






softmax回归
文章目录
一、softmax用来干什么?
-
单一的线性模型只能处理二分类问题,对于多分类问题,引入softmax回归
-
线性回归模型适用于输出为连续值的情景。在另一类情景中,模型输出可以是一个像图像类别这样的离散值。对于这样的离散值预测问题,我们可以使用诸如softmax回归在内的分类模型。和线性回归不同,softmax回归的输出单元从一个变成了多个,且引入了softmax运算使输出更适合离散值的预测和训练
二、代码
1.引入库
import torch
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import torchvision
from d2l import torch as d2l
train_data=torchvision.datasets.FashionMNIST(root='~/data',train=True,download=True,transform=transforms.ToTensor())
test_data=torchvision.datasets.FashionMNIST(root='~/data',train=False,download=True,transform=transforms.ToTensor())
说明1、train_data,test_data,分别是FashionMNIST数据集的训练集和测试集,其中对于下载下来的图像集,需要把它转换为tensor类型,否则返回的是PIL图像,并且此时的尺寸由(H W C)变为(C H W)
2.验证第一张图像的尺寸和类别
print(train_data[0][0].shape,train_data[0][1])
#torch.Size([1, 28, 28]) 9
3.展示前十张图片
def show_images(images):
plt.Figure()
_,figs = plt.subplots(1,10,figsize=(12,12))# 这里的_表示我们忽略(不使用)的变量
#plt.subplots(a,b,size)表示生成a行b列个子图,并且大小为size
for f, img in zip(figs,images):#zip,将生成一个[(figs,images)]的迭代器
f.imshow(img.view(28,28).numpy())#imshow()实现热图绘制
f.axes.get_xaxis().set_visible(False)#不显示该子图的x坐标和y坐标
f.axes.get_yaxis().set_visible(False)
plt.show()
x=[]
for i in range(20):
x.append(train_data[i][0])
show_images(x)
#标签名字懒得百度了

4.设置批量大小为256
batch_size=256
#将训练集和测试集每次读取256张图片,也可以开多个进程来读取数据
train_iter=torch.utils.data.DataLoader(train_data, batch_size, shuffle=True)
test_iter=torch.utils.data.DataLoader(test_data,batch_size,shuffle=False)
for x,y in train_iter:
print(x.shape,y.shape)
break
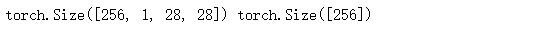
5.参数初始化
num_inputs=784
num_outputs=10
w=torch.normal(0,0.01,size=(num_inputs,num_outputs),requires_grad=True)#784*10
b=torch.ones(num_outputs,requires_grad=True)#10*1
lr=0.1
6.定义线性模型,softmax模型,损失函数,准确度,梯度下降函数
def linear(x,w,b):
return (torch.mm(x.view(-1,num_inputs),w) + b)
#在第四步可以看到x.shape=([256,1,28,28])-->x.shape([256,784])
#这里的-1是根据最后一个维度的num_inputs值自动算出的
#相乘之后矩阵为256*10,对应的是该批量大小中每张图片对应的十个输出 return 256*10
def softmax(y):
y_exp=y.exp()
partition=y_exp.sum(dim=1,keepdim=True)#按行求和,并保持原来维度不变,否则维度不满足广播机制,y_exp/p会报错
return y_exp / partition #返回的size 还是256*10
def cross_entropy(y_hat,y):
return -torch.log(y_hat[range(len(y_hat)), y])/len(y) #len(y_hat)和len(y)的值都是256
#这里运用了掩模mask ,根据Pi*log(Qi)其中p是i对应的真实值(只有0,1),q是i对应的预测值
#运用mask所以选择正确值所对应的预测值,再除以均值(图像个数len(y) or len(y_hat))
def evaluate_accuracy(data_iter,params):
acc_sum,n=0.0,0
#思想很简单 所有正确的值的个数/总个数
for x,y in data_iter:
acc_sum += (softmax(linear(x,w,b)).argmax(dim=1)==y).float().sum().item()
n += len(y)
return acc_sum / n
def sgd(params,lr):
with torch.no_grad():
for param in params:
param -= lr * param.grad
param.grad.zero_()
#一定得用 -= 如果用 param=param- 返回的地址已经变了,也就是param 不再是叶子结点 会出错
7.训练模型
def Train(train_iter, test_iter,w,b,lr):
for epoch in range(4):
train_loss,train_acc,=0.0,0.0
for x,y in train_iter:
y_hat=softmax(linear(x,w,b))
loss=cross_entropy(y_hat,y)
loss.sum().backward()
sgd([w,b],lr)
train_loss = loss.sum().item()
train_acc = evaluate_accuracy(train_iter,[w,b])
test_acc = evaluate_accuracy(test_iter, [w,b])
print('epoch %d,loss %.4f, train_acc %.4f,test_acc %.4f' %(epoch+1,train_loss, train_acc, test_acc))
Train(train_iter,test_iter,w,b,lr)
因为学习率设置为了0.1,所以第一遍的训练结果就达到了78.7%,测试结果达到了77.7%
大家可以多尝试不同 lr,测试一下
















 65
65











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











