







Few-Shot Named Entity Recognition: An Empirical Baseline Study
看法
整体感觉,这篇文章是工程实践中可以参考的,大杂烩的感觉,复现一次,应该就能吧self training,有监督学习的NER这两种范式,加上多模型的voting机制,应该就可以熟悉了。
现有的小样本学习的方法
(1)原型学习,利用每种类型的token表示,计算均值,作为每个原型type的representation
(2)在无标注数据上,做self training,一个teacher model(在有标注数据上做训练),一个student model(打上soft label)
(3)在无标注数据上,做model的PLM。

论文模型
(a)是最普通的,在有监督数据集上,做NER识别任务-------------------LC
(b)是利用原型网络,学习每个type的表示,利用最近邻原则,在test时,分配给token相应的tag---------------P
(c)是文章认为原始的PLM模型在大规模语料库学习时,采用的任务形式是mask token,这和NER任务并没有直接关系,它导致PLM视所有的token的地位等同,但在NER任务中,entity的地位应该高一些,所以,采用6.8G的维基细粒度实体数据集,重新训练了PLM模型,已达到entity的地位升高的效果----------------------NSP (noisy supervised pre-training)
(d)teacher-student model--------------------------------ST

实验结果
Testing F1-score curves on 5-shot NER on CONLL-2003 dataset.

IO和BIO schema下的模型性能比较

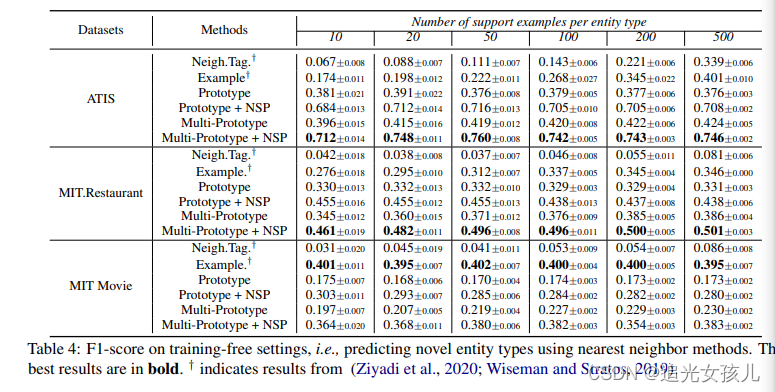
模型在新实体类型上的迁移能力
















 642
642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











