







目录
有一段时间对模型加速比较感兴趣,其中的一块儿内容就是使用C++和cuda算子优化之类一起给模型推理提速。之前一直没有了解过cuda编程,也没有学习过C++相关的东西。强迫自己来学习一下cuda编程,同时也学习一下C++,扩宽一下AI相关的领域知识。主要是能够理解怎么使用cuda来提升模型的推理速度,学习的目标就是要会使用cuda编程实现基本的向量加法乘法、能使用C++和cuda混合编程实现神经网络的一些基本模块、最终能够完成C++语言和cuda混合编程(自己实现算子或者调用英伟达成熟的库)完成一个LLM模型的前向推理过程。这里是cuda编程的第一篇入门篇,了解基本概念、gpu的架构、cuda编程模型和实现cuda向量加法,对cuda编程有一个基础的了解和实践。
一、cuda编程的基本概念入门
1、GPU架构和存储结构
GPU全称图形处理器(graphics processing unit),主要是做图像和图像等涉及到并行计算的微处理器。 GPU和CPU同样有自己的架构,GPU更重计算、CPU更重逻辑控制。从硬件层面来说,GPU的内部构成如下图——详解GPU:

GPU通常包括图形显存控制器、压缩单元、BIOS、图形和计算阵列、总线接口、电源管理单元、视频管理单元、显示接口等,我们用来做深度学习就主要用到了它的图形和计算阵列模块。
GPU微架构
从微架构角度来说,GPU是由一个个SM(Streaming Multiprocessors)构成的。如下图:
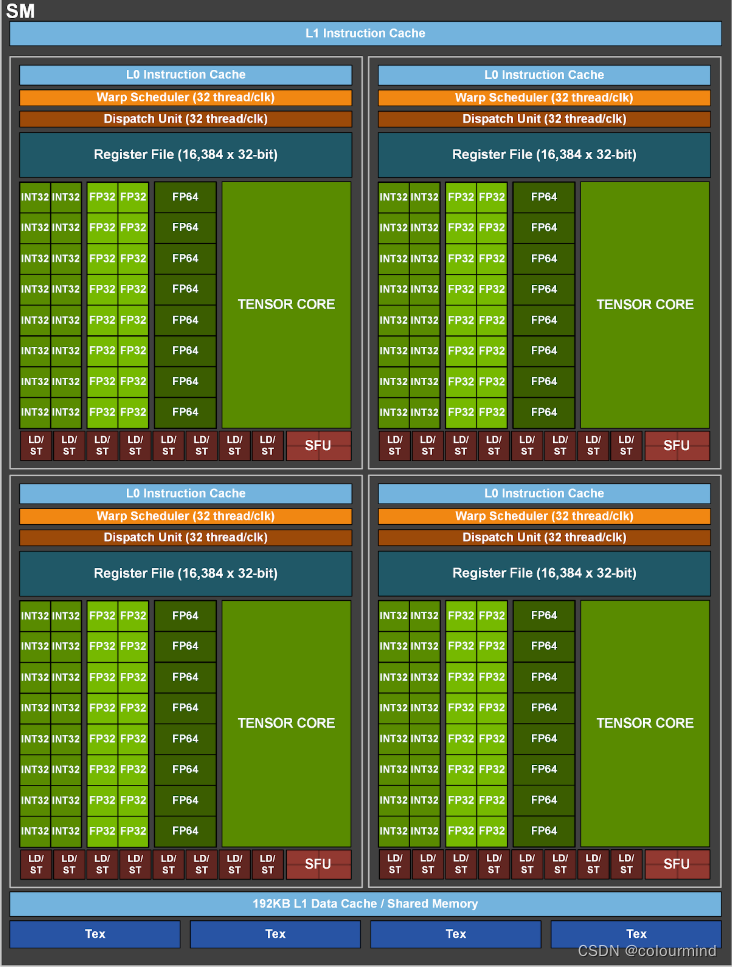
这是A100 安培架构显卡的SM内部结构图,SM由L1缓存、指令缓存、寄存器(Register)和Wrap scheduler等构成。图中的绿色部分是tensor core 也可以称作SP(Streaming processor),用于浮点数的计算,它可以支持一个时钟周期完成两个16×16矩阵的乘法操作,其他版本如Volta完成两个两个4×4半精度浮点矩阵的计算、Turing完成64个半精度浮点的乘加操作,总之计算速度更慢。
内存模型
GPU的内存也是多层级结构的,具体结构如下:
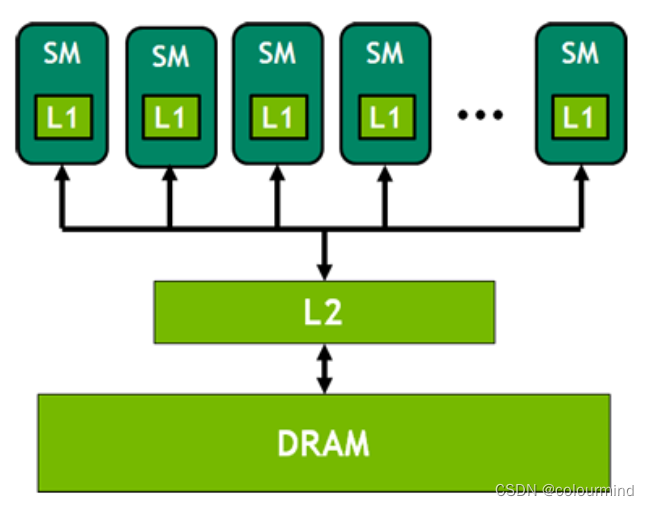
通用内存DRAM目前最好的显卡采用了HBM(High Bandwidth Memory 高带宽内存);更近一级的是L2缓存,所有的SM共享;L2之上就是L1缓存,SM独有,所有的线程共享;L1之上的就是寄存器,线程独有的。如图,英伟达的cuda编程指南中给出示意图:
2、cuda编程模型
GPU其实可以看做一个超多线程处理器,一个运行多次使用不同数据执行的程序,可以使用很多不同的线程来执行,在GPU上就是把这个函数编译为设备的指令集——kernel核函数。cuda就是实现这样功能的一个代码库,可以让开发者使用高级语言来实现上述GPU的多线程并行执行,加速计算速度。
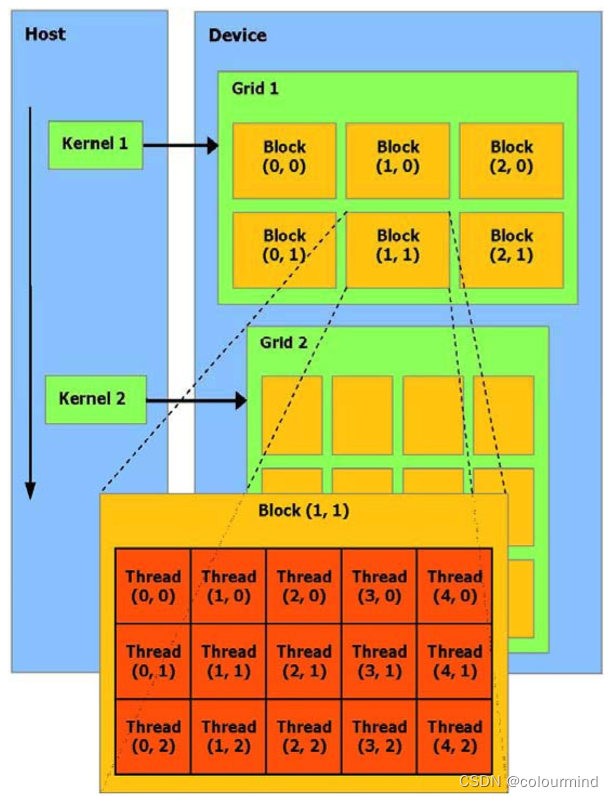
图中显示一个kernel会被grid中的线程块一起执行。这里就有几个概念,gird、block和thread。一个grid有多个block构成;一个block有多个thread构成。其中grid中的block有x/y/z三个维度,总数有最大值,每个维度上有各自的最大值,需要查阅当前的cuda规范。同时block中的线程也分x/y/z三个维度,总数有最大值,每个维度上有各自的最大值。一般来说,block中的线程数最大为1024个。线程的序号由block数目和线程在block中的位置,对于上述kernel1,thread(4,2)来说,线程Id
threadId
=(threadIdx.x+threadIdx.y*blockDim.x)+(blockIdx.x+blockIdx.y*gridDim.x)*(blockDim.x*blockDim.y)
=(4+2*5)+(1+1*3)*(5*3)=14+60=74
内存模型
线程在内存的使用是什么样的?GPU的内存模型如下:
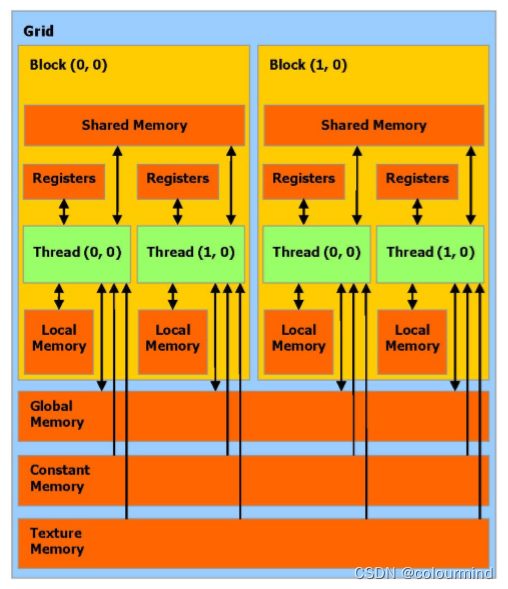
block中的线程共用shared Mem,线程独立拥有寄存器和本地内存,其它的内存都是所有的block共享的。
3、cuda编程流程
cuda编程流程其实有点像我们使用GPU进行模型训练,模型训练中首先是模型加载和数据的处理;然后是把模型参数和数据都从CPU内存移动到GPU内存(显存)上;最后进行模型训练。那cuda编程宏观上也是这么个逻辑,这里摘抄一段知乎博主小小将博文《CUDA编程入门极简教程》总结的流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
cuda编程的重点和难点也在于第三步cuda核函数的设计实现(设计一个跑通的可能不难但是设计一个高效率的可能就很难了),核函数的定义如下:
__global__ void kernelFunction(float *result, float *a, float *b){
doSomething
}使用__global__对核函数进行限定,表示该函数是一个GPU核函数,在GPU的线程中被执行。
使用一个核函数整体的代码流程如下:
__global__ void kernelFunction(float *result, float *a, float *b){
doSomething
}
int main(){
......
// 分配内存和显存
cudaMallocManaged();
//数据初始化
initWith();
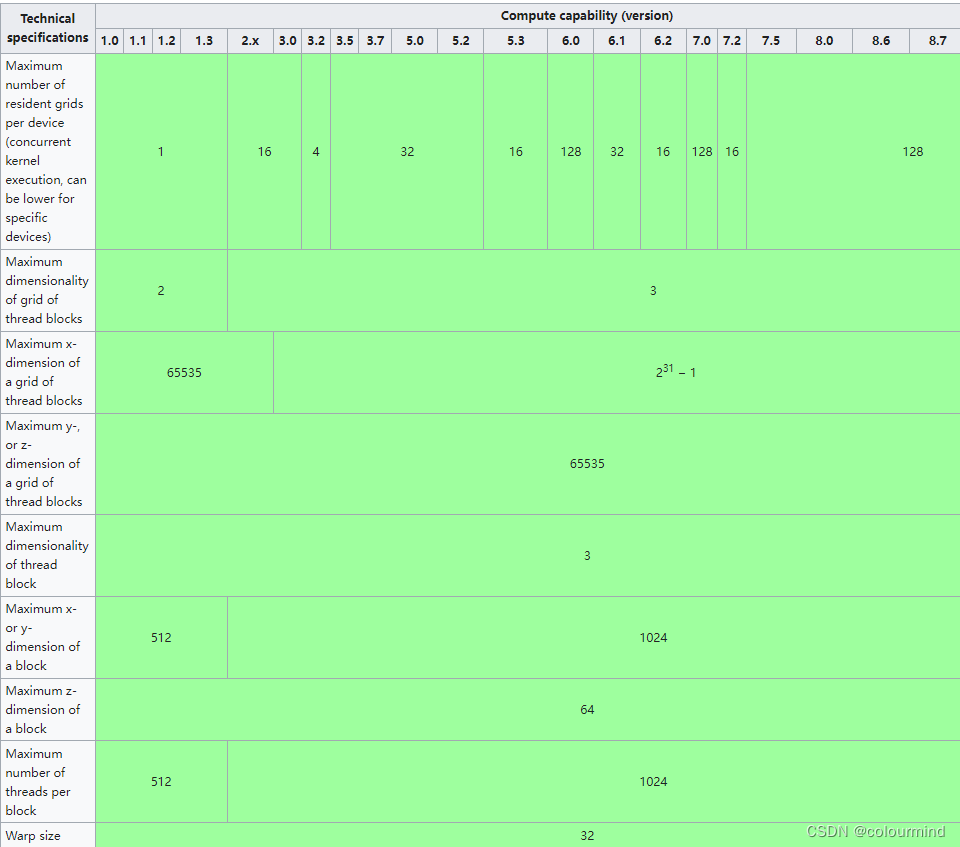
// 每一个gird有多少个block 最大2^31-1 x方向最大2^31-1 y,z 方向65535
dim3 gridDim(x,y,z);
// 每一个block有多少个线程 最大1024 x,y方向最大1024 z最大64
dim3 blockDim(x,y,z);
//执行核函数
kernelFunction <<< gridDim, blockDim >>>();
cudaDeviceSynchronize(); // 同步
......
}使用kernelFunction<<<gridDim,blockDim>>>()来指定对应的gridDim和blockDim并且启动和函数。根据wiki的数据显示:每一个gird有多少个block 最大2^31-1 x方向最大2^31-1 y,z 方向65535; 每一个block有多少个线程 最大1024 x,y方向最大1024 z最大64。
二、cuda向量加法实践
1、代码实现
接下来基于cuda来实现两个一维矩阵(一维向量)的加法。按照上述cuda编程流程,首先需要进行数据初始化,然后把数据传输到GPU上,然后进行cuda核函数的计算,最后得到结果释放资源。首先看一下数据怎么在CPU和GPU上灵活的传输,新版本的cuda有如下API:
cudaError_t cudaMallocManaged(void** ptr, size_t size)
该函数运行我们在内存和显存开辟size_t大小的空间,并智能的进行数据在CPU和GPU上的移动。
现在需要设计核函数,简单起见我们设置grid和block都为一维的,核函数逻辑就可以按照如下设计:
__global__ void addVectorskernel(float *result, float *a, float *b, int N){
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for (int i=index; i<N; i+=stride){
result[i] = a[i] + b[i]; // 元素a[i] + 元素 b[i]
}
}其中blockDim就表示一个block中有多少个线程,gridDim表示一个grid(一个gpu)中有多个block,那么总线程数就是blockDim.x * gridDim.x,每个线程处理的向量元素就是N/(blockDim.x * gridDim.x),因此就会有内部的循环,循环的步长也是总线程数blockDim.x * gridDim.x。当N=102400000,blockDim.x= 256,gridDim.x = 10,a矩阵的值全为3.0,b矩阵的值全为4.0,那么就可以得到如下代码nvcc_vector_add.cu:
#include<stdio.h>
#include<assert.h>
#include<cstdio>
#include<sys/time.h>
#include<iostream>
// 编译加链接
// nvcc -o nvcc_vector_add.cu nvcc_vector_add.o
// 直接运行即可
// 向量加法核函数
__global__ void addVectorskernel(float *result, float *a, float *b, int N){
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for (int i=index; i<N; i+=stride){
result[i] = a[i] + b[i]; // 元素a[i] + 元素 b[i]
}
}
// 初始化数组 a
void initWith(float num, float *a, int N) {
for(int i = 0; i < N; ++i) {
a[i] = num;
}
};
int main(){
const int N = 102400000;
const int M = 10;
size_t Mem = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, Mem);
cudaMallocManaged(&b, Mem);
cudaMallocManaged(&c, Mem);
initWith(3.0, a, N); // 将数组a中所有的元素初始化为3
initWith(4.0, b, N); // 将数组b中所有的元素初始化为4
initWith(0.0, c, N); // 将数组c中所有的元素初始化为0,数组c是结果向量
for(int i=0;i<M;i++){
printf("%f ",a[i]);
}
printf("\n");
printf("******************\n");
for(int i=0;i<M;i++){
printf("%f ",b[i]);
}
printf("\n");
printf("******************\n");
for(int i=0;i<M;i++){
printf("%f ",c[i]);
}
printf("\n");
printf("******************\n");
// 配置参数
size_t threadsPerBlock = 256;
// size_t numberOfBlocks = (N + threadsPerBlock - 1) / threadsPerBlock;
size_t numberOfBlocks = 10;
struct timeval start;
struct timeval end;
gettimeofday(&start,NULL);
addVectorskernel <<< numberOfBlocks, threadsPerBlock >>> (c, a, b, N); // 执行核函数
cudaDeviceSynchronize(); // 同步,且检查执行期间发生的错误
gettimeofday(&end,NULL);
float time_use;
time_use=(end.tv_sec-start.tv_sec)*1000000+(end.tv_usec-start.tv_usec);//微秒
std::cout <<"vector_add gpu time cost is "<<time_use/1000/100<< " ms"<< std::endl;
for(int i=0;i<M;i++){
printf("%f ",a[i]);
}
printf("\n");
printf("******************\n");
for(int i=0;i<M;i++){
printf("%f ",b[i]);
}
printf("\n");
printf("******************\n");
for(int i=0;i<M;i++){
printf("%f ",c[i]);
}
printf("\n");
printf("******************\n");
return 0;
}2、代码运行和结果
以上是一个.cu单文件,怎么运行它呢?需要使用英伟达的cuda环境进行编译和链接。在安装cuda toolkit的环境下,使用nvcc编译器进行编译:
//编译和链接
nvcc nvcc_vector_add.cu -o nvcc_vector_add
//运行
./nvcc_vector_add参数-o表示生成可执行文件,编译结果如下:

编译后生成一个可执行文件,直接运行该可执行文件,得到如下结果:
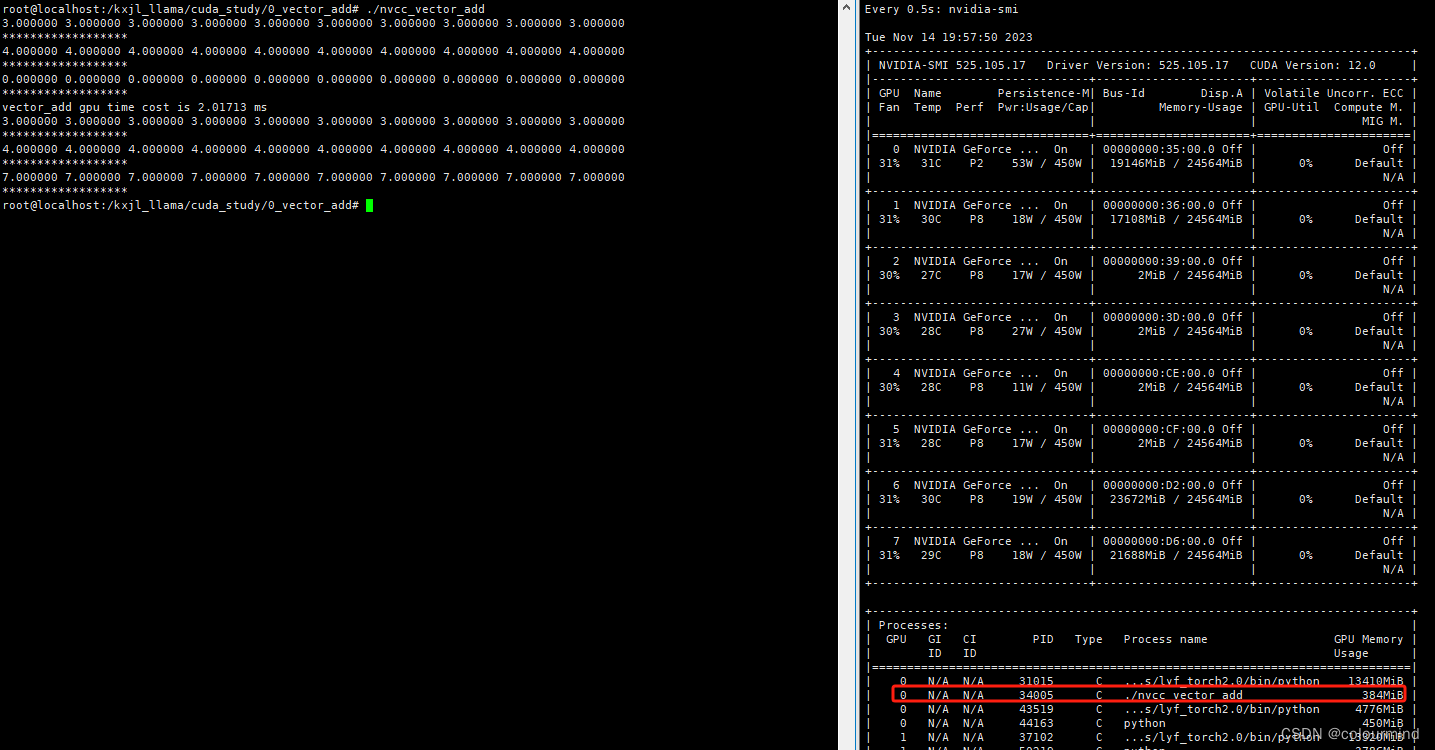
可以看到结果正确,耗时为2ms,显存使用384M。
调整一下blockDim、gridDim的大小看看耗时的变化情况。
blockDim=256,gridDim=5
vector_add gpu time cost is 2.23614 ms
blockDim=256,gridDim=10
vector_add gpu time cost is 2.01713 ms
blockDim=256,gridDim=20
vector_add gpu time cost is 2.05501 ms
blockDim=128,gridDim=10
vector_add gpu time cost is 2.1049 ms
blockDim=512,gridDim=10
vector_add gpu time cost is 2.027 ms
以上结果具有误差因为都只跑了一次,没有多次求平均值,但是可以说明gridDim和blockDim对性能是有影响的。一般来说blockDim选择为32的倍数,因为一个wrap的线程束是32,blockDim这样设置可以减少bank conflict。

















 3016
3016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









