







01论文核心
这篇文章是关于zero-shot背景下的细粒度NER问题,zero-shot的场景,论文中设定的是,train和test数据集的type无交集,train的type是高粒度的,而test的type是细粒度,是train的type的细粒度化。
文章做了什么?:研究了不同的信息的融合方法;研究了不同的信息对于该任务的作用效果;
不同信息是:上下文背景信息,实体类型层次结构,背景知识信息(wiki这种)
02 论文背景
Fine-grained entity typing (FET) aims to detect
the types of an entity mention given its context
外部信息引入:

03 论文模型
a Multi-Source Fusion model (MSF) 三模块:
- CA (Context-Consistency Aware) module, we measure the context consistency by large-scale pretrained language models, e.g., BERT
- HA (Type-Hierarchy Aware) module, we use Transformer encoder (Vaswani et al., 2017) to model the hierarchical dependency among types.
- KA (Background-Knowledge Aware) module, we introduce prototypes (Ma et al., 2016) and WordNet descriptions (Miller, 1995) as background knowledge of types
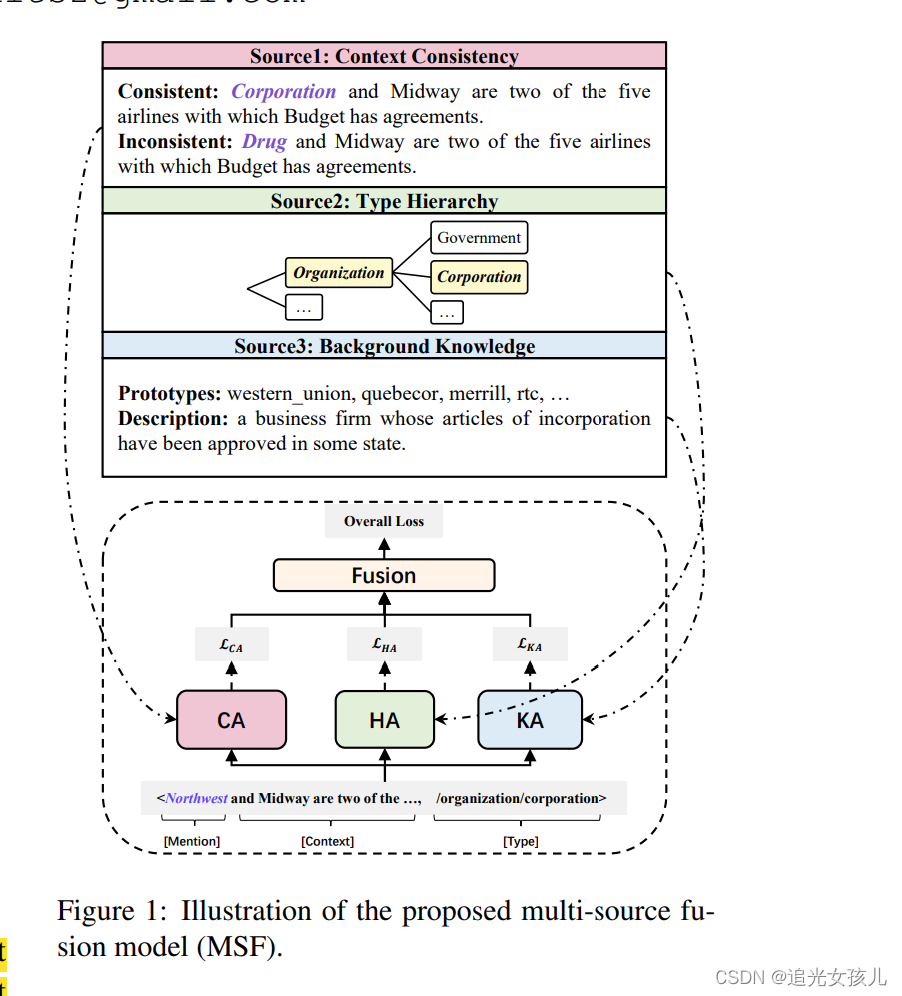
1 CA模块:
encode:bert
输入:text which mask the corrsponding entity mention
输出:the entity type of the masked position
补充:the number of [mask] tokens decides on the length of type names
损失函数:loss function = score function: the average probablity of the token n of type t:

2 HA模块:
- mention and contexts:在训练阶段,encoder编码,concat作为final representation。
在推理阶段,计算similarity分值,判断mention和type是否搭配。 encoder:Elmo - Hierarchy-Aware Type Encode
hierarchical information, we perform the mask selfattention operation on types,a type only attends to its parent type in the hierarchy and itself, while the attention to the remaining types will be masked
(type通过mask机制,只能attend to 和它有关系的父节点的type。)
3.loss function
(1)矩阵映射mention和type到同一个空间。
(2)计算mention和每一个type的match score
(3)计算loss function(cross-entropy)

3 Background Knowledge-Aware (KA) Module
- Prototypes refer to the carefully selected mentions for a type based on Normalized Point-wise Mutual Information (NPMI)——原型(每个type下的部分mention构成的集合)
- Descriptions are queried from WordNet glosses
(Miller, 1995) by type names
任务描述:
infer whether a mention m matches a candidate type t, given the prototypes, type description and the context.
具体细节
encoder:同module 2
信息表示:
rmc-mention&context
rtp-type&prototype
rh-type&mention
信息映射:
将所有的信息映射到统一的向量空间;
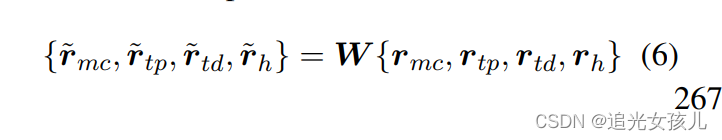
损失函数:
借鉴了TransE的思想:

整个过程的训练损失——三个module之和
推理阶段
单独计算三个module的score,再计算score之和。作为评价依据。

04 论文实验
消融实验
Ablations of CA:CA模块是否finetune
Ablations of HA:HA采用不同的encoder
Ablations of KA:是否采用prototype和description
在不同长度文本上,不同模块的效果
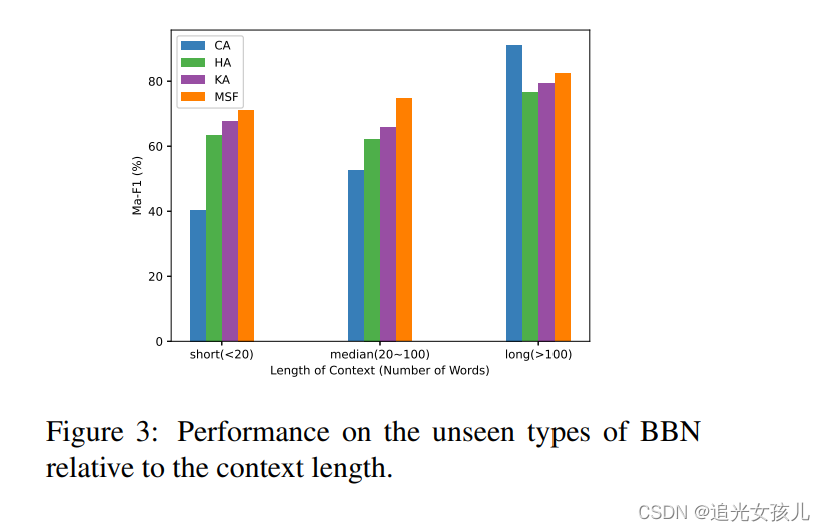
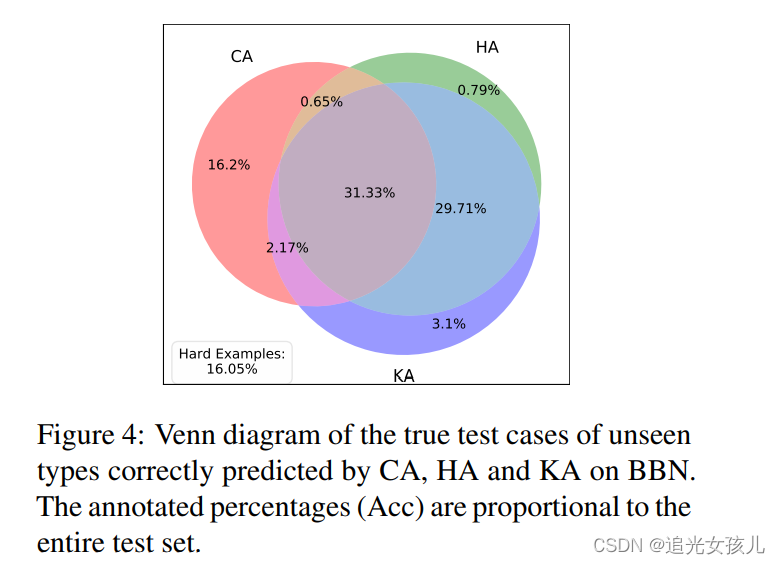
在test数据集上,不同模块的效果















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











