






1. 介绍
FewShot NER对于低资源域中的实体标记至关重要。现有的方法仅从源域学习特定于类的语义特征和中间表示。这会影响对看不见的目标域的通用性,从而导致性能不佳。为此,我们提出了CONTAINER,这是一种新的对比学习技术,它优化了标记间的分布距离。CONTAINER没有优化特定于类的属性,而是优化了一个广义目标,即基于高斯分布embedding区分token类别。这有效地缓解了源自训练领域的过度匹配问题。
few-shot learning涉及从很少的标记示例中学习看不见的类(Fei Fei et al.,2006;Lake et al.,2011;Bao et al.,2020)。为了避免对有限的可用数据进行过度拟合,引入了元学习来重点关注如何学习(Vinyals等人,2016年;Bao等人,2020年)。Snell et al.(2017)提出原型网络来学习度量空间,其中特定未知类的示例围绕单个原型聚集。虽然它主要部署在计算机视觉中,但Fritzler等人(2019)和Hou等人(2020)也使用了fewshot-NER的原型网络。另一方面,Yang和Katiyar(2020)提出了一个有监督的NER模型学习特定于类的功能并将中间表示扩展到看不见的域。此外,他们还采用了维特比解码模型的变体“StructShot”
Few shot NER比其他few shot学习任务更加困难。首先,作为序列标注任务,NER要求根据上下文以及标签内的依赖关系进行标签分配。其次,在NER中,在训练集中被标记为O的token很可能对应于测试集中的有效目标实体,这对于原型网络等元学习方法提出了挑战。(对于原型网络,这对围绕单个原型聚集实体示例的概念提出了挑战)。对于Yang和Katiyar(2020)等基于最近邻的方法,它们最初是“预训练”的,目标是源类特定的监督。因此,训练的权重将与源类紧密联系,网络将投影训练集O标记,以便它们在嵌入空间中聚集。 这将迫使embedding在测试集中删除许多与真正目标实体相关的有用特征。第三,在少数镜头设置中,没有足够的样本可以从中选择验证集。这降低了超参数调整的能力,这尤其会影响基于模板的方法,其中提示选择对于良好的性能至关重要(Cui等人,2021)。事实上,由于缺乏持续有效的验证集,许多早期的少数镜头作品都受到了质疑,他们的策略是否真的是“少数镜头”(Perez et al.,2021)
为了应对这些挑战,作者提出了一种新的方法 CONTAINER,利用对比学习的来解决fewshot NER。CONTAINER试图减少对相似实体的token embedding的距离,同时增加对不同实体的token embedding的距离(图1)。这使得CONTAINER能够更好地捕获标签依赖关系。此外,由于CONTAINER是用一个广义目标进行训练的,因此它可以有效地避免先前的方法打O的缺陷。最后,CONTAINER不需要任何特定于数据集的prompt或超参数调整。

与传统的对比学习不同优化point embedding优化样本距离,container优化了分布散度,有效地建模高斯embedding。高斯embedding显式地建模实体类分布,这不仅促进了广义特征表示,而且有助于少样本目标域自适应
因此高斯嵌入显式地建模实体类分布,这不仅促进了广义特征表示,而且有助于少样本目标域的自适应。之前在高斯嵌入方面的工作也表明,映射到密度可以捕获表示的不确定性(Vilnis和McCallum,2014),并表示自然不对称性(Qian等人,2021),同时显示出更好的泛化,用更少的数据来实现最佳绩效(Bojchevski和Günnemann,2017)。受高斯嵌入的这些独特特性的启发,在这项工作中,我们利用高斯embedding进行对比学习for few-shot。评估期间的最近邻分类方案显示,平均而言,CONTAINER在广泛的测试中显著优于之前的SOTA方法,其F1绝对分数高达13%。特别是,我们根据Yang和Katiyar(2020)在各种数据集(CoNLL'03,OntoNotes 5.0,WNUT'17,I2B2),在域内和域外实验中广泛测试了我们的模型。我们还在提出的一个大型数据集Few-Shot NERD(Ding等人,2021)中测试了我们的模型,其中CONTAINER优于所有其他SOTA方法,在排行榜上设定了一个新的基准结果
综上所述,我们的贡献如下:
(1)CONTAINER利用对比学习来推断其高斯embedding的分布距离。
(2)CONTAINER representation更适合于适应看不见的新类,即使支持样本数量较少
2 Task Formulation
2.1 few-shot设置
训练集和测试集tag没有交集,N-wayK-shot表示测试集tag数量为N,每一个tag有K个examples

2.2 标记方案
遵循IO标记方案,其中I-type表示所有标记都在一个实体内,O-type表示所有其他标记
2.3 评估方案
在此,通过计算多个测试集的micro-F1分数来评估模型。每集由一个K-shot support set和一个K-shot unlabeled (test)set组成做出预测。从原始开发集中抽取多个支持集,用它们进行预测。
3. 方法
CONTAINER利用对比学习来优化不同标记实体表示之间的分布差异。没有关注特定标签的属性,而是显式地训练模型来区分不同类别的标记。
此外,高斯embedding代替传统的point representation可以有效地让CONTAINER对实体类分布进行建模,从而激发标记的广义表示。
最后,它允许我们仔细微调我们的模型,即使使用少量样本,也不会过度拟合,这对于域自适应来说是必不可少的。
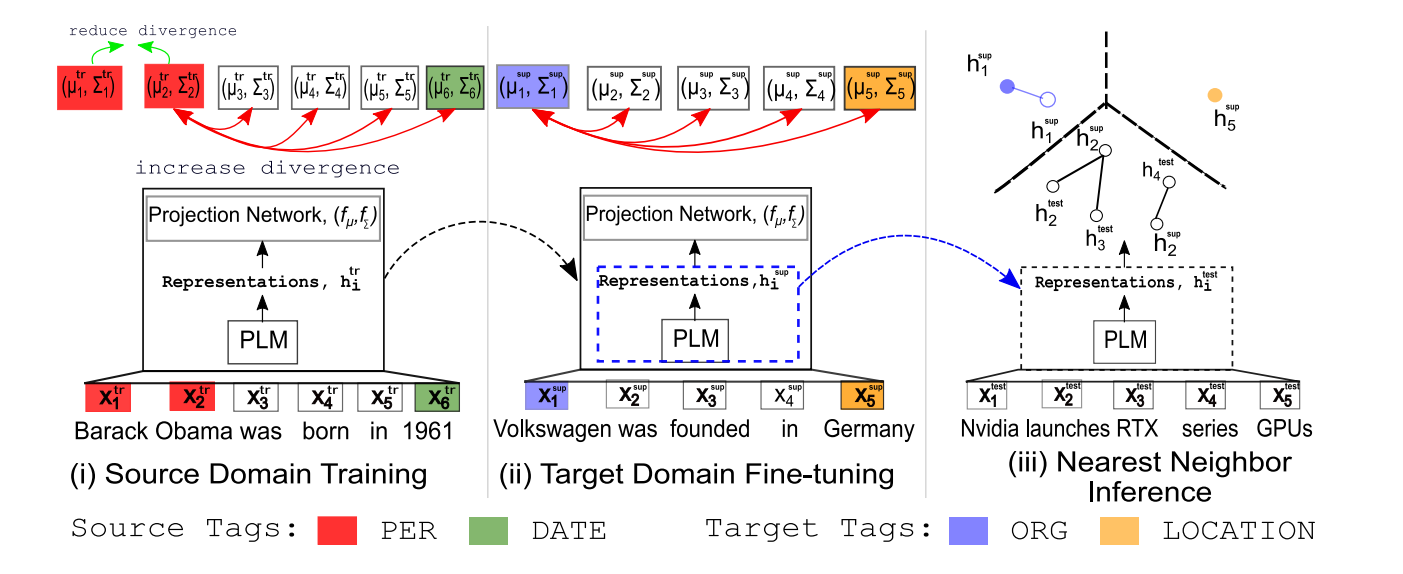
如图2所示,我们首先在源域中训练模型。接下来,我们使用几个示例支持集对模型表示进行微调,以使其适应目标域。算法1说明了容器的训练和微调。最后,我们使用实例级最近邻分类器在测试集中进行推理。
3.1 模型

用BERT作为PLM编码器。因此,给定n个token序列[x1,x2,…,xn],我们将PLM的最终隐藏层输出作为中间表征
然后,这些中间表示通过简单的投影层传递,以生成embedding,我们假设token embedding遵循高斯分布。我们使用投影网络fµ和f∑来生成高斯分布参数:

mu和sigma表示平均值和对角协方差(仅含非零元素分别沿矩阵的对角线)的高斯嵌入


3.2 Training in Source Domain

为了计算对比损失,我们考虑了样本批次中所有有效token对之间的KL散度,两个token如果有相同的label,那么就被视为positive样本
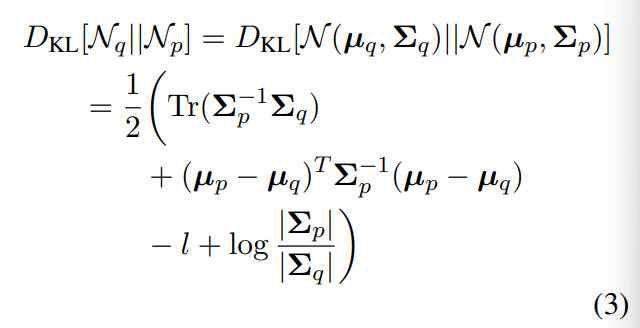
KL散度的两个方向都是计算的,因为它是不对称的。
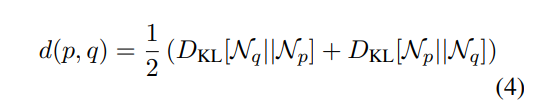
我们首先在资源丰富的源域中,Xtr的训练我们的模型。在每个训练步骤中,我们随机抽取一批序列X∈ 来自训练集中的Xtr,每个批次大小为b,我们通过将相应的token序列通过模型获得其高斯嵌入N(µi,∑i)。
我们在批次中找到样本p的正样本Xp,然后计算Xp相对于批次中所有其他有效token的高斯embedding损失:
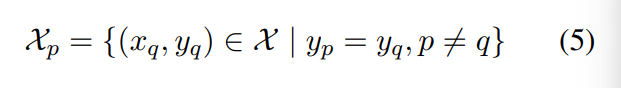
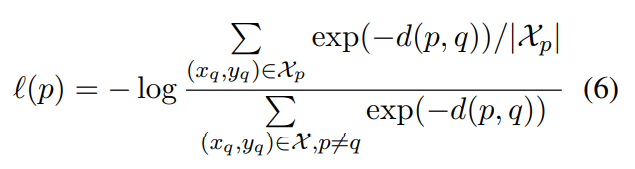
通过这种方式,我们计算批次中所有token对的分布散度,X表示所有token对,分母项表示正集,分子项目表示在token对中,除了自己对以外的对。
3.3 Finetuning to Target Domain using Support Set
在源域中进行训练后,我们使用少量目标域支持样本,按照与训练阶段类似的步骤对模型进行微调。由于我们只有少量样本可供微调,所以我们将其化为single batch。当目标类有多个few-shot sample(例如,5-shot)可用时,模型可以通过优化高斯embedding的KL散度有效地适应新域
相比之下,对于1-shot的情况,模型适应目标类分布的难度很大。如果模型没有关于目标类的先验知识,单个示例可能不足以推断目标类分布的方差。因此,对于one-shot场景,我们优化了

嵌入分布均值之间的平方欧氏距离。当模型对所涉及的目标类别有直接/间接的先验知识时,我们仍然会优化分布的KL散度,类似于5-shot场景。
我们在表7中证明,使用平方欧几里德距离进行优化可以使我们在one-shot场景中获得更好的性能。
然而,在所有情况下,在5-shot支持集下,优化高斯embedding之间的KL散度可以得到最好的结果。
3.3.1 Early Stopping
使用较小的支持集进行微调,则会有过度拟合的风险,并且由于目标域中的数据不足,无法访问保留的验证集,因此我们无法跟踪需要停止微调的饱和点。为了缓解这种情况,我们计算出对比损失,并将其作为我们的早期停止标准,previous_score=1e+6

3.4 Instance Level Nearest Neighbor Inference
在分别使用训练数据和支持数据对网络进行训练和微调后,提取预训练的语言模型编码器PLM进行推理。与SimCLR(Chen et al.,2020)类似,我们发现投影层之前的 representations实际上包含比最终输出表示更多的信息,这有助于提高性能,因此fµ和f∑投影头不用于推理。因此,我们计算PLM中测试数据的表示,并找到用于推理的最近邻支持集表示

对于每一个support token求出的表征h(j,sup) from support set,对于每一个test token求出的表征h(j,test) from test set,我们为在最近邻PLM的表征空间里为x(i,test)分配与support token相同的label
3.4.1 Viterbi Decoding
之前的大多数工作都注意到使用CRF可以消除错误预测以提高性能,从而提高了性能。因此我们还在推理阶段使用维特比解码,并使用StructShot中的抽象转移分布。对于转移概率,通过计算三个抽象标记O、I和I-other在训练集中的出现次数来估计它们之间的转移。然后,对于目标域标记集,将这些转移概率均匀分布到相应的目标分布中. 对于发射概率,通过近邻推断计算。将领域迁移结果(表3)于其它任务(表2,4,5)比较,作者发现,如果测试数据中没有涉及明显的领域迁移,对比学习允许CONTaiNER自动抽取标签依赖,避免了额外维特比解码阶段的要求















 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









