






Semi Supervised Heterogeneous Domain Adaptation via Disentanglement and Pseudo-Labelling论文阅读
目录
-
一、研究背景
-
(一)域适应
-
获取大量标注样本始终是许多领域的主要挑战,尤其是那些标注过程耗时且成本高昂的领域。因此,充分利用已有的、涵盖相似下游任务的数据,对于提升标注数据稀缺的目标域分类性能至关重要。然而,由于源域与目标域之间潜在的数据分布差异或偏移,这一过程并非易事。为应对源域与目标域之间的数据分布偏移问题,域适应(DA)技术应运而生。
1.主要目标
域适应(Domain Adaptation,DA)的核心目标是跨越不同数据分布,将在源域(通常标注丰富)训练的模型有效迁移到目标域(标注稀缺或无标注),确保模型在目标域的分类性能。
2.主要类型
无监督域适应(UDA)
目标域完全无标签,依赖分布对齐(如特征变换、对抗学习)减少域间差异。
半监督域适应(SSDA)
结合源域全量标签、目标域少量标签及目标域无标签数据,通过监督与非监督信号融合提升目标域性能。
异构域适应(Heterogeneous DA)
源域与目标域数据模态不同,需跨越模态差异进行知识迁移。
(二)现有方法的局限性
无监督域适应
无法利用目标域的任何标签信息,导致模型对目标域的适应性受限。
半监督域适应
传统 SSDA 方法假设源域与目标域数据模态相同(同构域),无法处理模态异质性(如光学→雷达遥感影像)。
异构域适应
现有 HDA 方法依赖预训练模型(如 RGB 预训练网络),限制了在非标准模态(如医学影像、多光谱遥感)中的适用性。
-
二、本文创新点
-
(一)端到端特征解耦架
设计独立编码器分支分别处理源域与目标域数据,通过正交损失(L⊥)强制分离域不变特征(与任务相关)和域特定特征(模态相关),避免模态干扰。
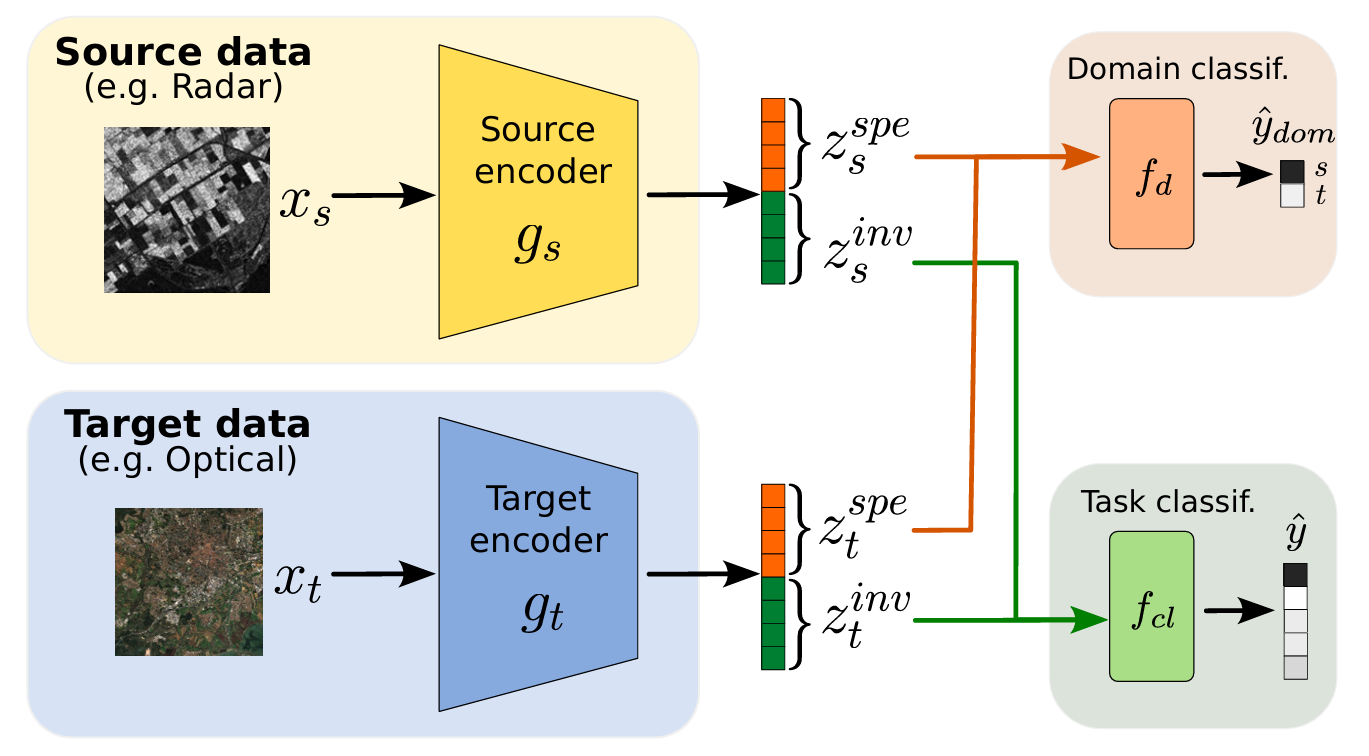
网络架构
源数据(中文数学教材 xs)
源编码器 gs:
如同 “中文数学老师”,将中文教材内容编码成知识向量。老师分析文字、公式,把教材信息转化为你大脑能处理的 “知识信号”。
向量拆分:
橙色(域特定特征):
中文特有的表达形式,比如 “三角形” 的汉字写法、中文语法结构。这部分输入 “域分类器 ”,就像告诉大脑:“这段内容来自中文教材”。
绿色(域不变特征):
数学知识本身,比如 “三角形内角和 180 度”。这部分输入 “任务分类器 ”,用于完成核心任务 —— 理解数学知识、做对题目。
目标数据(英文数学教材 xt)
目标编码器 gt:
如同 “英文数学老师”,将英文教材内容转化为知识向量。老师解读英文术语、公式表达,转成你能理解的信号。
向量拆分:
橙色(域特定特征):
英文特有的表达,比如 “triangle” 的拼写、英文句式结构。同样输入域分类器,让大脑识别:“这段内容来自英文教材”。
绿色 (域不变特征):
共通的数学知识,比如 “三角形内角和 180 度” 的本质。输入任务分类器,和中文教材的知识一起,帮你掌握数学核心内容,不管用哪种语言学习
(二)基于伪标签的一致性正则化
结合 FixMatch 框架,利用无标注目标数据生成高置信度伪标签,通过一致性损失增强模型泛化能力。
核心步骤:
-
伪标签生成:对无标签样本 ,通过分类器预测其域不变特征 ,得到伪标签 。
-
数据增强:生成增强样本,提取其域不变特征
-
置信度筛选:仅保测概率最高值超过阈值 τ 的伪标签 。
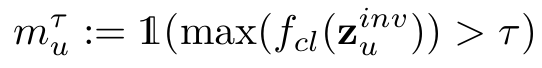
-
一致性损失:计算增强样本预测结果与伪标签的交叉熵损失,结合置信度因子,仅对高置信度样本进行约束。
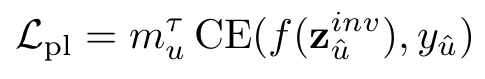
(三)多损失协同优化
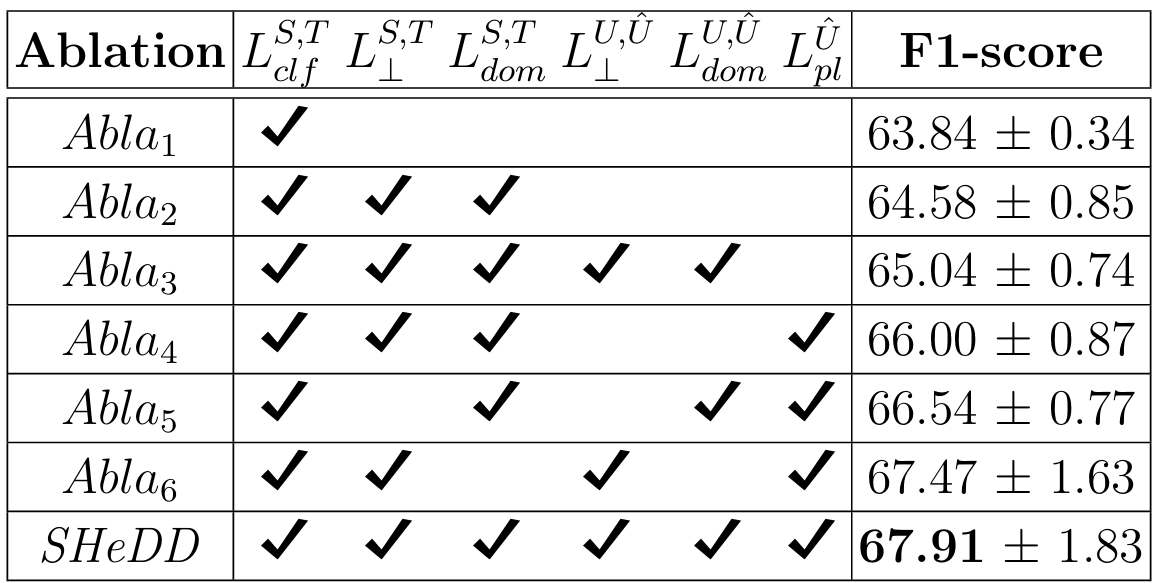
融合四类损失:
分类损失(Lcl):监督源域和目标域有标签样本的分类准确性

域分类损失(Ldom):强制模型将域信息编码到域特定特征中
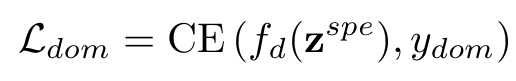
正交损失(L⊥):强制域不变特征与域特定特征正交,确保两者解耦

伪标签损失(Lpl):利用无标签数据的高置信度伪标签,通过数据增强约束模型预测一致性
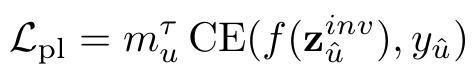
消融验证:去除任一损失均导致性能下降
-
三、实验对比
-
(一)特征分布可视化对比
SHeDD 生成的域不变特征在降维后,类别间分离更清晰,聚类效果显著优于 Target Only、FixMatch 和 SS-HIDA。
-
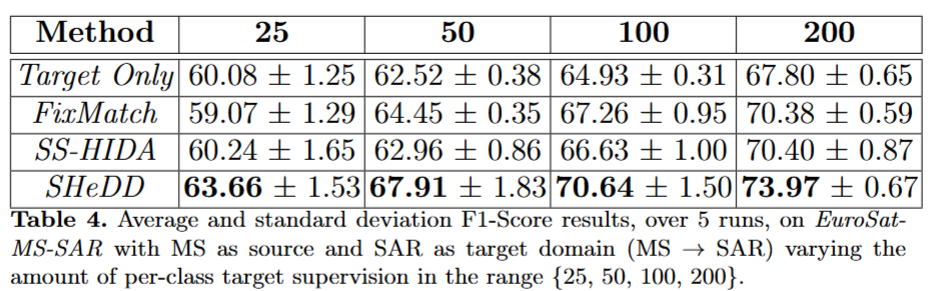
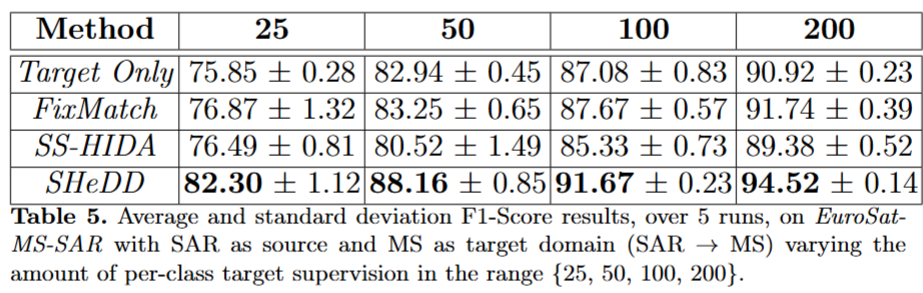
(二)MS-SAR 数据集
无论是从MS-SAR,还是SAR-MS,SHeDD性能都领先于其他方法
四、总结
SHeDD 通过特征解耦与一致性正则化,有效解决了异质域适应问题,在遥感数据基准上表现优异,为跨模态迁移学习提供了新思路

















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









