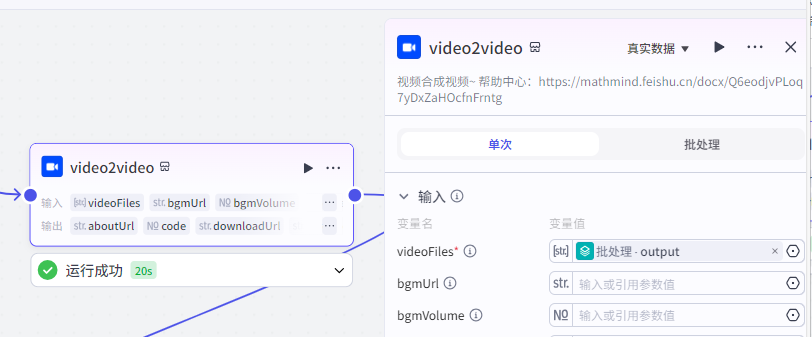
第七步,视频节点
它的作用主要是将上一步生成一段段的视频组装成一个完整的视频,并且输出视频的链接。
注意,这个节点和刚刚那个节点一样,也是要收费的,它两是一家的。
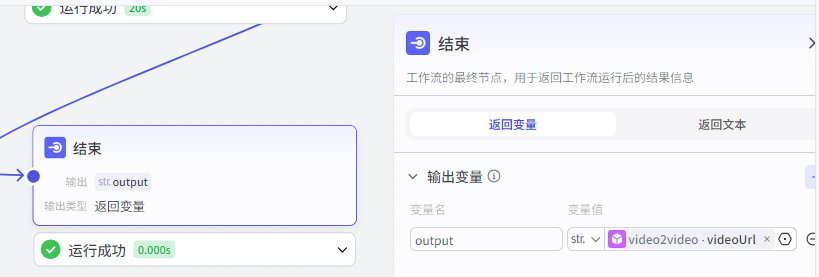
第八步,结束
没啥好说的,直接把视频的链接输出来就够了。
我们来看看整体生成的视频效果如何,刚进职场,打工省钱版,没那么多钱冲 token ,所以就不整那么长的时长了。
1
,时长01:05
这里我们还需要配上适合内容的音频以及 BGM 才能将视频的呈现效果拉满,后面的剪辑等等啥的,就交给各位来操作了。
总结
整体的流程就是这样,如果你的要求高一些,那么你就根据自身的情况,对工作流进行相应的调整就好。
本次的工作流难度还是比较大的,如果有哪一步不清楚,可以留言讨论。
如果你觉得文章没讲明白,也请你留言,最好就是来联系我,我需要根据大家的情况进行改进,用大家听得懂的话来讲,这对我极其重要,拜托各位了。
最后,无论你是用这种视频来做小红书变现,还是学习视频方面的工作流,我都希望你能坚持做下去,这样你才有机会成功。
感谢你的耐心。
如果看完喜欢,请帮忙转发分享一下,你的点赞转发,就是我更新下去的动力!
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **


















 492
492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









