







常用技术:TF-IDF、TextRank
整体上,关系词抽取方法,大致可以分为3类,基于统计的方法、基于图的方法、基于主题的方法、基于深度学习的方法,为了提高应用的准确率,一般是多种方法结合使用,比如,使用TF-IDF修正权重。
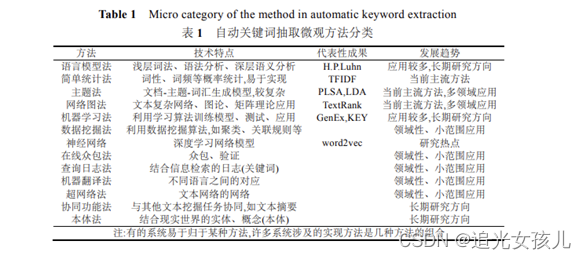
参考文献:自动关键词抽取研究综述
本机地址:E:\python project\pythonProject_draftKG\关键词抽取
git地址:git
关键词抽取结果
TF-IDF
id,key
0,生物 实验 有效载荷 防护 安全等级 载人 屏障 材料 样品 航天
1,有效载荷 测试 空间站 脱气 评价 倍频程 限值 医学 要求 污染物
2,接地 空间站 舱体 搭接 回线 电阻 设备 绝缘 隔离 安装
3,仿真 飞行器 轨道 追踪 参数 软件 对接 模型 试验 轨道控制
4,软件 计划 质量保证 审核 文件 文档资料 评审 要求 验证 叙述
5,项目 软件 估算 报告 应该 项目经理 工作 活动 进展 阶段
6,天线 方向 检验 增益 鉴定 相位 测量 电平 极化 测试
7,温度 试验 动力源 工作 样品 高度 接通 规定 步骤 电源
8,磁带 测试 电平 记录 信号 重放 磁道 输出 波长 磁电
9,文件 要素 示例 编号 符号 表述 标准化 给出 标准 脚注
10,润滑 轴承 润滑脂 固体 润滑油 转动 预紧 寿命 摩擦 部件
11,样品 实验 封装 材料 检验 坩埚 制备 材料科学 工艺 固体
12,相机 摄影 图像 试验 元素 测量 近景 检查点 行星 地形
TextRank
fname,key
CMS 10-2015载人航天工程有效载荷生物安全通用要求.txt,生物 应 实验 有效载荷 材料 防护 设计 样品 载人 进行
CMS 103 空间站有效载荷医学要求与评价方法.txt,有效载荷 测试 要求 应 空间站 评价 标准 脱气 结果 满足
CMS 40-2017 空间站接地要求.txt,应 设备 接地 空间站 舱体 搭接 电阻 回线 安装 结构
CMS 81 载人航天器交会对接仿真试验方法 第6部分:全任务联合仿真试验.txt,参数 飞行器 试验 轨道 追踪 软件 对接 系统 模型 目标
ESA PSS-01-101.txt,软件 应 计划 文件 要求 质量保证 验证 设计 方法 进行
ESA-PSS-05-08.txt,项目 工作 软件 报告 是 应该 包 方法 估算 活动
G1035.txt,天线 应 方向 图 测量 产品 检验 要求 进行 环境
G150-6.txt,试验 温度 工作 样品 规定 高度 条件 设备 标准 表
G383-17A.txt,测试 磁带 记录 电平 信号 输出 标准 重放 磁电 样品
TF-IDF实现关键词抽取
#参考:https://github.com/AimeeLee77/keyword_extraction
import os
import sys,codecs
import pandas as pd
import numpy as np
import jieba.posseg
import jieba.analyse
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
"""
TF-IDF权重:
1、CountVectorizer 构建词频矩阵
2、TfidfTransformer 构建tfidf权值计算
3、文本的关键字
4、对应的tfidf矩阵
"""
# 数据预处理操作:分词,去停用词,词性筛选
def dataPrepos(text, stopkey):
l = []
pos = ['n', 'nz', 'v', 'vd', 'vn', 'l', 'a', 'd'] # 定义选取的词性
seg = jieba.posseg.cut(text) # 分词
for i in seg:
if i.word not in stopkey and i.flag in pos: # 去停用词 + 词性筛选
l.append(i.word)
return l
# tf-idf获取文本top10关键词
def getKeywords_tfidf(dir,stopkey,topK):
fdir=os.listdir(dir)
corpus=[]
for fname in fdir:
fp=open(dir+'\\'+fname,encoding='utf_8',mode='r').read()
text = dataPrepos(fp, stopkey)
text = " ".join(text)
corpus.append(text)
#
# idList, titleList, abstractList = data['id'], data['title'], data['abstract']
# corpus = [] # 将所有文档输出到一个list中,一行就是一个文档
# for index in range(len(idList)):
# text = '%s。%s' % (titleList[index], abstractList[index]) # 拼接标题和摘要
# text = dataPrepos(text,stopkey) # 文本预处理
# text = " ".join(text) # 连接成字符串,空格分隔
# corpus.append(text)
# 1、构建词频矩阵,将文本中的词语转换成词频矩阵
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus) # 词频矩阵,a[i][j]:表示j词在第i个文本中的词频
# 2、统计每个词的tf-idf权值
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
# 3、获取词袋模型中的关键词
word = vectorizer.get_feature_names()
# 4、获取tf-idf矩阵,a[i][j]表示j词在i篇文本中的tf-idf权重
weight = tfidf.toarray()
# 5、打印词语权重
ids, keys = [], []
for i in range(len(weight)):
print (u"-------这里输出第", i+1 , u"篇文本的词语tf-idf------")
ids.append(i)
# titles.append(titleList[i])
df_word,df_weight = [],[] # 当前文章的所有词汇列表、词汇对应权重列表
for j in range(len(word)):
print( word[j],weight[i][j])
df_word.append(word[j])
df_weight.append(weight[i][j])
df_word = pd.DataFrame(df_word,columns=['word'])
df_weight = pd.DataFrame(df_weight,columns=['weight'])
word_weight = pd.concat([df_word, df_weight], axis=1) # 拼接词汇列表和权重列表
word_weight = word_weight.sort_values(by="weight",ascending = False) # 按照权重值降序排列
keyword = np.array(word_weight['word']) # 选择词汇列并转成数组格式
word_split = [keyword[x] for x in range(0,topK)] # 抽取前topK个词汇作为关键词
word_split = " ".join(word_split)
keys.append(word_split)
result = pd.DataFrame({"id": ids, "key": keys},columns=['id','key'])
return result
def main():
# 读取数据集
dir = ''#存放文件的地址
# data = pd.read_csv(dataFile)
# 停用词表
stopkey = [w.strip() for w in codecs.open('stopWord.txt',mode= 'r',encoding='utf_8').readlines()]
# tf-idf关键词抽取
result = getKeywords_tfidf(dir,stopkey,10)
result.to_csv("keys_TFIDF.csv",encoding='utf_8_sig',index=False)
if __name__ == '__main__':
main()
TextRank实现关键词抽取
import os
import sys
import pandas as pd
import jieba.analyse
"""
TextRank权重:
1、将待抽取关键词的文本进行分词、去停用词、筛选词性
2、以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
3、计算图中节点的PageRank,注意是无向带权图
"""
# 处理标题和摘要,提取关键词
def getKeywords_textrank(dir,topK):
fdir = os.listdir(dir)
ids,keys=[],[]
for fname in fdir:
fp = open(dir + '\\' + fname, encoding='utf_8', mode='r').read()
jieba.analyse.set_stop_words('stopWord.txt') # 加载自定义停用词表
text = fp
keywords = jieba.analyse.textrank(text, topK=topK) # TextRank关键词提取,词性筛选
word_split = " ".join(keywords)
print(word_split)
keys.append(word_split)
ids.append(fname)
result = pd.DataFrame({"fname": ids,"key": keys}, columns=['fname', 'key'])
return result
def main():
dir = ''
result = getKeywords_textrank(dir,10)
result.to_csv("keys_TextRank.csv",index=False)
if __name__ == '__main__':
main()















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











