







从头开始实现Nearest Centroid最近质心分类器涉及一些直接了当的步骤。这个分类器首先通过计算训练集中每个类的质心,然后根据最近的质心对测试集中的每个样本进行分类。以下是一个基本的Python实现:
步骤1:计算每个类的质心 质心是一个类中所有点在所有维度上的平均位置。对于一个类C,有点p1, p2, ..., pn,每个点都有d个维度,每个维度di上的质心C_centroid计算如下:
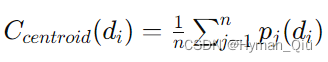
步骤2:基于最近质心进行分类 要对一个新点进行分类,计算这个点到每个类质心的距离,并将点分配给最近的质心类。
以下是如何用Python实现的:
import numpy as np
class NearestCentroidClassifier:
def __init__(self):
self.centroids = []
self.labels = []
def fit(self, X, y):
"""
Fit the model to the data.
X is a 2D numpy array of features.
y is a 1D numpy array of labels.
"""
self.labels = np.unique(y)
self.centroids = np.array([X[y == label].mean(axis=0) for label in self.labels])
def predict(self, X):
"""
Predict the class labels for the given data.
X is a 2D numpy array of features.
"""
distances = np.sqrt(((X[:, np.newaxis, :] - self.centroids) ** 2).sum(axis=2))
nearest_centroids = distances.argmin(axis=1)
return np.array([self.labels[index] for index in nearest_centroids])
# Example usage
if __name__ == "__main__":
# Example data: 4 samples with 2 features each
X_train = np.array([
[1, 2],
[2, 1],
[3, 3],
[6, 5]
])
y_train = np.array([0, 0, 1, 1]) # Class labels
# New samples to classify
X_test = np.array([
[2, 2],
[5, 4]
])
# Create and train the classifier
classifier = NearestCentroidClassifier()
classifier.fit(X_train, y_train)
# Predict and print the class of the new samples
predictions = classifier.predict(X_test)
print("Predicted classes:", predictions)
这个脚本定义了一个带有fit和predict方法的NearestCentroidClassifier类。fit方法计算训练集中每个类的质心,predict方法则根据最近的质心对测试集中的每个样本进行分类。
这个实现相当基础,可以通过多种方式进行扩展,比如添加不同的距离度量或处理分类数据。然而,它捕捉到了最近质心分类算法的本质。
X[:, np.newaxis, :]
表达式 `X[:, np.newaxis, :]` 在NumPy中用于修改数组 `X` 的维度,特别是在特定位置添加一个新轴。理解这一点需要对NumPy的切片和维度操作有一定的熟悉度。让我们分解一下:
NumPy数组和轴
NumPy数组有轴(维度)。对于一个2D数组,第一个轴(轴0)是行,第二个轴(轴1)是列。
np.newaxis对象
`np.newaxis` 在数组索引中用来创建一个长度为一的轴。这意味着它是一种通过在指定位置插入新轴来增加现有数组的维度的方法。
理解 `X[:, np.newaxis, :]`
假设 `X` 是一个2D数组。表达式 `X[:, np.newaxis, :]` 正在做以下操作:
- `X[:, ...]`:这部分意味着“沿着第一个轴(行)和第二个轴(列)取所有元素”。它本质上是选择整个数组。
- `np.newaxis`:这被插入到索引元组的第二个位置。它告诉NumPy在这个位置添加一个新的轴(长度为一)。所以,如果 `X` 是2D的(例如,形状为 `(n, m)`,其中 `n` 是行数,`m` 是列数),那么在此操作之后,形状变为 `(n, 1, m)`。
假如你有一个2D的数组,
import numpy as np
X = np.array([[1, 2, 3],
[4, 5, 6]])
print(X.shape) # Output: (2, 3)
X_new = X[:, np.newaxis, :]
print(X_new.shape) # Output: (2, 1, 3)
现在,`X_new` 有三个维度。中间的维度(轴1)长度为1,有效地为数组添加了一个“厚度”或新的层次,使其成为3D。
为什么使用 `X[:, np.newaxis, :]`?
在执行数组间距离计算等操作的上下文中,添加一个额外的维度对于正确工作的广播至关重要。广播允许NumPy对不同形状的数组进行逐元素操作。通过调整数组的维度,你可以确保像减法或加法这样的操作跨越所需的维度发生。
例如,如果你正在计算 `X` 中每个点与一些质心之间的距离,添加 `np.newaxis` 允许你以向量化和高效的方式从 `X` 中的每个点减去一个2D数组的质心,无需显式循环。
















 103
103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











