







在机器学习的监督学习,无监督学习和强化学习中,我最喜欢强化学习,因为强化学习最接近动物的学习方式,而且业务需求特别强烈。
Reinforcement Learning(增强学习,以下简称RL )
RL背后的一个核心概念是价值估计,并据此进行相应动作。在继续深入之前,最好先了解一些术语。
在RL中,实施动作的个体被称为agent(代理),它使用策略进行动作决策。一个代理通常嵌于一个environment(环境)中,并在任意给定的时刻都处于某个特定的state(状态)。从那个状态,它可以进行一系列actions(动作)。某个给定状态的value(值)指的是处于该状态的最终回报价值。在某个状态执行一个动作可以让代理进入另一个新的状态,获得一个reward(回报),或者同时拥有两者。所有RL代理都在尽可能最大化累计回报。
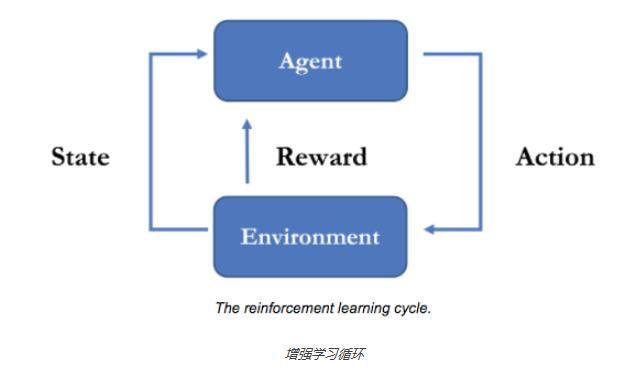
我用训练狗做一个例子,environment是公园的草坪,agent是我的狗,我的目标是训练狗能把我扔出去的小球给我叼回来,reward有两样东西,一个是狗喜欢吃的肉,肉有两种一种是大份,一种是小份的,另一个一巴掌。state是我把小球扔出去到狗叼东西回来这段时间,action是狗在这段时间的行为。那么开始训练,我手上有分别为红/橙/黄/绿/青颜色小球,我想狗给我叼回红色的球,我把5个球一起扔出去,那么狗在这片草坪上开始自由行动,如果一定时间内,它什么都没叼回来或者叼了除了小球的其他东西比如,树叶,鞋子,内衣等。我就给它一巴掌,如果它叼回来红球以外的其他颜色的球,那么就给小份的香肉,如果叼回来红色小球,就给大份的肉。然后我就不断地扔球训练我的狗,狗(agent)就会知道红球能带来最大的reward(这是个例子,我不晓得现实中的狗会不会这样)。
多臂老虎机(multi-armed bandit)是RL问题中最简单的一个版本。这个名字由以下这个问题衍生而来:如何使多台老虎机的回报最优化,假定老虎机都具有赚取客户钱的倾向。在本设置中,环境内仅有一个状态,代理能采取n个动作中的一个。每个动作都会立即为代理提供一个回报。代理的目标是找出能提供最多回报的动作。

代理的目标就是学习得知哪个摇臂最有可能获奖。要找出回报最高的摇臂最自然的方法就是逐一尝试。在代理获得足够的关于这个世界的信息并采取最优化动作之前,大部分RL的工作就是简单的不断试错。上面这个例子用RL的术语来描述就是,“尝试”对应的是采取一系列动作(多次打开按下摇臂),学习对应的是更新每个动作的估计值。一旦我们基本确定值估计,就可以让代理总是选择那个具有最高估计值得摇臂。
这些值估计可以通过一个迭代过程获得。这个过程从最初的一系列估计V(a)开始,并根据每次动作的结果对其进行调整。表达式如下:
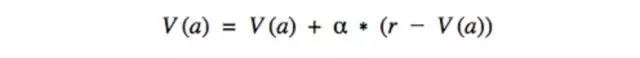
其中,α对应我们的学习率,V(a)是给定动作的价值估计,r是采取动作后马上可以获得的回报。
上面的等式很直观,它表明我们将当前的价值估计向获得回报的方向做了一些微调。这样就能确保变化的估计值能更好的反应环境中的真实动态。如此一来,还能确保估计不会变得过大,如果我们仅计算正向结果就可能会发生这种情况。要完成相应代码,我们可以使用一组值估计向量,并通过代理动作对应的索引来引用它们。
上述的情况缺少了任何真实环境中都有的一个重要方面:它仅有一个状态。在现实以及游戏世界中,一个特定环境可能会处于数十(房子中的房间)到数十亿(一个屏幕上的像素配置)种可能状态中的一种。每个状态都有它们自己独特的动态特性,即动作如何提供新的回报或者允许状态间的迁移。
因此,我们需要对动作,值估计,以及状态设定条件。用符号表示,现在将用Q(s,a)取代V(a),s是state,a是action。它的抽象意思是,现在期望获得的回报,是我们所采取的动作以及采取该动作时所处状态的一个函数。

强化学习的矛盾:探索(Exploring)和利用(Exploiting)
以摇臂老虎机为例:探索法为将所有尝试的机会平均分配给每一个摇臂(轮流按下摇臂),最后以每个摇臂各自的平均吐币概率为其奖励期望的近似估计,获知每个摇臂的期望奖赏。利用法为按下目前最优的摇臂。探索法很好的估计了每个摇臂的奖赏,却失去了很多最优摇臂的机会,而利用法没有很好地估计摇臂的期望奖赏,很可能选不到最优臂。两种方法单独使用都没办法使得最终奖赏最大化,强化学习必须在两者之间达成折中,这就是强化学习的窘境。
当然也是很多方法来进行折中的。比如贪心法,softmax。这个以后再讲~
我微信公众号,爱扫不扫
















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









