







 本文详细介绍了模型融合技术,包括Voting、Averaging、Bagging、Boosting和Stacking方法。重点讲解了Stacking,通过K折交叉验证解决过拟合问题,以及mlxtend库在Stacking中的应用。
本文详细介绍了模型融合技术,包括Voting、Averaging、Bagging、Boosting和Stacking方法。重点讲解了Stacking,通过K折交叉验证解决过拟合问题,以及mlxtend库在Stacking中的应用。
模型融合方法概述
在比赛中提高成绩主要有3个地方
- 特征工程
- 调参
- 模型融合
1. Voting
模型融合其实也没有想象的那么高大上,从最简单的Voting说起,这也可以说是一种模型融合。假设对于一个二分类问题,有3个基础模型,那么就采取投票制的方法,投票多者确定为最终的分类。
2.Averaging
对于回归问题,一个简单直接的思路是取平均。稍稍改进的方法是进行加权平均。权值可以用排序的方法确定,举个例子,比如A、B、C三种基本模型,模型效果进行排名,假设排名分别是1,2,3,那么给这三个模型赋予的权值分别是3/6、2/6、1/6 这两种方法看似简单,其实后面的高级算法也可以说是基于此而产生的,Bagging或者Boosting都是一种把许多弱分类器这样融合成强分类器的思想。
3. Bagging
Bagging就是采用有放回的方式进行抽样,用抽样的样本建立子模型,对子模型进行训练,这个过程重复多次,最后进行融合。大概分为这样两步:
-
重复K次
有放回地重复抽样建模
训练子模型 -
模型融合
分类问题:voting
回归问题:average
Bagging算法不用我们自己实现,随机森林就是基于Bagging算法的一个典型例子,采用的基分类器是决策树。R和python都集成好了,直接调用。
4. Boosting
Bagging算法可以并行处理,而Boosting的思想是一种迭代的方法,每一次训练的时候都更加关心分类错误的样例,给这些分类错误的样例增加更大的权重,下一次迭代的目标就是能够更容易辨别出上一轮分类错误的样例。最终将这些弱分类器进行加权相加。引用加州大学欧文分校Alex Ihler教授的两页PPT
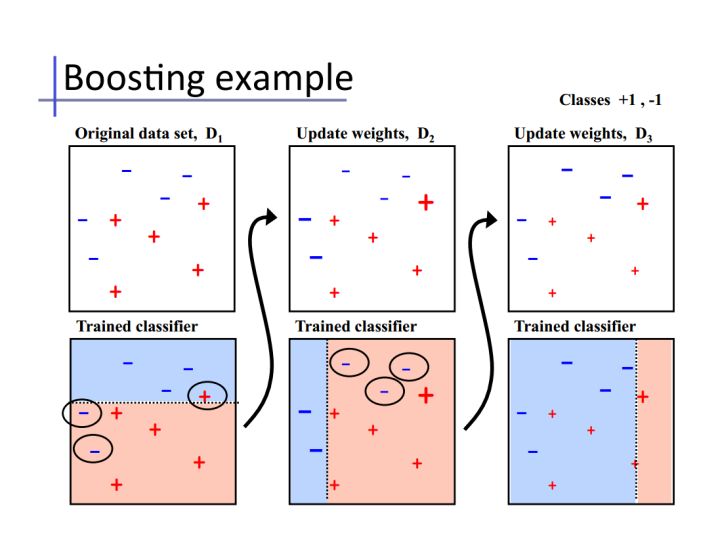
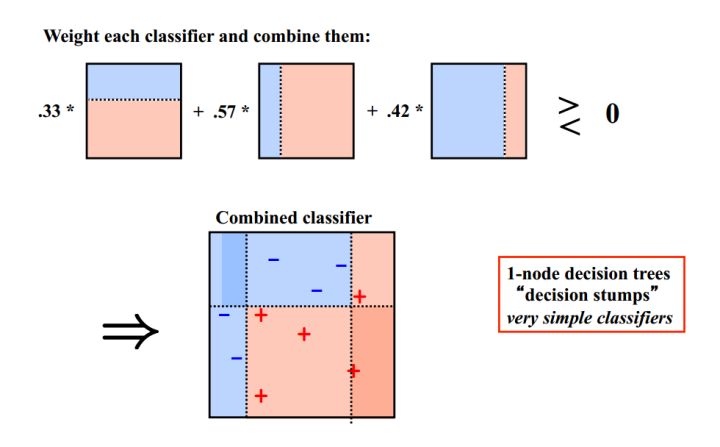
同样地,基于Boosting思想的有AdaBoost、GBDT等,在R和python也都是集成好了直接调用。
PS:理解了这两点,面试的时候关于Bagging、Boosting的区别就可以说上来一些,问Randomfroest和AdaBoost的区别也可以从这方面入手回答。也算是留一个小问题,随机森林、Adaboost、GBDT、XGBoost的区别是什么?
5. Stacking
Stacking方法其实弄懂之后应该是比Boosting要简单的,毕竟小几十行代码可以写出一个Stacking算法。我先从一种“错误”但是容易懂的Stacking方法讲起。
Stacking模型本质上是一种分层的结构,这里简单起见,只分析二级Stacking.假设我们有3个基模型M1、M2、M3。
- 基模型M1,对训练集train训练,然后用于预测train和test的标签列,分别是P1,T1
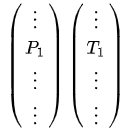
对于M2和M3,重复相同的工作,这样也得到P2,T2,P3,T3。
- 分别把P1,P2,P3以及T1,T2,T3合并,得到一个新的训练集和测试集train2,test2.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1628
1628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









