







论文阅读:Generation-Augmented Retrieval for Open-Domain Question Answering
来源:ACL 2021
下载地址:https://arxiv.org/pdf/2009.08553.pdf
本文主要贡献:
(1) 我们提出了 GenerationAugmented Retrieval (GAR),它通过文本生成以启发式发现的相关上下文来增强查询,而无需外部监督或耗时的下游反馈。
(2) 我们表明,与使用原始查询或现有的无监督 QE 方法相比,使用生成增强查询可以显着提高检索和 QA 结果。
(3) 我们展示了 GAR 与简单的 BM25 模型相结合,在抽取式 OpenQA 的两个基准数据集上实现了新的最先进的性能,并在生成环境中取得了竞争性结果。
Abstract
提出了用于回答开放域问题的生成增强检索 (GAR),它通过在没有外部资源作为监督的情况下通过启发式发现的相关上下文的文本生成来增强查询。生成的上下文极大地丰富了查询的语义,而具有稀疏表示的 GAR (BM25) 与最先进的密集检索方法(例如 DPR)(Karpukhin 等人,2020)相比具有可比或更好的性能。为查询生成不同的上下文是有益的,因为融合它们的结果始终可以产生更好的检索准确性。此外,由于稀疏和密集表示通常是互补的,GAR 可以很容易地与 DPR 结合以实现更好的性能。 当配备抽取式阅读器时,GAR 在抽取式 QA 设置下的自然问题和 TriviaQA 数据集上实现了最先进的性能,并且在使用相同的生成式阅读器时始终优于其他检索方法。
Introduction
在 OpenQA 中,通常使用大量文档(例如 Wikipedia)来寻找与问题有关的信息。最常见的方法之一是使用检索器-阅读器架构(Chen 等人,2017 年),它首先使用问题作为查询来检索一小部分文档,然后读取检索到的文档以提取(或生成)答案。检索器至关重要,因为检查整个文档集合(例如,数百万个维基百科段落)中的每条信息是不可行的,并且检索准确性限制了(提取)阅读器的性能。
在本文中,我们提出了 GenerationAugmented Retrieval (GAR),它通过预训练语言模型 (PLM) 的文本生成来增强查询。与之前重新制定查询的研究不同,GAR 不需要外部资源或通过 RL 作为监督的下游反馈,因为它不会重写查询,而是使用启发式发现的相关上下文对其进行扩展,这些上下文从 PLM 中获取并提供更丰富的背景信息。例如,通过提示 PLM 生成给定查询的相关段落的标题并将生成的标题附加到查询中,检索该相关段落变得更加容易。 直观地说,生成的上下文明确表达了原始查询中未呈现的搜索意图。 因此,具有稀疏表示的 GAR 与具有原始查询的密集表示的最先进方法(Karpukhin 等人,2020 年;Guu 等人,2020 年)相比,实现了相当甚至更好的性能,同时在训练和推理方面(包括生成模型的成本)都是更轻量级并且有效的。
具体来说,我们通过添加相关上下文来扩展查询(问题),如下所示。 我们以问题作为输入,各种可自由访问的域内上下文作为输出进行 seq2seq 学习,例如答案、答案所属的句子以及包含答案的段落的标题。然后,我们将生成的上下文作为检索的生成增强查询附加到问题中。 我们证明,使用来自不同生成目标的多个上下文是有益的,因为融合不同生成增强查询的检索结果始终可以产生更好的检索准确性。
Related Work
Conventional Query Expansion
GAR 与基于伪相关反馈的查询扩展 (QE) 方法具有一些优点,因为它们都使用相关上下文(术语)扩展查询,而无需使用外部监督。 GAR 的优势在于它使用存储在 PLM 中的知识而不是检索到的段落来扩展查询,并且它的扩展术语是通过文本生成来学习的。
Retrieval for OpenQA
现有的 OpenQA 稀疏检索方法仅依赖于问题的信息。 GAR 通过提取 PLM 中的信息扩展到与问题相关的上下文,并帮助稀疏方法实现与密集方法相当或更好的性能,同时享受稀疏表示的简单性和效率。
Generative QA
生成式 QA 通过 seq2seq 学习生成答案,而不是提取答案跨度。 最近关于生成式 OpenQA 的研究与 GAR 不同,因为它们专注于改善阅读阶段并直接重用 DPR作为检索器。与生成式 QA 不同,GAR 的目标不是生成问题的完美答案,而是生成有助于检索的相关上下文。生成式 QA 中的另一条线学习在没有相关段落作为证据的情况下生成答案,而仅使用 PLM 生成问题。 GAR 进一步证实,人们可以从 PLM 中提取事实知识,这不仅限于先前研究中的答案,还包括其他相关上下文。
Generation-Augmented Retrieval
Task Formulation
OpenQA 旨在回答没有预先指定领域的事实性问题。 我们假设给定大量文档 C(即 Wikipedia)作为回答问题的资源,并使用检索器-阅读器架构来解决该任务,其中检索器检索文档 D ⊂ C 的一小部分,并且阅读器阅读文档 D 以提取(或生成)答案。我们的目标是提高检索器的有效性和效率,从而提高阅读器的性能。
Generation of Query Contexts
在 GAR 中,使用各种启发式发现的相关上下文来增强查询,以便在数量和质量方面检索更多相关的段落。对于查询是问题的 OpenQA 任务,我们将以下三个可自由访问的上下文作为生成目标。
Context 1:The defualt target(answer)
默认目标是感兴趣任务中的标签,即 OpenQA 中的答案。 问题的答案显然对于检索包含答案本身的相关段落很有用。一些之前的工作显示,PLM 能够仅通过将问题作为输入来回答某些问题(即闭卷 QA)。GAR 不像在闭卷 QA 中那样直接使用生成的答案,而是将它们视为问题的上下文以进行检索。 优点是即使生成的答案部分正确(甚至不正确),只要它们与包含正确答案的段落相关(例如,与正确答案同时出现),它们仍然可能有助于检索。
Context 2:Sentence containing the defualt target
包含答案的段落中的句子被作为另一个生成目标。 与使用答案作为生成目标类似,即使生成的句子不包含答案,它们仍然有利于检索相关段落,因为它们的语义与问题/答案高度相关。 根据参考质量和多样性之间的权衡,可以将真实段落中的相关句子(如果有)或检索器的正面段落中的相关句子作为参考。
Context 3:Title of passage containing the default target
如果可用,也可以使用相关段落的标题作为生成目标。具体来说,我们使用 BM25 以问题为查询检索 Wikipedia 段落,并将包含答案的正面段落的页面标题作为生成目标。 我们观察到正面段落的页面标题通常是感兴趣的实体名称,有时(但不总是)是问题的答案。 直观地说,如果 GAR 知道该问题与哪些 Wikipedia 页面相关,那么由生成的标题增强的查询自然会有更好的机会检索这些相关段落。
Retrieval with Generation-Augmented Queries
在生成查询的上下文后,我们将它们附加到查询中以形成生成增强查询。我们观察到,将生成的上下文(例如答案)单独作为查询而不是串联进行检索是无效的,因为(1)一些生成的答案是不相关的,(2)仅由正确答案(没有问题)组成的查询可能会检索到带有恰好包含答案的不相关上下文的错误段落。 这种低质量的段落可能会导致后续文章阅读阶段的潜在问题。
如果有多个查询上下文,我们分别使用具有不同生成上下文的查询进行检索,然后融合它们的结果。 附加所有上下文的一次性检索的性能略有下降,但没有明显变差。为简单起见,我们以一种直接的方式融合检索结果:从每个来源的顶部检索到的段落中提取相等数量的段落。接下来,可以使用任何现成的检索器进行段落检索,在这里,我们使用一个简单的 BM25 模型。
OpenQA with GAR
Extractive Reader
对于提取设置,我们在很大程度上遵循 DPR 中提取阅读器的设计。 令 D = [d1,d2,…, dk] 表示检索到的具有段落相关性分数 D 的段落列表。令 Si = [s1,s2, …, sN] 表示段落 di 中的前 N 个文本跨度,按跨度相关性分数 Si 排序。 最后,从具有最高段落相关性分数的段落中选择具有最高跨度相关性分数的跨度作为答案。
Passage-level Span Voting
我们提出了一种简单而有效的段落级跨度投票机制,它聚合了来自不同检索段落的相同表面形式的跨度预测。直观地说,如果一个文本跨度在不同的段落中多次被认为是答案,那么它更有可能是正确的答案。 具体来说,GAR 在推理过程中为段落 di 中的第 j 个跨度计算归一化分数 p(Si[j]),如下所示:p(Si[j]) = softmax(D)[i] × softmax(Si)[j]。 然后,GAR 将所有检索到的段落中具有相同表面字符串的跨度的分数聚合为集体段落级别分数。
Generative Reader
对于生成设置,我们使用 seq2seq 框架,其中输入是问题和顶部检索到的段落的连接,目标输出是期望的答案。具体来说,我们使用 BART-large 作为生成阅读器,它将问题和顶部检索到的段落连接起来,直到其长度限制(1,024 个标记,平均 7.8 个段落)。
Experiment Setup
Datasets
Natural Questions (NQ) (Kwiatkowski et al., 2019) 和 TriviaQA (Trivia) (Joshi et al., 2017),如表1。
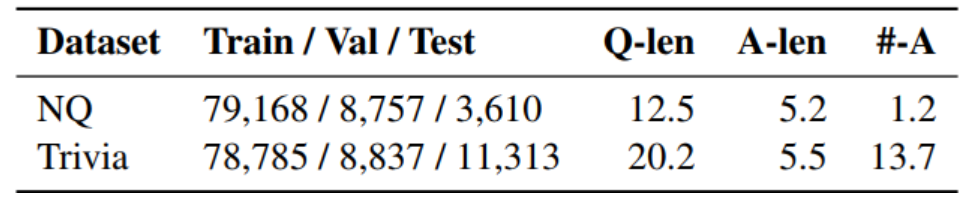
表 1:显示每个数据拆分的样本数、平均问题(答案)长度和每个问题的答案数的数据集统计数据。
Implementation Details
Retriever
我们使用 Anserini (Yang et al., 2017) 使用默认参数对 BM25 和 GAR 进行文本检索。 我们对 QE baseline RM3 进行网格搜索(Abdul-Jaleel 等,2004)。
Generator
我们使用 BART-large 在 GAR 中生成查询上下文。 当有多个期望的目标(例如多个答案或标题)时,我们将它们与 [SEP] 标记连接起来作为参考,并在生成增强查询中删除 [SEP] 标记。 特别是对于 Trivia,我们使用 value 字段作为答案的生成目标,可以观察到更好的性能。
Reader
抽取式 GAR 使用具有基本相同超参数的 DPR 阅读器,该超参数使用 BERT-base 进行初始化,并在训练(推理)期间获取 100 (500) 个检索到的段落。 生成式 GAR 将问题和检索到的前 10 个段落连接起来,最多接受 1,024 个标记作为输入。 所有生成模型都采用贪婪解码,这与波束搜索类似。
Experiment Results
Query Context Generation
Automatic Evalution
为了评估生成的查询上下文的质量,我们首先测量它们与真实查询上下文的词汇重叠。 正如表 2中的 ROUGE 分数所示的,GAR 确实学会了生成有意义的查询上下文,这有助于检索阶段。我们接下来测量了查询和真实段落之间的词汇重叠。结果进一步表明,生成的查询上下文显着增加了查询和肯定段落之间的单词重叠,因此可能会改善检索结果。

表 2:在 NQ 数据集的验证集上生成的查询上下文的 ROUGE F1 分数。
Case Studies
在表 3 中,我们展示了生成的查询上下文及其真实参考的几个示例。 在第一个示例中,正确的专辑发行日期出现在生成的答案和生成的句子中,并且生成的标题与专辑的维基百科页面标题相同。在最后两个示例中,生成的答案是错误的,但幸运的是,生成的句子包含正确答案和(或)其他相关信息,并且生成的标题也与问题高度相关,这表明不同的查询上下文是互补的,从而减少了查询上下文生成期间的噪声。

表 3:生成的查询上下文示例。 相关和不相关的上下文以绿色和红色显示。 Ground-truth references显示在 {braces} 中。 通过生成与问题/答案高度相关的其他上下文来缓解生成错误答案的问题。
Generation-Augmented Retrieval
Comparison w. the state-of-the-art
我们接下来评估 GAR 检索的有效性。在表 4 中,我们展示了 BM25、BM25 with query expansion (+RM3) (Abdul-Jaleel et al., 2004)、DPR (Karpukhin et al., 2020)、GAR 和 GAR+ (GAR+DPR) 的 top-k 检索精度。

表 4:测试集上的 Top-k 检索精度。 基线由我们自己评估,比 Karpukhin 等人报告的要好(2020 年)。 GAR 帮助 BM25 实现与 DPR 相当或更好的性能。最佳和次佳方法分别用粗体和下划线表示。
在 NQ 数据集上,尽管无论检索到的段落数量如何,BM25 的性能都明显低于 DPR,但当 k ≥ 100 时,GAR 和 DPR 之间的差距明显更小且可以忽略不计。当 k ≥ 500 时,GAR 略好于 DPR,尽管它只是使用 BM25 进行检索。 相比之下,经典的 QE 方法 RM3 虽然显示出比普通 BM25 略有改进,但没有达到与 GAR 或 DPR 可比的性能。通过以前面所述相同的方式融合 GAR 和 DPR 的结果。我们进一步获得了比这两种方法更高的性能,top-100 准确度为 88.9%,top1000 准确度为 93.2%。
在 Trivia 数据集上,结果更令人鼓舞——当 k ≥ 5 时,GAR 始终比 DPR 实现更好的检索精度。另一方面,BM25 和 BM25 +RM3 之间的差异可以忽略不计,这表明天真地考虑排名靠前的段落 与 QE 相关(即伪相关反馈)并不总是适用于 OpenQA。
Effectiveness of diverse query contexts
在图 1 中,我们展示了当使用不同的查询上下文来增强查询时 GAR 的性能。 尽管使用每个查询上下文时的个体性能有些相似,但融合它们检索到的段落始终会带来更好的性能,这证实了不同的生成增强查询是相互补充的。

图 1:融合不同生成增强查询的检索结果时,NQ 测试集上的 Top-k 检索精度。
Performance breakdown by question type
在表 5 中,我们显示了 NQ 测试集上每种问题类型的比较检索方法的前 100 位准确度。 再次,GAR 在所有类型的问题上都显着优于 BM25,并且 GAR+ 实现了全面的最佳表现,这进一步验证了 GAR 的有效性。

表 5:NQ 上问题类型的 Top-100 检索准确率细分。 每个类别中的最佳和次佳方法分别用粗体和下划线表示。
Passage Reading with GAR
Comparison w. the state-of-the-art
我们在表 6 中展示了抽取式和生成式方法的端到端 QA 性能的比较。抽取式 GAR 在 NQ 和 Trivia 数据集上的抽取式方法中实现了最先进的性能。Generative GAR 在 Trivia 上的表现优于大多数生成方法,但在 NQ 上表现不佳,这在某种程度上是意料之中的,并且与检索阶段的表现一致,因为生成式阅读器仅将少数段落作为输入,而 GAR 并不优于当 k 非常小时,NQ 上的密集检索方法。然而,将 GAR 与 DPR 相结合比使用 DPR 作为输入的方法或 baseline 获得了显着更好的性能。此外,GAR 在提取和生成设置下都显着优于 BM25,这再次显示了生成的查询上下文的有效性,即使它们是在没有任何外部监督的情况下以启发式方式发现的。

表 6:与 EM 中最先进方法的端到端比较。 对于 Trivia,左列表示开放域测试集,右列是公共排行榜上的隐藏 Wikipedia 测试集。
Model Generalizability
最近的研究(Lewis 等人,2020b)表明,流行的 OpenQA 数据集的训练集和测试集之间存在显着的问答重叠。具体来说,60% 到 70% 的测试答案也出现在训练集中,大约 30% 的测试集问题在训练集中有几乎重复的释义。 这些观察表明,许多问题可能已经通过简单的问题或答案记忆来回答。

表 7:在 NQ 上具有问答重叠类别细分的 EM 分数。 (E) 和 (G) 分别表示抽取式和生成式阅读器。 baseline 方法的结果取自 Lewis 等人。对 Trivia 的结果是相似的所以省略了。
如表 7 中所列,对于无重叠类别,GAR+ (E) 在提取设置上优于 DPR,GAR+ (G) 在生成设置上优于 RAG,这表明通过添加用于检索的 GAR可以实现更好的端到端模型泛化性。 GAR+ 还在“Answer Overlap Only”类别下获得了最佳 EM。 此外,我们观察到仅将问题作为输入的闭卷 BART 模型比另外采用顶部检索的段落(即 GAR+(G))的性能要差得多,尤其是在需要泛化性的问题上。 值得注意的是,所有方法在问题重叠类别上的表现都明显更好,这表明高的 Total EM 主要是由问题记忆造成的。 也就是说,鉴于该类别的 EM 较低,GAR+ 似乎不太依赖问题记忆。
Efficiency of GAR
GAR 高效且可扩展,因为它使用稀疏表示进行检索。GAR 的唯一开销是查询上下文的生成和生成增强(因此更长)查询的检索,其计算复杂度明显低于具有相当检索精度的其他方法。
Conclusion
在这项工作中,我们提出了生成增强检索,并证明了 PLM 在没有外部监督的情况下生成的相关上下文可以显着丰富查询语义并提高检索准确性。 值得注意的是,具有稀疏表示的 GAR 与基于原始查询的密集表示的最先进方法的性能相似或更好。 GAR 也可以很容易地与密集表示相结合,以产生更好的结果。 此外,GAR 在抽取式 OpenQA 上实现了最先进的端到端性能,并在生成式设置下实现了竞争性能。















 2791
2791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









