







目录
1. 逻辑回归简介
线性回归的模型是求出真实值Y和输入样本的特征X之间的线性关系系数
θ
\theta
θ,最终求得线性回归模型
Y
=
X
θ
Y=X\theta
Y=Xθ.当给出新的特征时, 我们希能够带入到
Y
=
X
θ
Y=X\theta
Y=Xθ中,求出预测值Y是连续值。归为回归模型。
当Y是离散值时,我们就需要对线性回归模型的Y做一次函数变换,将连续值转换成离散值。这时我们就引入逻辑回归。
逻辑回归(LogisticRegression)也叫对数几率回归。
机器学习算法可以分为回归算法和分类算法,逻辑回归算法并不是回归算法,仅为在线性回归的基础上,套用了一个逻辑函数 ,用来解决分类问题,因此将它归为分类算法。
2. 逻辑回归模型
逻辑回归可以解决二分类问题,也可以解决多分类问题。这里先讲述二分类问题,多分类问题待补充。
在逻辑回归(二分类)中,我们一般用sigmoid函数将连续值转换成离散值,实现二分类。
为什么要用sigmoid函数作为假设函数
2.1 假设函数
用sigmoid函数作为假设函数
sigmoid函数形式如下:
(1) g ( z ) = 1 1 + e − z \tag{1}g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1(1)
sigmoid函数的导数形式如下:
(2)
g
′
(
z
)
=
g
(
z
)
(
1
−
g
(
z
)
)
=
e
−
z
(
1
+
e
(
−
z
)
)
2
\tag{2}g^{'}(z) = g(z)(1-g(z))=\frac{e^{-z}}{(1+e^{(-z)})^{2}}
g′(z)=g(z)(1−g(z))=(1+e(−z))2e−z(2)
sigmoid函数图像:
sigmoid函数的性质:
x
>
0
x>0
x>0时,
y
y
y趋于1;
x
=
0
x=0
x=0时,
y
=
0.5
y=0.5
y=0.5;
x
<
0
x<0
x<0时,
y
y
y趋于0;

数据集
(3)
Y
=
(
y
1
y
2
⋯
y
i
)
\tag{3} Y=\begin{pmatrix} &y^1\\ &y^2\\ &\cdots\\ &y^i \end{pmatrix}
Y=⎝⎜⎜⎛y1y2⋯yi⎠⎟⎟⎞(3)
(3)
X
=
(
x
1
1
,
x
2
1
,
x
3
1
,
⋯
 
,
x
n
1
x
1
2
,
x
2
2
,
x
3
2
,
⋯
x
n
2
⋯
x
1
i
,
x
2
i
,
x
3
i
,
⋯
x
n
i
)
\begin{aligned} \tag{3}X=\begin{pmatrix} &x_1^1, &x_2^1, &x_3^1,&\cdots, &x_n^1 \\ &x_1^2, &x_2^2, &x_3^2,&\cdots &x_n^2 \\ &\cdots\\ &x_1^i, &x_2^i, &x_3^i,&\cdots &x_n^i \end{pmatrix} \end{aligned}
X=⎝⎜⎜⎛x11,x12,⋯x1i,x21,x22,x2i,x31,x32,x3i,⋯,⋯⋯xn1xn2xni⎠⎟⎟⎞(3)
X
b
=
(
1
,
x
1
1
,
x
2
1
,
x
3
1
,
⋯
 
,
x
n
1
1
,
x
1
2
,
x
2
2
x
3
2
,
⋯
x
n
2
⋯
1
,
x
1
i
,
x
2
i
,
x
3
i
⋯
x
n
i
)
\begin{aligned} X_b= \begin{pmatrix} &1,&x_1^1, &x_2^1, &x_3^1,&\cdots, &x_n^1 \\ &1,&x_1^2, &x_2^2 &x_3^2,&\cdots &x_n^2 \\ &\cdots\\ &1,&x_1^i, &x_2^i, &x_3^i&\cdots &x_n^i \end{pmatrix} \end{aligned}
Xb=⎝⎜⎜⎛1,1,⋯1,x11,x12,x1i,x21,x22x2i,x31,x32,x3i⋯,⋯⋯xn1xn2xni⎠⎟⎟⎞
Y
=
X
b
θ
Y=X_b\theta
Y=Xbθ
最终要求的模型参数
(4)
θ
=
(
θ
0
θ
1
⋯
θ
n
)
\tag{4} \theta=\begin{pmatrix} &\theta_0 \\ &\theta_1\\ &\cdots\\ &\theta_n \end{pmatrix}
θ=⎝⎜⎜⎛θ0θ1⋯θn⎠⎟⎟⎞(4)
θ
0
为
截
距
{\theta_0为截距}
θ0为截距
令
z
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
⋯
+
θ
n
x
n
=
X
i
θ
z=\theta_0+\theta_1x_1+\theta_2x_2+\cdots +\theta_nx_n=X^i\theta
z=θ0+θ1x1+θ2x2+⋯+θnxn=Xiθ得:
构造假设函数,假设数据服从伯努利分布:
(5)
p
^
=
h
θ
(
x
)
=
1
1
+
e
−
z
=
1
1
+
e
−
X
i
θ
\tag{5}\hat p=h_{\theta}(x)=\frac{1}{1+e^{-z}}=\frac{1}{1+e^{-X^i\theta}}
p^=hθ(x)=1+e−z1=1+e−Xiθ1(5)
y
=
{
1
p
^
⩾
0.5
,
即
X
i
θ
⩾
0
0
p
^
<
0.5
,
即
X
i
θ
<
0
y = \begin{cases} 1 & \hat p \geqslant0.5 , 即 X^i\theta\geqslant0 \\ 0 & \hat p<0.5, 即X^i\theta<0 \end{cases}
y={10p^⩾0.5,即Xiθ⩾0p^<0.5,即Xiθ<0
h
θ
(
x
)
∈
[
0
,
1
]
h_\theta(x)∈[0,1]
hθ(x)∈[0,1],假设
h
θ
(
x
)
h_{\theta}(x)
hθ(x)是样本
x
x
x为正例的可能性,
1
−
h
θ
(
x
)
1-h_{\theta}(x)
1−hθ(x)是样本
x
x
x为反例的可能性
正例:(
y
=
1
y=1
y=1):
P
(
y
=
1
∣
x
;
θ
)
=
h
θ
(
x
)
=
1
1
+
e
−
X
i
θ
P(y=1|x;\theta)=h_{\theta}(x)=\frac{1}{1+e^{-X^i\theta}}
P(y=1∣x;θ)=hθ(x)=1+e−Xiθ1
反例:(
y
=
0
y=0
y=0):
P
(
y
=
0
∣
x
;
θ
)
=
1
−
h
θ
(
x
)
=
1
−
1
1
+
e
−
X
i
θ
P(y=0|x;\theta)=1-h_{\theta}(x)=1-\frac{1}{1+e^{-X^i\theta}}
P(y=0∣x;θ)=1−hθ(x)=1−1+e−Xiθ1
两者的比值对数称为对数几率:
l
n
h
θ
(
x
)
1
−
h
θ
(
x
)
ln\frac{h_{\theta}(x)}{1-h_{\theta}(x)}
ln1−hθ(x)hθ(x)
决策边界:
X
i
θ
=
0.5
X^i\theta = 0.5
Xiθ=0.5
- 如果X有两个特征
- 则 θ 0 + θ 1 x 1 + θ 2 x 2 = 0 \theta_0+\theta_1x_1+\theta_2x_2=0 θ0+θ1x1+θ2x2=0
- x 2 = − θ 0 − θ 1 x 1 θ 2 x_2=\frac{-\theta_0-\theta_1x_1}{\theta_2} x2=θ2−θ0−θ1x1
2.2 损失函数推导
损失函数是基于极大似然估计 得到的
- 将上述概率合并,得: P ( y ∣ x ; θ ) = [ h θ ( x ) ] y [ 1 − h θ ( x ) ] 1 − y P(y|x;\theta) = [h_\theta(x)]^y[1-h_\theta(x)]^{1-y} P(y∣x;θ)=[hθ(x)]y[1−hθ(x)]1−y
- 构造逻辑回归模型的似然函数为: (7) L ( θ ) = ∏ i = 1 m p ( y = 1 ∣ x i ) y ( i ) p ( y = 0 ∣ x i ) 1 − y ( i ) \tag{7}L(\theta)= \prod_{i=1}^{m}p(y=1|x_i)^{y^{(i)}}p(y=0|x_i)^{1-y^{(i)}} L(θ)=i=1∏mp(y=1∣xi)y(i)p(y=0∣xi)1−y(i)(7) l ( θ ) l(\theta) l(θ)为样本的似然函数,有 θ ∗ \theta^{*} θ∗使得 l ( θ ) l(\theta) l(θ)的取值最大,那么 θ ∗ \theta^{*} θ∗就叫做参数 θ \theta θ的极大似然估计值
- 对数似然函数:
(8)
l
(
θ
)
=
∑
i
=
1
m
[
y
(
i
)
l
n
p
(
y
=
1
∣
x
i
)
+
(
1
−
y
(
i
)
)
l
n
p
(
y
=
0
∣
x
i
)
]
\tag{8}l(\theta)=\sum_{i=1}^{m}[y^{(i)}lnp(y=1|x_i)+(1-y^{(i)})lnp(y=0|x_i)]
l(θ)=i=1∑m[y(i)lnp(y=1∣xi)+(1−y(i))lnp(y=0∣xi)](8)化简
l ( θ ) = ∑ i = 1 m [ y ( i ) l n h θ ( x ) + ( 1 − y ( i ) ) l n ( 1 − h θ ( x ) ) ] l(\theta)=\sum_{i=1}^{m}[y^{(i)}lnh_{\theta}(x)+(1-y^{(i)})ln(1-h_{\theta}(x))] l(θ)=i=1∑m[y(i)lnhθ(x)+(1−y(i))ln(1−hθ(x))]
令每个样本属于其真实标记的概率越大越好, l ( θ ) l(\theta) l(θ)是高阶连续可到的凸函数,
取对数的原因:
根据前面你的似然函数公式,是一堆的数字相乘,这种算法求导会非常麻烦,而取对数是一种很方便的手段,由于ln对数属于单调递增函数,因此不会改变极值点,由于对数的计算法则:
l
n
a
b
=
b
l
n
a
,
l
n
a
b
=
l
n
a
+
l
n
b
lna^b=blna,lnab=lna+lnb
lnab=blna,lnab=lna+lnb,这样求导就很方便了。
2.3 损失函数
求最大似然函数,就是损失函数(对似然函数先取负号)最小化。所以加个负号就成了损失函数;最小化损失函数可以梯度下降法求解。
除以样本数m —— 数量越多误差越大,所以平滑一下
(9)
J
(
θ
)
=
−
1
m
l
(
θ
)
=
−
1
m
∑
i
=
1
m
[
y
(
i
)
l
n
h
θ
(
x
)
+
(
1
−
y
(
i
)
)
l
n
(
1
−
h
θ
(
x
)
)
]
=
−
1
m
∑
i
=
1
m
[
y
(
i
)
l
o
g
(
p
^
)
+
(
1
−
y
(
i
)
)
l
o
g
(
1
−
p
^
)
]
\tag{9} \begin{aligned} &J(\theta)=-\frac{1}{m}l(\theta)\\ &=-\frac{1}{m}\sum_{i=1}^{m}[y^{(i)}lnh_{\theta}(x)+(1-y^{(i)})ln(1-h_{\theta}(x))]\\ &=-\frac{1}{m}\sum_{i=1}^{m}[y^{(i)}log(\hat p)+(1-y^{(i)})log(1-\hat p)] \end{aligned}
J(θ)=−m1l(θ)=−m1i=1∑m[y(i)lnhθ(x)+(1−y(i))ln(1−hθ(x))]=−m1i=1∑m[y(i)log(p^)+(1−y(i))log(1−p^)](9)
模型求解
模型求解的过程实际上就是求损失函数最小时的参数 θ \theta θ,求解的方法有梯度下降法,坐标轴下降法,牛顿法等,这里用梯度下降法推导!!!
- 对损失函数求导 (10) ▽ J ( θ ) = ( ∂ J ( θ ) ∂ θ 0 ∂ J ( θ ) ∂ θ 1 ⋯ ∂ J ( θ ) ∂ θ n ) \tag{10}\triangledown J(\theta)=\begin{pmatrix} \frac{\partial J(\theta)}{\partial \theta_0}\\ \frac{\partial J(\theta)}{\partial \theta_1}\\ \cdots\\ \frac{\partial J(\theta)}{\partial \theta_n}\\ \end{pmatrix} ▽J(θ)=⎝⎜⎜⎜⎛∂θ0∂J(θ)∂θ1∂J(θ)⋯∂θn∂J(θ)⎠⎟⎟⎟⎞(10)
- 对 p ^ \hat {p} p^求导 (10) p ^ ′ = h θ ′ ( x ) = e − X i θ ( 1 + e ( − X i θ ) ) 2 \tag{10}\hat {p}^{'}=h_{\theta}^{'}(x) = \frac{e^{-X^i\theta}}{(1+e^{(-X^i\theta)})^{2}} p^′=hθ′(x)=(1+e(−Xiθ))2e−Xiθ(10)
- 对 l o g [ h θ ( x i ) ] 求 导 对log[h_\theta(x^i)]求导 对log[hθ(xi)]求导 (12) l o g [ h θ ( x i ) ] ′ = 1 h θ ( x i ) ⋅ h θ ( x i ) ′ = ( 1 + e − X i θ ) ( 1 + e − X i θ ) − 2 ⋅ e − X i θ = ( 1 + e − X i θ ) − 1 ⋅ e − X i θ = e − X i θ 1 + e − X i θ = 1 − 1 1 + e − X i θ = 1 − h θ ( x i ) \tag{12}\begin{aligned} &log[h_\theta(x^i)]^{'}\\ &=\frac {1}{ h_\theta(x^i)}·h_\theta(x^i)^{'}\\ &= (1+e^{-X^i\theta})(1+e^{-X^i\theta})^{-2}·e^{-X^i\theta}\\ &=(1+e^{-X^i\theta})^{-1}·e^{-X^i\theta}\\ &=\frac{e^{-X^i\theta}}{1+e^{-X^i\theta}}\\ &=1-\frac{1}{1+e^{-X^i\theta}}\\ &=1-h_\theta(x^i) \end{aligned} log[hθ(xi)]′=hθ(xi)1⋅hθ(xi)′=(1+e−Xiθ)(1+e−Xiθ)−2⋅e−Xiθ=(1+e−Xiθ)−1⋅e−Xiθ=1+e−Xiθe−Xiθ=1−1+e−Xiθ1=1−hθ(xi)(12)
-
对
l
o
g
[
1
−
h
θ
(
x
i
)
]
求
导
对log[1-h_\theta(x^i)]求导
对log[1−hθ(xi)]求导
(13) l o g [ 1 − h θ ( x i ) ] ′ = 1 1 − h θ ( x i ) ⋅ ( − 1 ) ⋅ h θ ( x i ) ′ = − 1 + e − x i e − x i ⋅ ( 1 + e − x i ) − 2 ⋅ e − x i = − h θ ( x i ) \tag{13}\begin{aligned} &log[1-h_\theta(x^i)]^{'}\\ &=\frac{1}{1-h_\theta(x^i)}·(-1)·h_\theta(x^i)^{'}\\ &=-\frac{1+e^{-x^i}}{e^{-x^i}}·(1+e^{-x^i})^{-2}·e^{-x^i}\\ &=-h_\theta(x^i)\\ &\end{aligned} log[1−hθ(xi)]′=1−hθ(xi)1⋅(−1)⋅hθ(xi)′=−e−xi1+e−xi⋅(1+e−xi)−2⋅e−xi=−hθ(xi)(13) - 对
(
1
−
y
(
i
)
)
l
o
g
[
1
−
h
θ
(
x
i
)
]
(1-y^{(i)})log[1-h_\theta(x^i)]
(1−y(i))log[1−hθ(xi)]求导
(14) d [ ( 1 − y ( i ) ) l o g ( 1 − h θ ( x i ) ] d θ j = ( 1 − y ( i ) ) ⋅ ( − h θ ( x i ) ) ⋅ X j ( i ) \tag {14} \begin{aligned} &\frac{d[(1-y^{(i)})log(1-h_\theta(x^i)]}{d\theta_j}\\ &= (1-y^{(i)})·(-h_\theta(x^i))·X_j^{(i)} \end{aligned} dθjd[(1−y(i))log(1−hθ(xi)]=(1−y(i))⋅(−hθ(xi))⋅Xj(i)(14) - 对
y
(
i
)
l
o
g
(
h
θ
(
x
i
)
)
]
y^{(i)}log(h_\theta(x^i))]
y(i)log(hθ(xi))]求导
(15) d [ y ( i ) l o g ( h θ ( x i ) ) ] d θ j = y ( i ) ( 1 − h θ ( x i ) ) ⋅ X j ( i ) \tag {15} \begin{aligned} &\frac{d[y^{(i)}log(h_\theta(x^i))]}{d\theta_j}\\ &=y^{(i)}(1-h_\theta(x^i))·X_j^{(i)} \end{aligned} dθjd[y(i)log(hθ(xi))]=y(i)(1−hθ(xi))⋅Xj(i)(15)
最终求化简结果 (16) J ( θ ) θ j = − 1 m ∑ i = 1 m ( h θ ( x i ) − y ( i ) ) X j ( i ) = − 1 m ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) X j ( i ) \begin{aligned}\tag{16} &\frac{J(\theta)}{\theta_j}=-\frac{1}{m}\sum_{i=1}^{m}(h_\theta(x^i)-y^{(i)})X_j^{(i)}\\ &=-\frac{1}{m}\sum_{i=1}^{m}(\hat y^{(i)}-y^{(i)})X_j^{(i)} \end{aligned} θjJ(θ)=−m1i=1∑m(hθ(xi)−y(i))Xj(i)=−m1i=1∑m(y^(i)−y(i))Xj(i)(16)
梯度下降法中的更新公式: (18) θ j = θ j − α m ∑ i = 1 m ( y ^ ( i ) − y ( i ) ) X j ( i ) \tag {18}\theta_j=\theta_j- \frac{\alpha}{m}\sum_{i=1}^{m}(\hat y^{(i)}-y^{(i)})X_j^{(i)} θj=θj−mαi=1∑m(y^(i)−y(i))Xj(i)(18)
i = 1 , 2 , 3 , ⋯   , m i= 1,2,3,\cdots,m i=1,2,3,⋯,m
j = 1 , 2 , 3 , ⋯   , n j=1,2,3,\cdots,n j=1,2,3,⋯,n
α 为 学 习 率 \alpha为学习率 α为学习率
正则化方法
为防止模型过拟合,提高模型的泛化能力,通常会在损失函数的后面添加一个正则化项。L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓【惩罚】是指对损失函数中的某些参数做一些限制
L2正则化(ℓ2 -norm)
使用L2正则化的模型叫做Ridge Regularization(岭回归),直接在原来的损失函数基础上加上权重参数的平方和:
令损失函数为
J
0
J_0
J0,则Ridge Regularization为:
(5)
J
=
J
0
+
1
2
η
∑
i
=
1
n
θ
2
\tag{5}J=J_0+\frac{1}{2}\eta \sum_{i=1}^{n}\theta^2
J=J0+21ηi=1∑nθ2(5)
使最终的损失函数最小,要考虑
J
0
J_0
J0和
(6)
L
2
=
1
2
η
∑
i
=
1
n
θ
2
\tag{6}L_2=\frac{1}{2}\eta \sum_{i=1}^{n} \theta^2
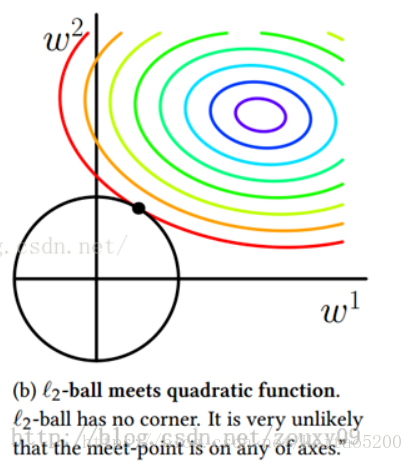
L2=21ηi=1∑nθ2(6)两个因素,最终的损失函数就是求等高 圆圈+黑色圆圈的和的最小值。由图可知两个圆相交时,
J
J
J取得最小值。
为什么
L
2
L_2
L2正则化项能够防止过拟合的情况?
对损失函数的参数优化求解过程进行分析
(7)
∂
J
∂
θ
=
∂
J
0
∂
θ
+
α
θ
\tag{7}\frac{\partial J}{\partial \theta}=\frac{\partial J_0}{\partial \theta}+\alpha \theta
∂θ∂J=∂θ∂J0+αθ(7)
(8)
∂
J
∂
b
=
∂
J
∂
b
\tag{8}\frac{\partial J}{\partial b}=\frac{\partial J}{\partial b}
∂b∂J=∂b∂J(8)
可以发现L2正则化项对b的更新没有影响,但是对于
θ
\theta
θ的更新有影响:
θ
→
θ
−
η
∑
i
=
1
m
∂
J
i
∂
θ
−
η
α
θ
\theta \rightarrow \theta - \eta\sum_{i=1}^{m} \frac{\partial J_i}{\partial \theta}-\eta \alpha \theta
θ→θ−ηi=1∑m∂θ∂Ji−ηαθ
(9) = ( 1 − η α ) θ − η ∑ i = 1 m ∂ J i ∂ θ \tag{9}=(1-\eta \alpha )\theta - \eta \sum_{i=1}^{m}\frac{\partial J_i}{\partial \theta} =(1−ηα)θ−ηi=1∑m∂θ∂Ji(9)
在不使用L2正则化时,求导结果中 θ \theta θ前系数为1,现在 θ \theta θ前面系数为 1 − η α 1−η\alpha 1−ηα ,因为η、 α \alpha α都是正的,所以 1 − η α 1−η\alpha 1−ηα小于1,它的效果是减小 θ \theta θ,这也就是权重衰减(weight decay)的由来。
在岭回归中,规范化项是所有系数的平方和,称为L2-norm(L2范数)。在我们的模型中就是试图最小化RSS+λ(sumβj^2)。当λ增加时,系数会缩小,趋向于0但永远不会为0。岭回归的优点是可以提高预测准确度,但因为它不能使任何一个特征的系数为0,所以在模型解释性上会有些问题。为了解决这个问题,我们使用LASSO回归。
L1正则化(ℓ1 -norm)
使用L1正则化的模型建叫做Lasso Regularization(Lasso回归),直接在原来的损失函数基础上加上权重参数的绝对值,
η
\eta
η为正则化参数:
假设损失函数为
(1)
J
0
=
∑
i
=
1
m
(
y
(
i
)
−
θ
0
−
θ
1
x
1
−
θ
2
x
2
−
⋯
−
θ
n
x
n
)
\tag{1}J_0=\sum_{i=1}^{m}(y^{(i)}-\theta_0-\theta_1x_1-\theta_2x_2-\cdots-\theta_nx_n)
J0=i=1∑m(y(i)−θ0−θ1x1−θ2x2−⋯−θnxn)(1)则Lasso Regularization为:
(2)
J
=
J
0
+
η
∑
i
=
1
m
∣
θ
∣
\tag{2}J=J_0+\eta \sum_{i=1}^{m}|\theta|
J=J0+ηi=1∑m∣θ∣(2)
J
J
J 是带有绝对值符号的函数,因此
J
J
J是不完全可微的。当我们在原始损失函数
J
0
J_0
J0后添加
L
1
L_1
L1正则化项时,相当于对
J
0
J_0
J0做了一个约束。令
L
1
=
η
∑
i
=
1
m
∣
θ
∣
L_1=\eta\sum_{i=1}^{m}|\theta|
L1=η∑i=1m∣θ∣,则
J
=
J
0
+
L
1
J=J_0+L_1
J=J0+L1,此时我们的任务变成在
L
L
L约束下求出
J
J
J取最小值时的
θ
\theta
θ。
η
\eta
η 被称为正则化系数.
下面通过图像来说明如何在约束条件
L
1
L_1
L1下求
J
J
J的最小值。
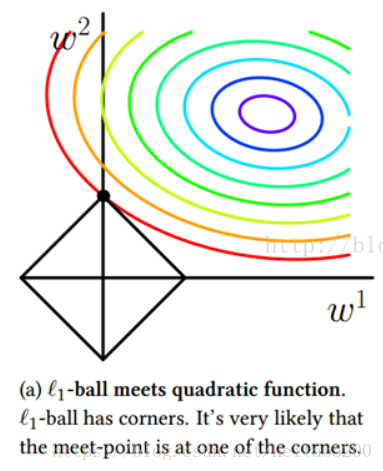
最终的损失函数就是求等高圆圈+黑色黑色矩形的和的最小值。由图可知等高圆圈+黑色矩形首次相交时,
J
J
J取得最小值。
为什么
L
1
L_1
L1正则化项能够防止过拟合的情况?
对损失函数的参数优化求解过程进行分析
(3)
∂
J
∂
θ
=
∂
J
0
∂
θ
+
α
s
g
n
(
θ
)
\tag{3}\frac{\partial J}{\partial \theta}=\frac{\partial J_0}{\partial \theta}+\alpha sgn(\theta)
∂θ∂J=∂θ∂J0+αsgn(θ)(3)
上式中
s
g
n
(
θ
)
sgn(\theta)
sgn(θ)表示
θ
\theta
θ的符号。那么权重
θ
\theta
θ的更新规则为:
(4)
θ
→
θ
−
η
∑
i
=
1
m
∂
J
i
∂
θ
−
η
α
s
g
n
(
θ
)
\tag{4}\theta \rightarrow \theta - \eta\sum_{i=1}^{m} \frac{\partial J_i}{\partial \theta}-\eta \alpha sgn(\theta)
θ→θ−ηi=1∑m∂θ∂Ji−ηαsgn(θ)(4)
比原始的更新规则多出了 η α s g n ( θ ) η \alpha sgn(\theta) ηαsgn(θ)这一项。当 θ \theta θ为正时,更新后的 θ \theta θ变小。当 θ \theta θ为负时,更新后的 θ \theta θ变大——因此它的效果就是让 η \eta η往0靠,使网络中的权重尽可能为0,也就相当于减小了网络复杂度,防止过拟合。
区别于岭回归中的L2-norm,LASSO回归使用L1-norm,即所有特征权重的绝对值之和,也就是要最小化RSS+λ(sum|βj|)。这个收缩惩罚项确实可以使特征权重收缩到0,相对于岭回归,这是一个明显的优势,因为可以极大地提高模型的解释性。如果LASSO这么好,那还要岭回归做什么?当存在高度共线性或高度两两相关的情况下,LASSO回归可能会将某个预测特征强制删除,这会损失模型的预测能力。举例来说,如果特征A和B都应该存在于模型之中,那么LASSO可能会将其中一个的系数缩减到0。可见岭回归与Lasso回归应该是互为补充的关系。
弹性网络
弹性网络的优势在于,它既能做到岭回归不能做的特征提取,又能实现LASSO不能做的特征分组。重申一下,LASSO倾向于在一组相关的特征中选择一个,忽略其他。弹性网络包含了一个混合参数α,它和λ同时起作用。α是一个0和1之间的数,λ和前面一样,用来调节惩罚项的大小。请注意,当α等于0时,弹性网络等价于岭回归;当α等于1时,弹性网络等价于LASSO。实质上,我们通过对β系数的二次项引入一个第二调优参数,将L1惩罚项和L2惩罚项混合在一起。通过最小化(RSS + λ[(1 - α)(sum|βj|^2)/2 + α(sum|βj|)]/N)完成目标。
逻辑回归的优缺点
优点
1、它是直接对分类可能性建模,无需事先假设数据分布,这样就避免了假设分布不准确问题。
2、它不仅预测类别,而且可以得到近似概率预测,这对许多概率辅助决策的任务很有用。
3、对率函数是任意阶可导凸函数,有很好的数学性质,现有许多的数值优化算法都可以直接用于求解。
缺点
对数据和场景的适应能力有局限性,不如决策树算法适应性那么强
sklearn.linear_model.LogisticRegression参数说明
| 参数 | 解释 | 数值类型(默认值) | 选项 |
|---|---|---|---|
| penalty | 正则化选择参数。‘newton-cg’,‘sag’和’lbfgs’解算器只支持l2惩罚。版本0.19中的新功能:使用SAGA求解器的l1惩罚(允许’多项’+ L1) | str (l1) | ‘l1’或’l2’, |
| dual | 对偶方法只用在求解线性多核(liblinear)的L2惩罚项上。当样本数量>样本特征的时候,dual通常设置为False。 | bool (False) | Ture/False |
| solver | solver参数决定了我们对逻辑回归损失函数的优化方法 | str(liblinear) | newton-cg;lbfgs;liblinear;sag;saga。 |
| multi_class | multi_class参数决定了我们分类方式的选择 | str(ovr) | ovr;multinomial |
| class_weight | 用于标示分类模型中各种类型的权重,可以是一个字典或者’balanced’字符串,默认为不输入,也就是不考虑权重,即为None。如果选择输入的话,可以选择balanced让类库自己计算类型权重,或者自己输入各个类型的权重。举个例子,比如对于0,1的二元模型,我们可以定义class_weight={0:0.9,1:0.1},这样类型0的权重为90%,而类型1的权重为10%。如果class_weight选择balanced,那么类库会根据训练样本量来计算权重。某种类型样本量越多,则权重越低,样本量越少,则权重越高。当class_weight为balanced时,类权重计算方法如下:n_samples / (n_classes * np.bincount(y))。n_samples为样本数,n_classes为类别数量,np.bincount(y)会输出每个类的样本数,例如y=[1,0,0,1,1],则np.bincount(y)=[2,3]。 | dict/str | 字典或者’balanced’字符串 |
| tol | 停止求解的标准 | Float(1e-4) | |
| c | 正则化系统λ的倒数 | Float(1.0) | |
| verbose | 日志冗长度 | int(0) | |
| warm_start | 热启动参数,如果为True,则下一次训练是以追加树的形式进行(重新使用上一次的调用作为初始化)。 | bool(False) | Flase/Ture |
| n_jobs | 并行数,用CPU的一个内核运行程序,2的时候,用CPU的2个内核运行程序。为-1的时候,用所有CPU的内核运行程序。 | int(1) | |
| max_iter | 算法收敛最大迭代次数,仅在正则化优化算法为newton-cg, sag和lbfgs才有用,算法收敛的最大迭代次数。 | int(10) | |
| random_state | 随机数种子,仅在正则化优化算法为sag,liblinear时有用。 | Int(无) | |
| fit_intercept | 是否存在截距或偏差 | bool(Ture) | False/Ture |
逻辑回归处理多分类问题
OvO(One vs One)
假设训练集有N类样本, C 1 , C 2 , ⋯   , C N C_1,C_2,\cdots,C_N C1,C2,⋯,CN训练时两两组合为二分类进行训练,新样本通过这 C N 2 C_N^{2} CN2个分类器后会得到 N ( N − 1 ) 2 \frac {N(N−1)}{2} 2N(N−1)个分类结果,最终结果可根据这些分类结果投票产生。
OvR(One vs Rest)
训练时一个类作为正例,其余所有类作为反例。这样共有 N N N个二分类器进行训练,新样本通过分类器时预测结果为正例的即为最终结果。
MvM(Many vs Many)
MvM是每次将若干各类作为正例,剩下的若干个类作为反例,OvO和OvR其实是MvM的特殊情况。但是MvM的正反例构造必须有特殊的设计,不能随意选取。这里我们介绍一种最常用的MvM技术:“纠错输出码”(ECOC)
类别不平衡问题
参考文献
逻辑回归原理小结
scikit-learn 逻辑回归类库使用小结
Logistic Regression(逻辑回归)原理及公式推导
机器学习算法–逻辑回归原理介绍
正则化方法















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









