







引言
感兴趣区域池化(Region of interest pooling)(也称为RoI pooling)是使用卷积神经网络在目标检测任务中广泛使用的操作。例如,在单个图像中检测多个汽车和行人。其目的是对非均匀尺寸的输入执行最大池化以获得固定尺寸的特征图(例如7×7)。
计算机视觉中的两个主要任务是对象分类和目标检测。在第一种情况下,系统应该正确地标记图像中的主要对象。在第二种情况下,它应该为图像中的所有对象提供正确的标签和位置。当然还有其他有趣的计算机视觉领域,例如图像分割,但今天我们将专注于检测。在这个任务中,我们通常应该从先前指定的一组类别中的任何对象周围绘制边界框,并为每个类别分配一个类。例如,假设我们正在开发一种自动驾驶汽车的算法,我们想用相机来检测其他汽车,行人,骑自行车者等等 - 我们的数据集可能看起来像这样。
在这种情况下,我们必须在每个重要对象周围绘制一个框并为其分配一个类。此任务比分类任务(如MNIST 或CIFAR)更具挑战性 。在视频的每个帧上,可能存在多个对象,其中一些重叠,一些不明显或被遮挡。而且,对于这样的算法,性能可能是关键问题。特别是对于自动驾驶,我们必须每秒处理数十帧。
那么我们如何解决这个问题呢?
经典架构
我们今天要讨论的对象检测架构分为两个阶段:
- 区域建议(Region proposal):给定输入图像查找可以定位对象的所有可能位置。此阶段的输出应该是对象的可能位置的边界框列表。这些通常被称为区域提案或感兴趣的区域。
- 最终分类(Final classification):对于前一阶段的每个区域提案,确定它是属于目标类别之一还是属于背景。在这里,我们可以使用深度卷积网络。
 Object detection pipeline with region of interest pooling
Object detection pipeline with region of interest pooling
通常在提案(Region proposal)阶段,我们必须生成许多感兴趣的区域。为什么?如果在第一阶段(区域提议)中未检测到对象,则无法在第二阶段对其进行正确分类。这就是为什么这个地区的提案有很高的召回率非常重要。这是通过生成大量提案(例如,每帧几千)来实现的。在检测算法的第二阶段中,大多数将被归类为背景。
这种架构的一些问题是:
- 生成大量感兴趣的区域可能会导致性能问题。这将使实时对象检测难以实现。
- 它在处理速度方面不是最理想的。稍后会详细介绍。
- 你无法进行端到端的培训,也就是说,你无法在一次运行中训练系统的所有组件(这会产生更好的结果)
这就是感兴趣区域池化所要发挥作用的地方。
感兴趣区域池化 - 描述
感兴趣区域池化是用于目标检测任务的神经网络层。它最初是由Ross Girshick在2015年4月提出的(文章可以在这里找到),它实现了培训和测试的显着加速。它还保持高检测精度。该图层有两个输入:
- 从具有多个卷积和最大池层的深度卷积网络获得的固定大小的特征映射。
- 表示感兴趣区域列表的N×5矩阵,其中N是RoI的数量。第一列表示图像索引,其余四列是区域左上角和右下角的坐标。

Pascal VOC数据集的图像,注释了区域提案(粉红色矩形)
RoI池实际上做了什么?对于来自输入列表的每个感兴趣区域,它采用与其对应的输入特征图的一部分并将其缩放到某个预定义的大小(例如,7×7)。缩放通过以下方式完成:
- 将区域提案划分为相等大小的部分(其数量与输出的维度相同)
- 找到每个部分的最大值
- 将这些最大值复制到输出(max pooling)
结果是,从具有不同大小的矩形列表中,我们可以快速获得具有固定大小的相应特征映射的列表。请注意,RoI池输出的维度实际上并不取决于输入要素映射的大小,也不取决于区域提议的大小。它仅由我们将提案划分为的部分数量决定。RoI汇集有什么好处?其中之一是处理速度。如果框架上有多个对象建议(并且通常会有很多对象建议),我们仍然可以为所有这些建议使用相同的输入要素图。由于在处理的早期阶段计算卷积非常昂贵,因此这种方法可以为我们节省大量时间。
感兴趣区域池化 - 例子
让我们考虑一个小例子,看看它是如何工作的。我们将在单个8×8特征图上执行感兴趣区域,一个感兴趣的区域和2×2的输出大小。我们的输入要素图如下所示:(以下为图像,一般处理时转化像素为映射到0~1的实数,保持精度)

假设我们还有一个区域建议(左上角,右下角坐标)(0,3),(7,8)。在图片中它看起来像这样:?

通常,每个都有多个功能图和多个提案,但我们为这个例子保持简单。
通过将其划分为(2×2)个部分(因为输出大小为2×2),我们得到:

请注意,感兴趣区域的大小不必完全被池化部分的数量整除(在这种情况下)我们的RoI是7×5,我们有2×2汇集部分)。
每个部分的最大值是:
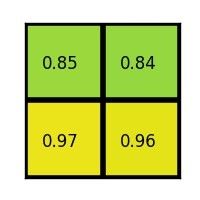
这是感兴趣区域池化层的输出。这是我们以动画形式呈现的示例: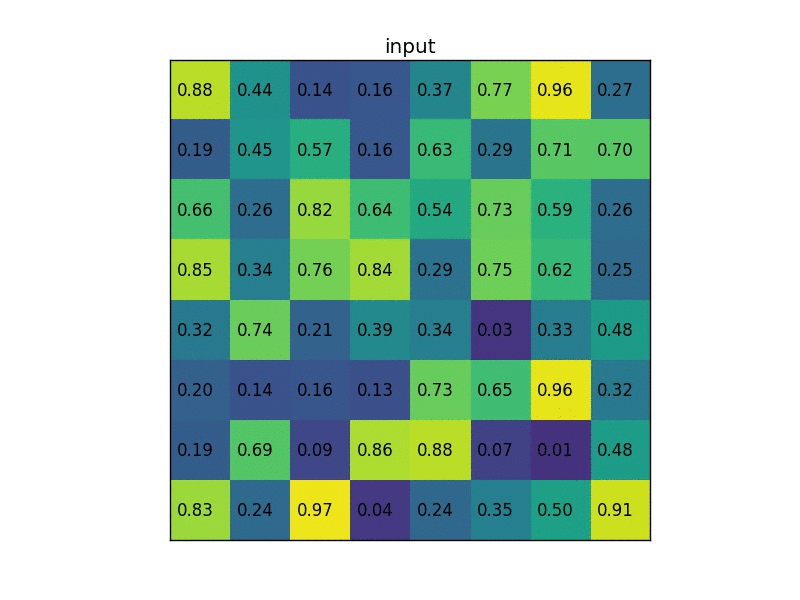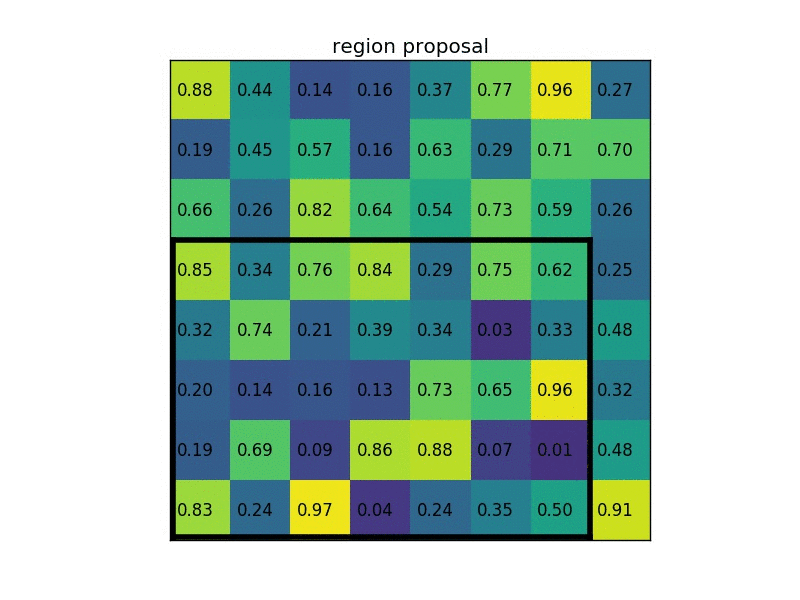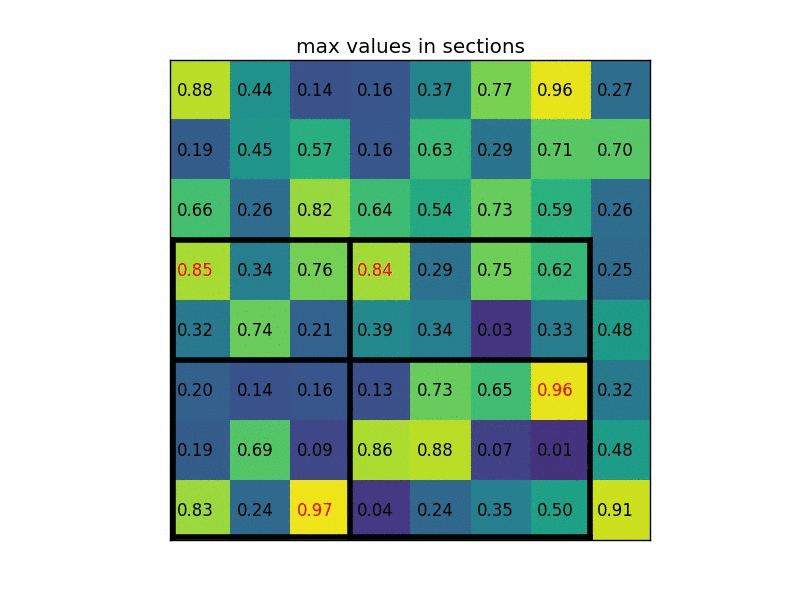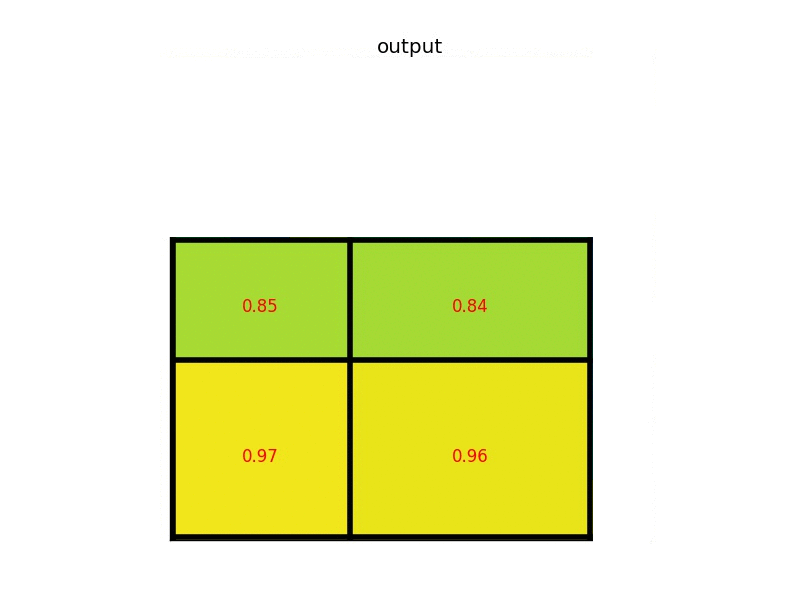
关于RoI Pooling最重要的事情是什么?
- 它用于对象检测任务
- 它允许我们重新使用卷积网络中的特征映射
- 它可以显着加快列车和测试时间
- 它允许以端到端的方式训练物体检测系统
参考文献:
- Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
- Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
- Sermanet, Pierre, et al. “Overfeat: Integrated recognition, localization and detection using convolutional networks.” arXiv preprint arXiv:1312.6229. 2013.















 744
744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









