






 文章探讨了神经元的梯度下降优化中,零均值化输入对收敛速度的影响,分析了参数数量与隐藏层层数的关系,解释了为何不对偏置b正则化,以及为何随机初始化参数而非全零。还讨论了学习率对梯度消失问题的影响和解决策略,如LeakyReLU函数的应用。
文章探讨了神经元的梯度下降优化中,零均值化输入对收敛速度的影响,分析了参数数量与隐藏层层数的关系,解释了为何不对偏置b正则化,以及为何随机初始化参数而非全零。还讨论了学习率对梯度消失问题的影响和解决策略,如LeakyReLU函数的应用。
习题4-1 对于一个神经元σ(w.T*x + b),并使用梯度下降优化参数w时,如果输入x恒大于0,其收敛速度会比零均值化的输入更慢.
对神经元表达式求导后,变为σ(1-σ)x,由此当x恒大于0的时候,这些个神经元的参数的梯度就会和神经元同号,就可能不会让这个收敛的过程很顺利,也就是可能发生抖动,然后就减缓了收敛速度。但是零均值化的输入呢,会让神经元参数的梯度和x相关,这样就加快了收敛速度。零均值化,就是减去所用数据减去均值,即让整体数据的均值为0。
习题4-5如果限制一个神经网络的总神经元数量(不考虑输入层)为N+1,输入层大小为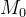 ,输出层大小为1,隐藏层的层数为L,每个隐藏层的神经元数量为
,输出层大小为1,隐藏层的层数为L,每个隐藏层的神经元数量为 ,试分析参数数量和隐藏层层数L的关系.
,试分析参数数量和隐藏层层数L的关系.
首先需要考虑,输入层于第一个隐藏层之间的参数,再次是,每个隐藏层之间的参数,最后是最后一层隐藏层和输出层的参数。有以上思路可以知道,我们可以将参数分为三个部分,n1,n2,n3,
分别代表以上的三类参数,这样的话,很容易得出结论 n=n1+n2+n3,具体计算过程不予呈现,只写出最后的表达式:
,如果考虑除w外的其他参数,则可以按照整体参数数量对其进行乘法计算。
习题4-7为什么在神经网络模型的结构化风险函数中不对偏置b进行正则化?
相对于受数据影响较大而w而言,b的存在只是为了让整体有一个偏移量,正如bias表示偏差一样,调整以下神经元输出的位置。正则化是干什么的呢,让我们复习一下:正则化是在求梯度后,增加或减少一定的值,从而让这个梯度的更新值被限制在某一个范围内,不要出现过拟合的现象,然而对于我们的偏差也就是bias,我们限制他对于我们的目的作用是很小的,因为他是一个常量,在求导的过程中感觉就没了吧,我数学没学得很好,如果这里有错的话,感谢指出。感觉就意义不大了吧。据说这个对b进行正则化容易导致欠拟合。
习题4-8为什么在用反向传播算法进行参数学习时要采用随机参数初始化的方式而不是直接令W =0,b= 0?
这不就是那个4.4优化的内容嘛,这个的答案在做了实验之后应该会有一个很清楚的名词叫,对称权重现象,这样会导致整个模型很难训练,训练的效果又慢又差,我的程序调了半天才调出来一点变化。而且试想一下,加入所有的参数都相同,那么这个不就相当于把每一个隐藏层都之放置了一个神经元嘛,这样的话设置隐藏层里的多层神经元又有什么意义。只有随机后,让每一个神经元都参与到这个模型的训练的过程,才会发挥出算法的优点。
习题4-9梯度消失问题是否可以通过增加学习率来缓解?
首先给出答案,不会。
梯度消失的问题是因为当函数过于接近某一个值或者超过某一个值之后导致的梯度为0参数无法有效更新的现象,例如说sigmoid在十分接近0或者1时的梯度为0,relu在小与0之后的梯度均为0的时候,就出现了梯度消失,这个名字也很应景啊,就是梯度没了。
然后我们再看这个学习率,学习率是更新梯度时用到的,他和梯度是相乘的关系,但是当一个值过于小时,我们知道无论另一个值多大,那得出的值都会很小,所以说,这个学习率不能缓解梯度消失问题,但是学习率可以加快训练。
至于如何解决这个问题,有一个叫leaky relu的激活函数,这个函数就是让x在小与0的情况下,仍然有梯度,不至于让梯度消失。当然在未来的学习中,我们应该会认识到更多的这种函数或者是方法,来防止梯度消失。















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









