









@[TOC](Q-learning (off-policy): 用来训练最优动作价值函数)
本笔记整理自 (作者: Shusen Wang):
https://www.bilibili.com/video/BV1rv41167yx?from=search&seid=18272266068137655483&spm_id_from=333.337.0.0

- 价值网络 Q π ( s , a ; θ ) Q_{\pi}(s, a; \theta) Qπ(s,a;θ)是动作价值函数 Q π ( s , a ) Q_{\pi}(s,a) Qπ(s,a)的近似,我们用Saras更新价值网络。




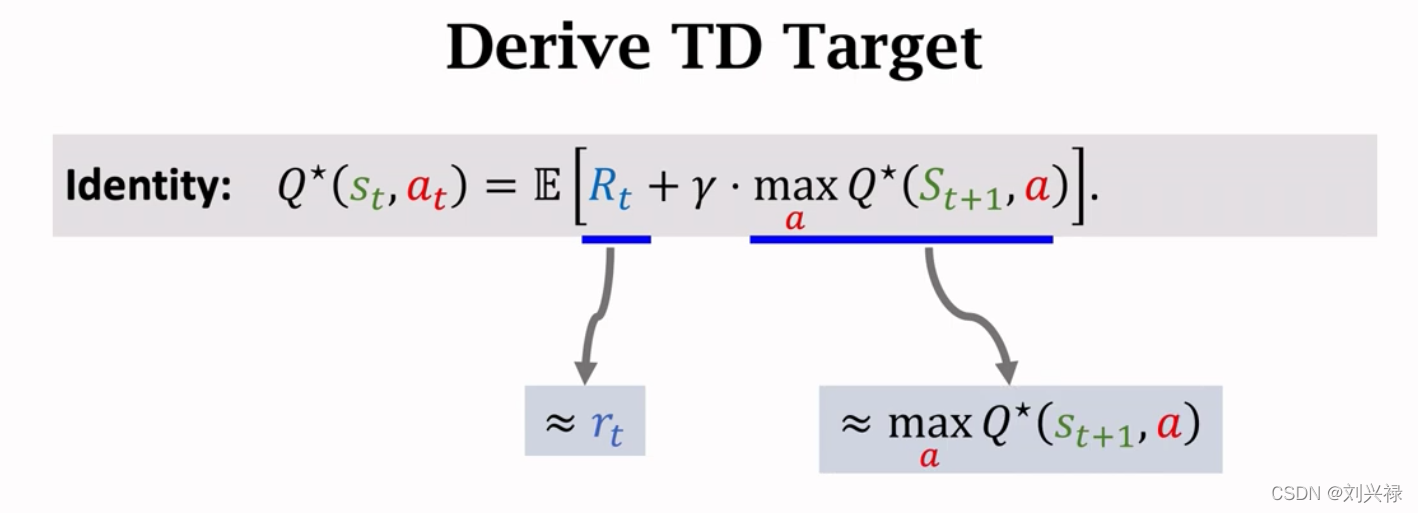
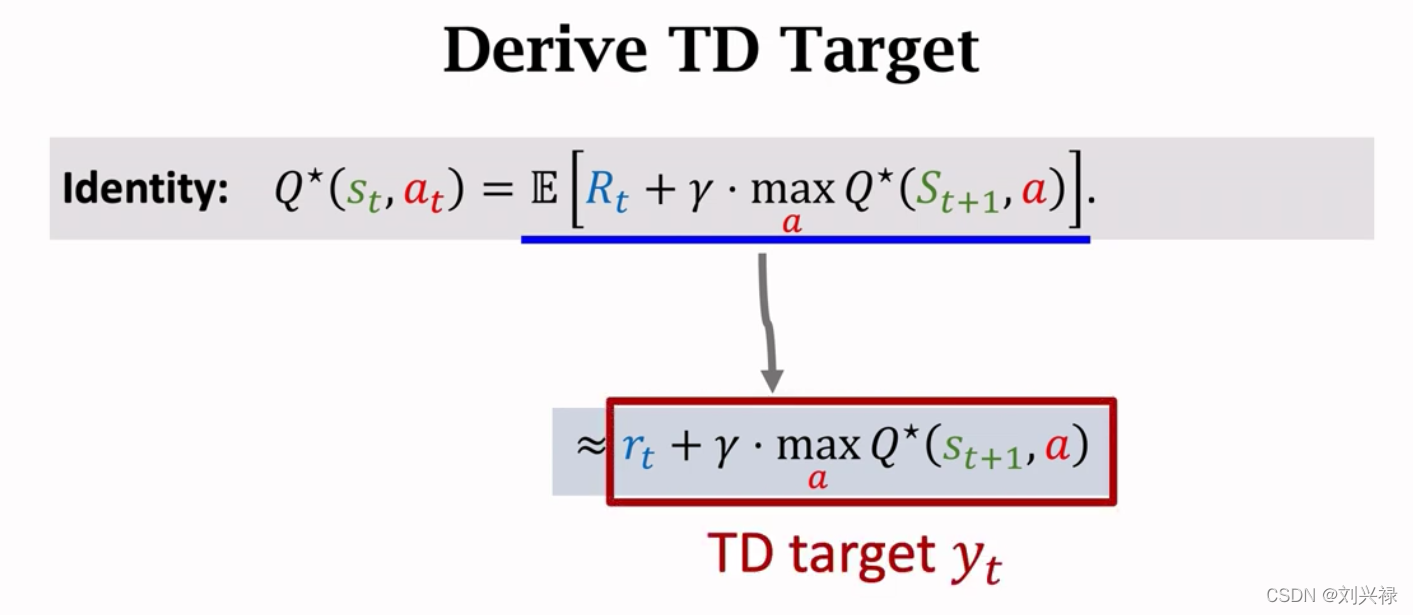
- TD target 部分基于真实观测,比左边纯粹猜测更加靠谱,因此我们鼓励猜测向TD target 靠近


Q-learning: DQN version



















 884
884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









