







Optimal Contract Design for Efficient Federated Learning With Multi-Dimensional Private Information论文笔记
摘要
- 文章主要研究的问题是联邦学习中用户存在多维度私人信息(训练成本和通信延迟)情况下的最优激励机制设计;
- 文章提出一个多维度的基于契约理论的方法,将用户多维度的私人信息归纳为一个一维的排序标准;
- 文章在三个场景下进行分析,揭示了信息不对称性对于用户最优策略和最小成本的影响;
- 通过分析发现,当训练数据是IID(independent identically distributed, 独立同分布)时,略微不完整的信息与完整的信息相比并没有增加中心服务器的成本,相反当训练数据不是IID时,上述现象会出现;
- 此外,信息严重缺失的情况下,最优机制设计是更具有挑战性的,这使得服务器用来激励用户参与联邦学习得训练成本和通信延迟并不永远是最优的。
介绍
背景
- 用户参与联邦学习需要付出一定的训练成本,积极性不高;
- 激励机制的设计需要用户多维度的信息,其中训练成本是用户的隐私,而通信延迟取决于用户的设备参数和使用时间;
- 目前相关研究只针对用户的单一信息进行激励机制设计,尚没有针对多维度信息激励机制设计的研究;
- 在信息不对等程度不同的情形下,用户为了追求更高的模型准确度,更低的成本,需要采取的最优策略不同;
- 现实中更常见的情况是不同用户使用数据服从的分布不同,针对独立同分布数据的研究不适用。
本文旨在解决三个问题:
如何刺激用户参与联邦学习?
服务器对用户隐私的了解如何影响其策略和成本?
服务器如何利用激励机制来最小化训练成本和付给用户的费用?
贡献
- 提出一个针对多维度私人信息的激励机制,并考虑不同程度的信息不对等性;
- 设计服务器的最优契约,将用户多维度的私人信息归纳为一个单一的衡量标准,以此确定服务器对于用户的偏好排序;
- 研究不同信息不对称程度下的契约设计;
- 将针对IID数据提出的模型迁移到non-IID数据上,评估模型的准确度损失。
相关研究
限制
- 目前的研究局限于用单一变量(时间成本、训练数据量等)建立成本和收益的数学模型;
- 目前的研究没有同时考虑不同信息不对称程度的场景;
- 目前的研究很少考虑non-IID数据的情况;
- 提出的激励机制无法产出考虑多维度信息的解决方案;
- 提出的算法无法得到封闭解(即解析解,给出解的具体函数形式,从解的表达式算出对应值)
改进
- 提出考虑多重变量的数学模型;
- 提出考虑多维度信息,且能得到封闭解的激励机制;
- 研究不同信息不对称程度的影响。
系统模型
联邦学习过程
文章的这一部分介绍了联邦学习的整个过程以及使用的同步联邦学习算法,比较容易理解。作者还在文中解释了为什么在算法中每一轮训练只有一次梯度更新。这是因为用户在上传模型参数时,受到上传带宽限制,需要较长的通信时间。而每一个用户的训练数据量较小,且大多数用户使用的智能手机都有高速处理器,需要的计算时间非常短。由此可知在实际的联邦学习应用场景下,每一轮训练中通信时间占主导地位。作者为了缩减实验中计算时间的比重,才在算法在每一次迭代中只进行一次梯度更新。
用户类型
文章在这一部分定义了用户的类型。用户依照二维信息进行分类,这两种信息分别是边际数据使用成本和通信时间。其中边际数据使用成本指的是每增加一次数据量所造成的计算总成本增量。
类型i的用户:
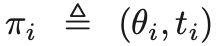
契约
文章在这一部分定义了服务器的契约,以及契约中供用户选择的条款。契约理论是研究在特定交易环境下,不同合同人之间的经济行为与结果,往往需要通过假定条件在一定程度上简化交易属性,建立模型来分析并得出理论观点。
契约:
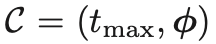
tmax: 最长通信时间,当用户上传或下载模型的时间超过这个值,条款作废,用户得到的回报为0
条款:定义了每个类型用户数据量大小si 和报酬ri 的关系,当用户选择了这一条款,即意味着用户如果能够提供规定的数据量进行训练,就能得到相应的报酬。
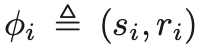
用户收益
收益:用户得到的报酬与其数据使用成本的差值(假设用户的数据使用成本与数据量成正比)
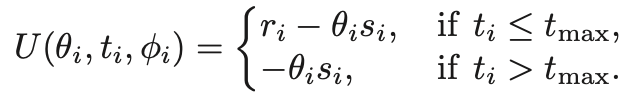
服务器成本
服务器的成本由全局模型准确度的损失以及服务器支付用户的费用决定。下面公式的前半部分代表全局模型准确度的损失,后半部分代表服务器支付用户的费用。

针对IID数据的多维度契约设计
契约可行性:当用户根据自身类型选择契约中对应的条款时,能够获得最大收益
契约最优性:该契约相比较其他契约能够最小化服务器的成本
信息完整的场景
在这种情况下,服务器清楚知道每个用户属于什么类型,只需要确保每个类型的用户会选择契约中对应的条款。
个体合理性(IR): 每个类型的用户都能获得非负收益,即U>=0
问题1:最小化服务器的成本
约束:IR
解决方法:首先对任意数据量si,求解用户能获得的最大报酬ri*(si);然后将ri*(si) 代入服务器成本目标函数求偏导解得最优解si* 和t*max。
引理1:对于任意数据量si,服务器报酬函数的最优选择如下
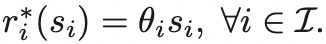
引理2:服务器只选择类型i用户的成本如下
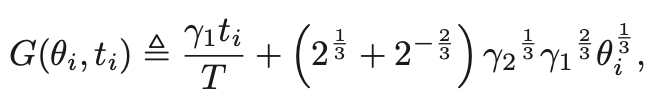
由此可以将用户的二维信息归纳为一个一维的衡量标准,用服务器只选择某种类型用户的成本值衡量服务器对该用户的偏好程度,成本越低,偏好越高。
定理1:给出信息完整场景下的最优契约设计Ccompleteopt

由定理1给出的最优契约设计可知,在信息完整的情况下,服务器只需要选择一个最偏好的用户类型,令该类型对应的契约条款有效,其他契约无效。因为可能存在多个最偏好的用户类型,最优契约设计并不唯一。另外,同时选择多个最优用户类型不是最优方案,反而会增大服务器成本。
信息略微缺失的场景
在这种情况下,服务器不知道哪个用户属于哪个类型,但知道每个类型用户的具体数目,主要关注设计一个契约只吸引最偏好的用户类型。
激励兼容性(IC): 用户选择符合自身类型的契约条款时可以最大化收益
问题2:最小化服务器的成本
约束:IR和IC
解决方法:首先将IR和IC两个约束转换为一系列等价不等式(引理3);然后由引理4得到服务器的最优报酬函数ri*(si);最后代回服务理的成本函数求偏导,得到最优解si* 和t*max。
引理3:

其中(a.1)不等式的作用是确保每个类型用户都能获得非负收益(IR);(a.2)不等式的含义是服务器会从边际数据使用成本小的用户索取更大的数据量,并相应地支付更高的报酬;(a.3)不等式的作用是确保用户选择符合类型的契约条款时获得的收益是最大的。
引理4:

定理2:Cw-incompleteopt等价于Ccompleteopt
信息严重缺失的场景
在这种情况下,服务器不知道每个用户类型的具体数目,只知道用户总数以及每个用户类型使用数据服从的概率分布。
用户属于类型i的概率为pi,则类型i用户的数目为ni 的概率如下:
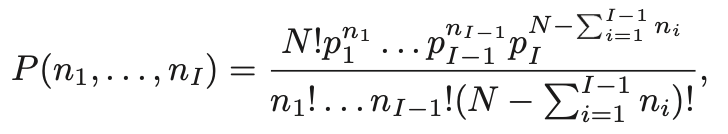
问题3:ni 的分布有很多种情况,每种情况概率不等,且每种情况对应一个服务器成本值。因此问题3的任务是最小化服务器成本的期望值。
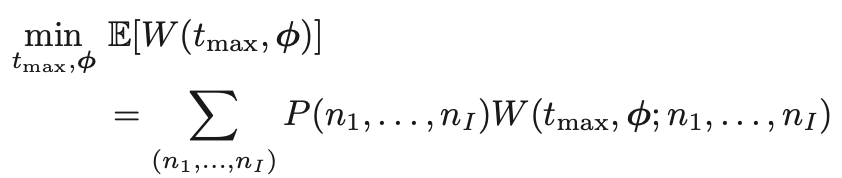
约束:IR和IC
难点:问题3不是一个凸优化问题,且没有封闭解;如果服务器沿用前两种情形下的最优契约设计,会出现选中的最偏好用户类型的用户数目为0,导致没有数据用于训练的情况。
解决方法:考虑一种Two-Part Uniform契约,即将所有用户类型对应的契约条款分为两部分,一部分有效,一部分无效;任意选择所有用户类型集合的一个子集,给出针对这一用户类型子集的最优契约设计Cs-incompleteTPU,opt(引理5);评估Cs-incompleteTPU,opt 的性能;最后给出寻找最佳用户类型子集的方法。
引理5:

定理3:给出了信息完整场景下服务器成本与信息严重缺失场景下TPU契约对应服务器成本差值的上界和下界

结论:随着用户数目增大,上界和下界的值都越来越小;当用户数目很大时,上界趋近于一个常数,这个常数主要由用户的边际数据成本决定,边际数据成本越大,常数越大。这意味着为了让信息严重缺失场景下TPU契约对应服务器成本接近信息完整场景下服务器成本,最佳用户类型子集应该尽量囊括边际数据成本较小的用户类型。
命题1:当用户数目趋近无穷大时,契约只需选择令一个最偏好用户类型对应的契约条款有效,就可以令与信息完整场景下服务器成本的差值为0。这是因为根据大数定律,当样本数量足够大时,任意用户类型的用户数目会趋近于用户数目的期望值,不可能为0,即不会遇到选择的用户类型没有训练数据的情况。
命题2:对于TPU契约来说,可能存在服务器对一个最佳用户类型子集中的用户类型的偏好程度低于对另一个不在最佳用户类型子集中的用户类型的偏好程度。这是因为一个偏好程度高但用户数目较少的用户类型并不一定优于另一个偏好程度稍低但用户数目更多的用户类型;并且由于服务器成本取决于最大通信时间和边际数据成本,几个高偏好程度用户类型的组合并不一定是最小化服务器成本的最优方案。
针对Non-IID数据的多维度契约设计
模型更新
Non-IID程度
我们用EMD(earth mover’s distance)来衡量不同用户类型数据分布的不统一性:
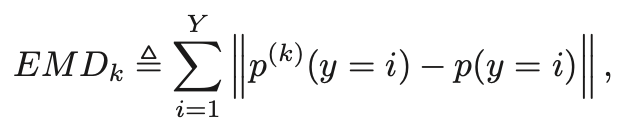
其中p(k)(y=i) 代表用户k的数据中标签为i的数据的比例,p(y=i) 代表所有用户中标签为i的数据的比例。所有用户的EMD平均值公式如下:

用户类型
由于拥有相同边际数据使用成本和通信时间的用户类型可能有不同的EMD值,原来的分类标准已经不再适用,需要重新定义。
类型i的用户:
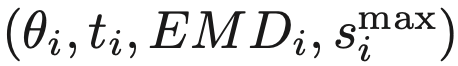
服务器成本
作者通过实验发现在训练次数较少时,所有用户的EMD均值取不同值时,non-IID数据训练的模型与IID数据训练的模型都有一个稳定的相对准确度损失,这个相对准确度损失随着EMD均值增大而增大。同时变换不同的实验条件后,这个相对准确度损失值没有发生太大的波动。作者将这个相对准确度损失值定义为一个系数,从而可以用IID数据训练模型的准确度损失来表示non-IID数据训练模型的准确度损失。

最优契约设计
服务器会选择一个用户类型子集,令这个集合中用户类型对应的契约条款有效,其余的契约条款无效。后面的分析将会基于下面的两个重要假设。
假设1:该子集中的每个用户诚实地向服务器报告其总数据量和EMD值,并且在自己的数据集中随机抽取一部分数据用来训练模型
假设2:服务器会要求该子集中的用户抽取相同比例的数据用于模型的训练
基于以上两个假设,服务器才可以计算出任意用户类型子集的EMD均值。
信息完整的场景
问题5:最小化服务器成本
约束:IR
引理6:定义了服务器选择该子集中用户的成本Gcomplete

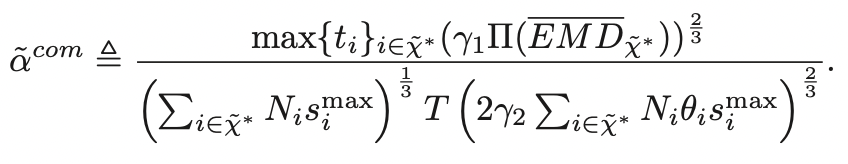
引理6说明服务器成本Gcomplete 由选定用户的私人信息决定,并将四维信息转换为一个一维的衡量标准。
定理4:给出了信息完整场景下的最优契约设计Ccompleteopt-non

解析:在信息完整的场景下,因为服务器清楚知道每个用户的类型,可以确保每一个用户选择指定的契约条款,因此无需给到用户太多的激励,可以调整报酬函数使得每一个用户的收益为0;另一个现象是每个用户的数据量会随EMD值和通信时间的上升而上升,随边际数据使用成本上升而下降。这是因为随着数据的non-IID程度上升,服务器自然需要用户提供更多的数据来保持模型准确度;随着通信时间上升,模型的总训练次数会下降,准确度自然也下降,同样需要用户提供更多数据;而随着一个用户的边际数据使用成本上升,服务器需要支付给用户的费用也上升,自然会较少地向这个用户索取数据。
IID VS Non-IID:
在信息完整的场景下,针对non-IID数据设计的契约会选择多个不同的用户类型,以防止太高的non-IID程度加大服务器的成本。
信息略微缺失的场景
问题6:最小化服务器的成本
约束:IR和IC
引理7:定义了服务器选择该子集中用户的成本GW-incomplete
定理5:信息略微缺失场景下的最优契约设计CW-incompleteopt-non。这个契约设计和信息完整场景下的契约设计形式上唯一的不同是报酬函数,报酬函数沿用了引理4中的定义。
IID VS Non-IID:
因为GW-incomplete 和Gcomplete 不同,两种场景下服务器会选择的最优契约不同,这一点和针对IID数据的契约设计是不同的。
结论
- 本文是联邦学习领域第一篇同时考虑不同的信息不对等程度以及IID/non-IID训练数据产生的多种情况的研究多维用户信息契约设计的文章;
- 本文提出了一种方法将多维的用户信息归纳为一个一维的衡量标准;
- 同时本文揭示了不同信息不对等程度造成的影响;
- 实验证明文章提出的契约设计在三种信息场景下,针对IID数据和non-IID数据都有优秀的性能表现;
- 未来我们会研究针对多个服务器竞争使用同一批用户的数据训练相似机器学习模型这一情形的契约设计。
论文思路分析
- 定义系统模型,包括联邦学习过程、用户类型、契约、用户收益以及服务器成本。
- 针对IID数据在信息完整场景下的契约设计。此时服务器知道每一个用户属于的用户类型,因此基本任务是确保每一个用户会选择契约中对应条款;报酬函数的设计只需要考虑保证每一个用户选对条款情况下获得非负收益的同时最小化服务器成本,由此推出了引理1中的报酬函数;引理2给出了服务器只选择某一类型用户的成本;定理1首先解释了为什么选择单一类型的用户是最佳方案,此时服务器的成本就等同于引理2中服务器选择单一类型的成本,找到能使这一成本值最小的用户类型,令其对应的契约条款有效,其余条款无效;此时最大通信时间就等于这一用户类型的通信时间,最优数据量则通过对成本函数求偏导求得,再结合引理2提出的报酬函数,就可以得到在信息完整场景下针对IID数据的最优契约。
- 针对IID数据在信息略微缺失场景下的契约设计。此时服务器不知道每个用户属于什么类型,只知道每个类型用户的数目;报酬函数的设计就需要进一步考虑确保每一个用户选择契约中对应条款获得的收益是最大的;其次,由于服务器不再知道每个用户的边际数据成本,报酬函数的设计还需要确保服务器会从边际数据使用成本小的用户索取更大的数据量,并相应地支付更高的报酬,引理3基于以上要求给出了报酬函数的一系列约束条件;引理4给出了符合引理3条件的报酬函数,并证明了它的最优性和唯一性;定理2则证明了信息略微缺失场景下的最优契约设计与信息完整场景下的契约设计等价,原因是在定理2的证明过程中发现,能够最小化服务器成本用户类型的报酬函数与信息完整场景下的报酬函数相同。
- 针对IID数据在信息严重缺失场景下的契约设计。此时服务器不知道每个用户类型的数目,只知道用户总数以及每个用户类型使用数据服从的概率分布;如果继续沿用前两种场景下,只选择一个最优用户类型的策略,可能出现选中的用户类型用户数目很少甚至为0,导致训练数据缺乏的情况;解决方法是转变为选择一个最优用户类型子集的策略,考虑一种Two-Part Uniform契约,即将所有用户类型对应的契约条款分为两部分,一部分有效,一部分无效;引理5给出了针对任意选择的一个用户类型子集的最优契约设计;定理3给出了信息完整场景下服务器成本与信息严重缺失场景下TPU契约对应服务器成本差值的上界和下界,并对这个上界和下界进行分析,提出了寻找最优用户类型子集方法的参考。
- 针对non-IID数据引入EMD 值衡量数据的non-IID程度,重新定义用户类型和服务器成本。
- 针对non-IID数据的契约设计。由于引入了non-IID数据,重新服务器成本时加入了一个与non-IID程度相关的系数;在这种情况下,服务器不再可以只选择一个用户类型,必须选择多个用户类型,以防止训练数据太高的non-IID程度加大服务器的成本;因为选择了多个用户类型,服务器的任务不再是确定一个用户类型的最优数据量,而是确定多个用户类型的最优数据使用比例;引理6和引理7分别提出了在信息完整场景和信息略微缺乏场景下服务器选择某一用户类型子集的成本函数,通过求偏导的方式得到最优数据使用比例;定理4和定理5则分别提出了在两种信息场景下的最优契约设计。由于无法确定最优解或评估契约性能,作者没有继续讨论在信息严重缺失场景下针对non-IID数据的最优契约设计。















 1189
1189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









