








***论文《 Fast Hardware-Aware Neural Architecture Search》-2020-CVPR *****
论文链接
一、摘要及主要贡献
1.1 摘要
论文提出了在更大的搜索空间上探索自动硬件感知搜索和两阶段搜索算法,以有效地为不同类型的硬件生成定制模型。在图像网上的大量实验表明,论文论文的算法在三种硬件上在相同的延迟约束下优于最先进的硬件感知NAS方法。此外,所发现的架构比目前最先进的高效模型获得了更低的延迟和更高的精度。值得注意的是,飓风在图像网上达到了76.67%的最高精度,DSP的推理延迟只有16.5毫秒,分别比FBNet-iPhoneX高3.47%的精度和6.35×的推理加速。
对于VPU,论文以1.49×的速度,比无氧移动系统的最高精度高0.53%。即使对于研究充分的移动CPU,论文也实现了比FB网-i手机X高1.63%的最高准确率,只有类似的推理延迟。与SPOS相比,飓风还将训练时间减少了30.4%。
1.2 主要贡献
(i)以最小的人为设计为目标硬件自动生成更有效的搜索空间,
(ii)深入探索更多的架构,并减少搜索空间的大小。
论文在三个硬件平台上对ImageNet2012年和面向用户时代的数据集进行了全面的实验(图1(a))。

二、论文相关
2.1 具有硬件感知的搜索空间
(1)不同的候选操作池。
论文的池包含最多32个具有不同计算级别和内存复杂性的运算符(详见表2)。它们建立在当前有效模型的以下4个基础结构之上:
【SEP】:MobileNetV1的可分离卷积。在DARTS之后,应用了两次深度可分离的卷积。SEP的FLOP数量比其他的要大,但内存访问的复杂性较低
【MB】:MobileNetV2的 inverted bottleneck convolution。它的计算复杂度由核大小k和扩展速率e决定。
【Choice】:ShuffleNetV2中的基本构建块。Choice和ChoiceX比其他的要小得多,但是由于通道分割和连接操作,内存的复杂性很高
【SE】:通道注意力机制块。并且遵循MobileNetV3对的设置。SE的计算复杂度取决于其插入位置,而内存存取成本相对较低。

(2)硬件感知到的搜索空间的生成
为了在提高搜索空间的同时降低搜索效率,提出了一种真实的硬件部署分数为每一层选择最有效的操作符。论文分层对所有32个算子进行基准测试,并按照方程2中其分数的非递增顺序进行排序:
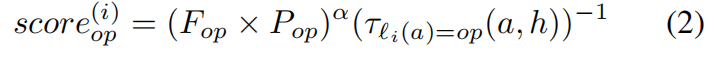
其中FoP和POP分别是运算符的FLOP计数和op的参数数,ℓi(a)=op表示其第i个可学习层是op的体系结构。参数α是非负的常数。第i可学习层(分数(i)op)的分数考虑了表示能力(近似)和实际硬件性能。
对于每一层,过滤掉了得分最高的第一个p运算符,搜索空间的大小将为np(n是可学习层的数量)。在实验中,为每一层选择顶部的p=4操作符,以保持与其他NAS搜索空间相似的大小。
(3)探索操作符。
一些层(通常在接近输出的层中)对延迟的贡献很小(由于特征地图的大小很小),在第一个p算符之外还添加了一个额外的探索算符。主干网络(如表1所示),将探索操作符添加到最后4层是因为它们的特征图大小最小。
为硬件感知平台构建了三个不同的搜索空间,如表1所示。对于每个专门的搜索空间,它包含n个=20个可学习层,每个层可以从表1中的4或5个候选操作符中进行选择。每个搜索空间包含4的16次方 ×5的4次方≈2×10的13次方可能个架构,大约是SPOS搜索空间的两倍。

2.2 两阶段的NAS加速
(1)图层分组。
操作员搜索后面的层比早期的层更重要。为此,论文将CNN模型的n个层分为两组:早期的t层和后来的n−t层。
(2)两阶段的搜索算法。算法1说明了具有双阶段搜索加速的硬件感知NAS的主要过程。每个阶段都从不同的获胜架构开始,并运行一个一次性的NAS来搜索目标组的可学习层。论文将其余组视为非活动固定层,并使用获胜体系结构的相应层操作符。首先,论文建立了最初的获胜架构,包括每一层得分最高的操作符(第4-6行)。

首先,阶段1搜索后面的n−t层的交换0。论文将后面的n−层标记为激活,将前面的t层标记为非活动。非活动层固定到架构0的相应层结构(第9行),同时从生成的操作符列表li(a)(第10-12行)搜索活动层。一次性的NAS方法本身与工作[9]相似,除了论文使用FLOP以外的硬件延迟来限制搜索空间(第14行)。在一个完整的一次性搜索过程中,将生成一个新的获奖架构。
其次,第二阶段从新的获奖架构开始,并搜索早期的t层。后面的n−t层固定到a1的相应层运算符,前面的t层在另一个一次性搜索中激活。阶段2获得了最终架构awin2。
(3)超参数t.算法1中的层分组边界t会影响到双级加速度的有效性和效率。具体来说,两阶段加速返回到原始的One-shot NAS,并在t=0时搜索完整的n个可学习层,因此没有降低搜索成本。虽然更大的t大大减少了超网的训练时间,但它可能会损害对最佳架构的搜索。根据超网的自然分辨率变化来设置t=8(只计算可学习的层)。搜索空间的大小缩小了≈65,000×。根据经验结果,当t=8时,两阶段搜索算法在两个数据集上取得了更好的精度和有希望的搜索时间减少。详见表5)。论文将研究更多关于如何选择t在未来的工作。
三、试验部分
表3。与ImageNet上最先进的硬件感知NAS方法相比,HURRICANE是唯一一种在所有目标硬件上一致实现高精度和低延迟的NAS方法。延迟数是在论文的硬件平台上测量的。⋆:论文运行Proxyless-R and SPOS的正式开源实现,以在论文的硬件平台上搜索模型。:CPU延迟是在单个CPU核心上测量,浮动精度为32。

表4。与同级别的CPU推理延迟模型相比,HURRICANE-CPU在图像网络上的准确率从73.27%提高到74.59%。与海拔最高精度模型相比,HURRICANE-CPU1将CPU推理时间加速了1.62×-2.77×。

图3;在硬件专用的搜索空间中采样的体系结构比手动设计的和原始的大型搜索空间能获得更低的延迟。y轴进行对数缩放,以进行更好的比较。

图4。与人工设计的搜索空间相比,论文的硬件感知搜索空间通过SPOS实现了更高的精度。

表5:与SPOS相比,论文的两阶段搜索方法在人工设计和硬件感知的搜索空间上都以更低的搜索成本(511.1%-70%)获得了更高的准确率。论文列出了用于搜索成本的训练迭代OUI(批量大小=64)的比较。
















 754
754











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









