







决策树算法属于数据挖掘中的分类中的一种方法,决策树包含经典的ID3和C4.5算法。
ID3原理解析
ID3利用信息论中的信息熵和信息增益的概念
熵表征物质的混乱程度,越混乱熵值越高,反之熵值越低。
在ID3方法中利用熵减思想,可以简单这么理解:
选择某一属性作为根节点,使得最终所分得的类别的混乱度最小,即类别之间清晰可辨。
信息增益:可以简单理解为熵变,表征某一属性在总体数据集中的重要程度。
即利用该属性对数据集进行划分时,体现为划分结果的辨识度。
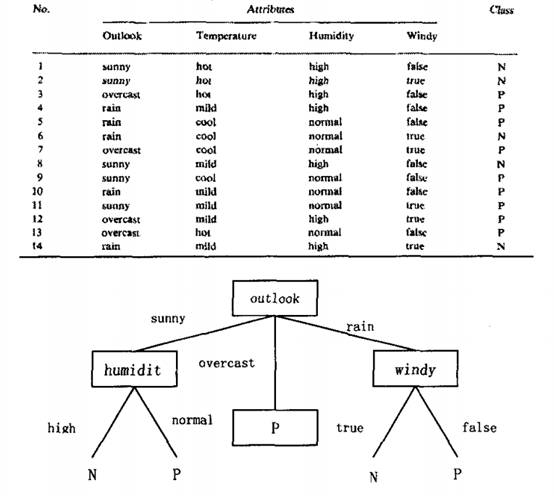
在上述图片中,Outlook、Temperature、Humidity、Windy为属性
P,N为最终要划分的类别,例如,在上述属性下,要不要去钓鱼等等
设T为数据集,类别集合为C{C1,C2,…,Ck},某一属性V有互不重合的多个取值V{V1,V2,…Vn}将T划分为n个子集T1,T2,…,Tn,如属性Outlook将数据划分为sunny、overcast、rain三个子集
令:|T|为数据集T中的例子数,如图片中的14行源数据;
|Ti|为数据集子集Ti中的例子数,如子集sunny有5个,overcast有4个,rain有5个
|Cj|为类别Cj的例子数,如类别P有9个,类别N有5个
|Cjv|为子集Ti中类别为Cj的例子数,如子集sunny中类别为P的有2个,N的有5个


计算出每个属性的信息增益,选取信息增益最大的属性作为决策树的根节点
如上图中的outlook,按照不同取值分枝,每一个分枝再利用上述同样的方法选取下一个属性作为子节点,直到到达叶节点 (即类别P或N) 或者属性值为空,结束。
ID3缺点:
1. 偏向性,即偏向于选择属性值较多的属性作为根节点,比如说属性Outlook在14个源数据中有14个值,那么该属性作为根节点的可能性会最大。原因在于属性值越多,按照公式计算出来的条件信息熵越小,得到的信息增益越大。但是实际上,这样的分类往往是没有意义的。
2. 不支持连续属性,即如果属性值是连续的如薪水、年纪等等,ID3没有很好地处理
3. 不考虑缺值情况,即ID3默认情况下不考虑缺值情况,这不太实际,因为实际上数据
集中往往有错误的或者缺值的数据。
C4.5与原理解析
而针对ID3的不足,C4.5补上了上述三种不足之处
首先,针对偏向性,C4.5利用信息增益率而非信息增益来确定根节点
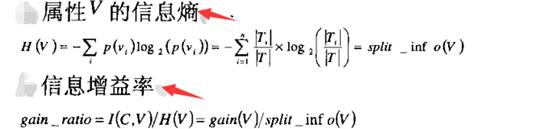
如上所示,相比于ID3,多了两步计算。
先算出属性信息熵,公示跟之前计算类别信息熵类似;
在计算信息增益率,即某一属性的信息增益比上该属性的信息熵
按照这样的方式,计算出所有属性的信息增益率,选取最大的属性作为跟节点。
其次,针对属性连续值问题,C4.5将连续的属性值离散化
例如,属性A取值为{V1,V2,…,Vm},则在任一Vi和Vi+1之间取一个值就可以将属性A的值分为两部分,相当于在m个点之间插值,这样一共有m-1中分法,每次选取V=(Vi+Vi+1)/2,即取中间值。
以这种方式将属性A的连续值离散化,并计算每次取值的信息增益率,找出使得信息增益率最大的那个取值,然后与实际值比较,将最接近取值的实际值作为分割属性连续值的最佳阈值。
注意:取值、实际值、最佳阈值的含义,不要搞混了。
这样就很好的解决了ID3的属性连续性问题
最后,针对却值问题,C4.5采取将缺值赋予所有可能的值并加以权重
对于源数据中某一属性中的缺值,C4.5采取的是将该缺值赋予所有可能的值,并将每一个赋予的可能值加上权重,即该值出现的可能性大小,而没有缺值的情况权重为1,这样可能出现的情况是,数据集中的例子数不是整数,但是不影响计算信息增益率。
结束语:虽然C4.5很好的解决了ID3的不足之处,但是仍存在一些缺陷,不如说在获取最佳分割阈值时,计算量很大,尤其是属性值很多时,时间复杂度令人担忧。网上有对C4.5的继续改进,在此就不再赘述。
















 4185
4185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









