







三、动态规划
1.介绍
动态规划(Dynamic Programming,DP)是一类优化算法
动态规划将待求解问题分解成若干的子问题,先求解子问题,然后从这些子问题的解得到目标问题的解。
核心特点:
- 最优子结构:子问题的最优解是可以得到的
- 重复子问题:子问题的解决方案可以存储和重用
动态规划与强化学习
在完备的马尔可夫决策过程中,DP可用于计算最优策略。完备是指 P s s ′ a \mathcal P_{ss^\prime}^a Pss′a和 R s a R_s^a Rsa已知
对于强化学习问题,传统的DP算法作用有限:
- 完备的环境模型只是一个假设
- 计算复杂度极高
但是DP提供了必要的基础,所有其他方法都是对DP的近似
- 降低计算复杂度
- 减弱对环境模型完备性的假设
基于动态规划的强化学习
策略迭代(Policy iteration):使用贝尔曼期望方程,求解最优策略,包含两个核心步骤:
- 策略评估(Policy evaluation):输入 M D P ( S , A , P , R , γ ) MDP(S,A,P,R,\gamma) MDP(S,A,P,R,γ)和策略 π \pi π,输出价值函数 v π v_\pi vπ
- 策略提升(Policy Improvement):输入 M D P ( S , A , P , R , γ ) MDP(S,A,P,R,\gamma) MDP(S,A,P,R,γ)和价值函数 v π v_\pi vπ,输出最优价值函数 v ∗ v_* v∗和最优策略 π \pi π
价值迭代(Value iteration):使用贝尔曼最优方程,求解最优策略
2.策略评估
迭代策略评估
**问题:**评估一个给定的策略 π \pi π,也称为“预测”问题
**解决方案:**迭代应用贝尔曼期望方程进行回溯
v
1
→
v
2
→
⋯
→
v
π
∀
s
:
v
k
+
1
(
s
)
←
E
π
[
R
t
+
1
+
γ
v
k
(
S
t
+
1
)
∣
S
t
=
s
]
v_1 \rightarrow v_2 \rightarrow \dots \rightarrow v_\pi \\\\\forall s: \quad v_{k+1}(s) \leftarrow \mathbb{E}_\pi\left[R_{t+1}+\gamma v_k\left(S_{t+1}\right) \mid S_t=s\right]
v1→v2→⋯→vπ∀s:vk+1(s)←Eπ[Rt+1+γvk(St+1)∣St=s]
不断地用老的打分器去更新新的打分器,算法会收敛到
v
π
v_\pi
vπ
算法流程:
输入待评估的策略 π \pi π
算法参数:小阈值 θ > 0 \theta > 0 θ>0,用于确定估计量的精度
对于任意 s ∈ s + s \in s^+ s∈s+,任意初始化 V ( s ) V(s) V(s),其中 V ( 终止状态 ) = 0 V(终止状态)=0 V(终止状态)=0
循环:
- Δ ← 0 \Delta \leftarrow 0 Δ←0
- 对每一个
s
∈
S
s \in S
s∈S循环:
- v ← V ( s ) v \leftarrow V(s) v←V(s)
- V ( s ) ← ∑ a ∈ A π ( a ∣ s ) ( R s a + γ ∑ s ′ ∈ S P s s ′ a V ( s ′ ) ) V(s) \leftarrow \sum_{a \in \mathcal A}\pi(a \mid s)(\mathcal{R}_s^a+\gamma \sum_{s^{\prime} \in \mathcal{S}} \mathcal{P}_{s s^{\prime}}^a V\left(s^{\prime}\right)) V(s)←∑a∈Aπ(a∣s)(Rsa+γ∑s′∈SPss′aV(s′))
- Δ ← m a x ( Δ , ∣ v − V ( s ) ∣ ) \Delta \leftarrow max(\Delta, |v-V(s)|) Δ←max(Δ,∣v−V(s)∣)
直到 Δ < θ \Delta < \theta Δ<θ
示例:
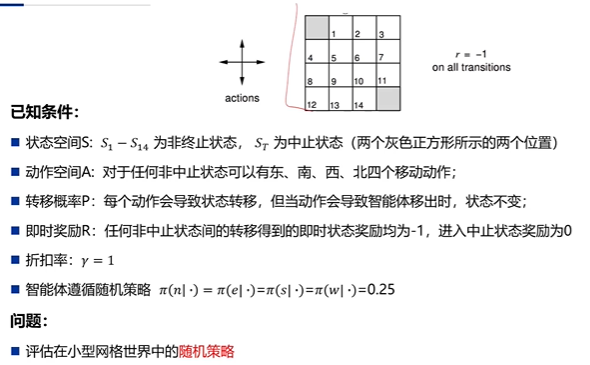

3.策略迭代
**问题:**如何获得最优策略?
**回答:**策略迭代方法,交替迭代下述步骤:
- 评估给定的策略 π \pi π,获得价值函数
v π ( s ) = E π [ R t + 1 + γ R t + 2 + ⋯ ∣ S t = s ] v_\pi(s)=\mathbb E_\pi[R_{t+1} + \gamma R_{t+2}+ \dots \mid S_t=s] vπ(s)=Eπ[Rt+1+γRt+2+⋯∣St=s]
- 应用贪婪方法来改进策略,使其后续状态价值增加最多
π ′ = g r e e d y ( v π ) \pi^\prime=greedy(v_\pi) π′=greedy(vπ)
在小型网格世界中,改进后的策略就是最佳的策略, π ′ = π ∗ \pi^\prime=\pi^* π′=π∗
但是更多的场合中,我们需要进行多次的评估和改进迭代,才能找到最优策略
上述算法一般都能收敛至最佳策略 π ∗ \pi^* π∗
如果改进停止,
q
π
(
s
,
π
′
(
s
)
)
=
max
a
∈
A
q
π
(
s
,
a
)
=
q
π
(
s
,
π
(
s
)
)
=
v
π
(
s
)
q_\pi\left(s, \pi^{\prime}(\mathrm{s})\right)=\max _{a \in A} q_\pi(s, a)=q_\pi(s, \pi(\mathrm{s}))=v_\pi(s)
qπ(s,π′(s))=a∈Amaxqπ(s,a)=qπ(s,π(s))=vπ(s)
满足贝尔曼最优方程
max
a
∈
A
q
π
(
s
,
a
)
=
v
π
(
s
)
\max _{a \in A} q_\pi(s, a)=v_\pi(s)
a∈Amaxqπ(s,a)=vπ(s)
此时,对于所有的
s
∈
S
,
v
π
(
s
)
=
v
∗
(
s
)
s \in S, v_\pi(s)=v_*(s)
s∈S,vπ(s)=v∗(s)
所以, π \pi π是最优策略
策略迭代的相关讨论
策略评估需要收敛到 v π v_\pi vπ吗?在k次迭代策略评估后停止?
- 比如在小型网格世界中, k = 3 k=3 k=3就可以输出最优策略
为什么不每次迭代都更新策略,即k=1?
- 这等效于价值迭代
4.价值迭代

价值迭代流程
**问题:**找到一个最优的策略 π \pi π
**方法:**迭代应用贝尔曼最优方程进行回溯
∀
s
:
v
k
+
1
(
s
)
←
max
a
(
R
s
a
+
γ
∑
s
′
∈
S
P
s
s
′
a
V
(
s
′
)
)
\forall s:v_{k+1}(s) \leftarrow \max_a (\mathcal{R}_s^a+\gamma \sum_{s^{\prime} \in \mathcal{S}} \mathcal{P}_{s s^{\prime}}^a V\left(s^{\prime}\right))
∀s:vk+1(s)←amax(Rsa+γs′∈S∑Pss′aV(s′))
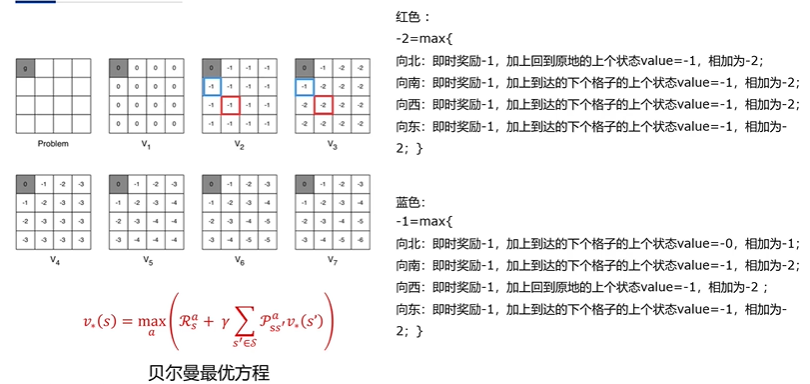
最终可以收敛于最优价值函数
v
∗
v_*
v∗
迭代过程中得到的价值函数可能不符合任何策略
5.参考资料
强化学习基础 北京邮电大学 鲁鹏 强化学习基础 (本科生课程) 北京邮电大学 鲁鹏_哔哩哔哩_bilibili
深度强化学习 台湾大学 李宏毅 DRL Lecture 1_ Policy Gradient (Review)_哔哩哔哩_bilibili
蘑菇书EasyRL datawhalechina/easy-rl: 强化学习中文教程(蘑菇书),在线阅读地址:https://datawhalechina.github.io/easy-rl/

















 2322
2322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









