







本书的这一部分的第一章描述了强化学习问题的特例,其中只有一种状态,叫做老虎机问题。第二章描述了我们在整个有限马尔可夫决策过程中所讨论的一般问题的表述及其主要思想,包括贝尔曼方程和值函数。接下来的三章描述了求解有限马尔可夫的三类基本方法。决策问题:动态规划、蒙特卡罗方法和时间差分学习。每一类方法都有其优点和缺点。动态规划方法在数学上有不错的发展,但需要一个完整和准确的环境模型。蒙特卡罗方法不需要模型,概念上简单,但不太适合逐步增量计算。最后,时间差分方法不需要模型,完全增量,但更复杂的分析。这些方法在效率和收敛速度方面也有不同之处。剩下的两章描述了如何将这三类方法结合起来获得它们各自的最佳特征。在一章中,我们描述了蒙特卡洛方法的优点,后面还有和时间差分法的优点结合起来。
区分强化学习和其他类型学习的最重要的特征是它使用训练信息来评估所采取的行动,而不是通过给予正确的指导行动(即是非监督学习)这就是创造积极探索的必要性,明确地寻找好的行为。他的反馈是监督学习的基础,包括模式分类、人工神经网络和系统辨识的大部分。在这一章中,我们研究了强化学习的评价方面在一个简化的设置,一个不涉及学习在不止一种情况下行动。
我们探索一下简单的K摇臂老虎机来评估反馈(feedback)的问题,我们用这个问题介绍了一些基本的学习方法,我们在后面的章节中应用到完整的强化学习问题。在这一章的最后,我们通过讨论当老虎机问题扩展后发生的情况,即在一个以上的情况下采取行动时会发生什么样的情况,从而更接近完整的强化学习问题。
2-1 K摇臂老虎机
考虑一种情况,你需要不断重复地从K个选项中选其中一个选项。你每次作出一个选项后,都会获得一个数字作为反馈,K个选项,就有K个数字反馈,这个数值可以理解为reward。我们的目标是在一段时间内使预期的总奖励(reward)最大化,比如作出10000次选择或者一段时间后,计算奖励的和。
这个就是原始的K摇臂老虎机问题。这个问题就好像先假设K摇臂的K为一,就是只有一个摇臂的情况,每一次行为(action)就是摇一次臂,然后获得reward。通过反复的行动选择,你可以把你的行动集中在最佳的杠杆上,使你的奖金最大化。另一个比喻是医生在一系列重病患者的实验治疗之间进行选择治疗,每一个动作都是一种治疗的选择,每一个奖赏都是病人的生存或幸福。今天,“多摇臂老虎机”一词有时被用来概括上述问题,但在本书中,我们用它来引用这个简单的例子。
在K摇臂中,你的每一个选择都有期望值,比如在K个摇臂中,你是第三次摇臂,你要摇第i个摇臂,摇臂的结果就是第三次摇臂行为(action)的值(value),我们假设摇臂的次数t的集合At = {1,2,3,...t},相对应每次摇臂获得的奖励集合Rt,任意一次摇臂选择a摇臂后,其对应的值为q(a) = E(Rt|At=a)
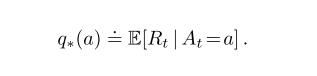
如果你知道每个行动的值,那你就能轻易解决k摇臂问题:你只要去摇能摇出最高奖励的摇臂即可。但实际问题是这样的,我们并不知道每个摇臂能摇出什么值,你可以去估计每个摇臂,我们假设你估计摇第a个臂的值为Qt(a),t为第t次摇臂,那么我们的任务就是把估计的摇臂值Q(a)尽可能地接近真实值q(a).
每一次摇臂,K个摇臂,你去估计每一个摇臂的值,总得有一个摇臂的值最大吧(不然怎么选呢),找最大值这个就是贪婪法(greedy),当你摇其中一次臂后,我们就可以说你是利用(exploiting)你当前对行为值的了解而作出的选择,你选择了你评估出的最大值。如果你摇臂不是根据你估计的最大值而作出选择,那就非贪婪,我们就可以说你是探索(exploring),探索能够提高你对非贪婪行动的价值估计。利用和探索有什么区别呢?利用就是在一次摇臂中选出你评估值最大的那个摇臂,也就说,如果只能摇臂一次,那么利用(exploiting)就有很大优势,但是探索(exploiting)就能在长时间的摇臂中获取更大的reward。举个例子,假设一个贪婪法的行动的价值是已经知道的,既是已知每个摇臂能摇出什么值,那么无论你做多少次摇臂,结果都是最优的,但实际上你不知道摇臂能摇出什么值,不然还卖什么彩票啊。这个不确定就是,你摇出一个值,但可能有个更大的摇臂值,但你不知道。因为探索法是算每个摇臂摇出值的概率,当摇臂次数很多的时候,概率就会准,在短期内,奖励在探索过程中较低,但长远来看更高,因为在你发现了更好的行动之后,你可以多次利用它们。单纯的探索和利用都是没用的,必须要在探索和利用之间找到折衷,探索和利用的矛盾就强化学习面对的问题。特别情况下是探索更好还是利用更好,取决于当前的评估值,选择次数。当然也有很多方法来平衡探索和利用我们在后面的章节会讲述,特别对于K摇臂问题。
在这本书中,我们不担心以复杂的方式平衡探索和利用。这一章我们介绍了几种简单的平衡方法来解决k摇臂问题,总的来说,会比只用“利用”会好。
2-2 行为-值方法(action-value)
还是先估值然后选择。选择一个摇臂后,获得的摇臂值是平均奖励,评估这一个方法就是是平均得到实际回报。

这个随机值如果为真那么预测值就为1如果预测值为假那么就为0,如果分母为0,那么我们就把Qt(a)定义为默认值,比如0。如果分母接近无限大,那么Qt(a)收敛为q(a)。我们称之为估计行动价值的样本平均法,因为每一个评估都是相关奖励样本的平均值。当然,这只是估计动作值的一种方法,而不一定是最好的方法。不过,现在让我们继续使用这个简单的估计方法,转而讨论如何使用估计值来选择操作。最简单的行为选择就是是选择具有评估值最高的操作之一,就是上面说的先猜猜每个摇臂的值,然后选评估值最高的摇臂。我们定义这种“贪婪”行为选择为:
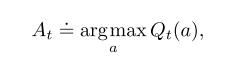
这里argmax指选择最大,贪婪法行为总是选择评估值最大(利用),这个方法不会去理会选择出来的是否是个垃圾,它不会想怎么做才会更好。有一个简单的方法来优化这个贪婪行为,就是在往贪婪法中加入随机选择,大部分时间都是在评估价值最高中选摇臂,但偶尔任性一下,随机选出一个摇臂,也就是说有一个小概率ε会出现随机选择摇臂。我们把这种大部分使用贪婪法偶尔任性随机选择的方法称为--ε贪婪法(ε-greedy),以后会经常看到这个ε-greedy的。这些方法的一个优点是,在步骤数量增加的限度内,每一个动作都会被无限次采样,从而确保所有的Qt(a)收敛到q(a)。行动将进行无限次,从而确保所有的Qt(a)收敛到q(a)。这当然意味着选择最优行动的概率收敛于大于
1−ε。
课后练习2.1 在ε-greedy方法选择中,要作出两次选择,现在ε=0.5,现在问,两个选择中出现贪婪法的概率?
课后练习2.2 在摇臂例子中,假设有4个摇臂,现在使用ε-greedy方法选择摇臂和简单行为-价值选择法。现在初始化评估Q1(a)=0,假设行动和奖励的初始顺序是A1=1,R1=1;A2=1,R2=1;A3=2,R3=2;A4=2,R4=2;A5=3,R5=0;在这些步骤中可能会出现ε使得摇臂随机选择,这一步是什么时候发生的?这一步可能发生在哪一步?
2.3 10个摇臂的实验
为了粗略地评估贪婪和ε贪婪方法的相对有效性,我们在一组测试问题上对它们进行了数值比较。这是一组2000个随机产生的10摇臂数据。
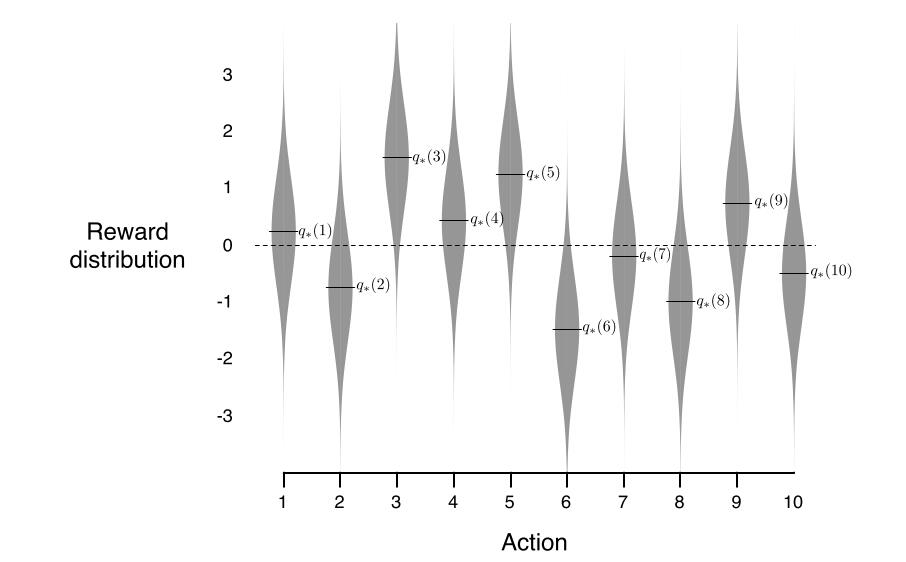
根据均值和单位方差的正态分布选取了10个摇臂真实值q(a),然后实际的报酬是根据平均q(a)选择单位方差的正态分布,正如这些灰色分布所显示的。
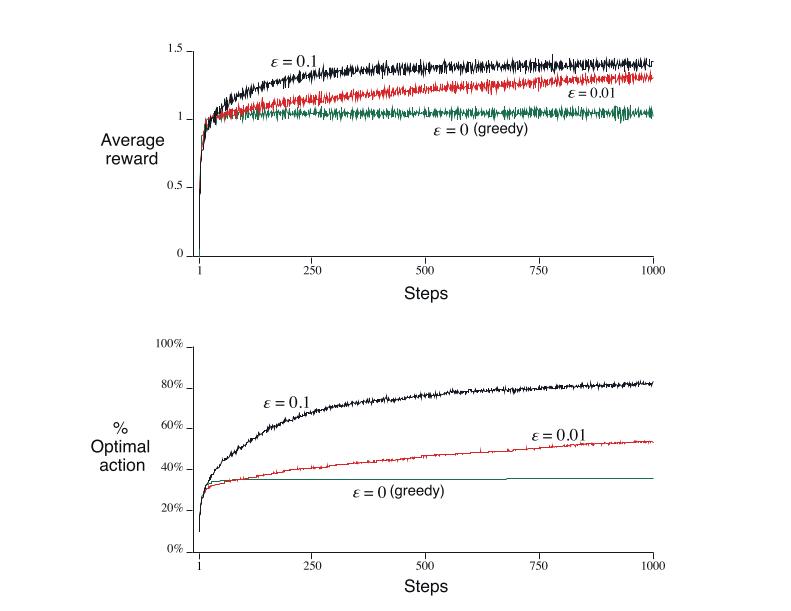
下图中,对于ε-greedy法,有两个ε值(ε=0.01和ε=0.1),贪婪法一开始提升得比其他方法快,但后面收益并不好,贪婪法最高reward大约只有1,而图中最高reward有1.55左右。贪婪方法在长期运行中表现得更糟,因为它经常被卡住,下面那个图显示贪婪方法在其中一个任务中找到最佳的行动,其他两个任务并不理想。这个ε-greedy法表现得比较好,它在“利用”中依然保持“探索”,ε=0.1时,它探索得比较多,找到最优选择时也比较早,但它从未选择过超过91%的时间,ε=0.01时,线条提升得比较慢,但最终表现得比ε=0.1好,也有可能随着时间的推移减少ε,这样就能即快速提升,最终表现也不错。假设reward方差较大,比如10而不是1,与奖励它需要更多的探索,找到最佳的行动,和ε-贪婪的方法应该更优于相对于贪心法。
2.4 增量执行
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1368
1368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









