







linear regression & logistic regression
-linear regression的代价函数
J(θ)=1m∑mi=012(hθ(x)−y(i))2(1)
可以简化为:
cost(hθ(x),y)=12(hθ(x)−y)2(1')
-logistic regression的代价函数
J(θ)=−12m∑mi=0y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i))(2)
为何在此处不采用线性回归较直观的代价函数形式(1),而是采用了看似复杂的(2)?
在Andrew NG的描述中,由于
h(θ)(x)=11+e−θTx(3)
线性回归的cost function由于是“convert”(“凸“)函数,局部最小值就是全局最小值,如下图:
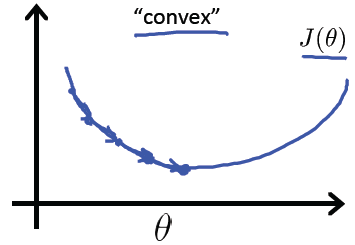
而cost Function如果采用之前线性回归 最小平方错误为代价函数的方式,cost function会变成非“凸“函数(non-convex),将有很多局部最小值干扰,如下图:
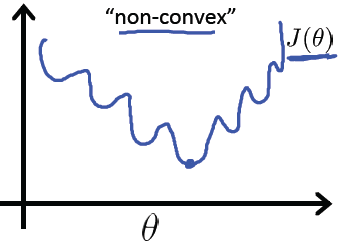
在其他博客中看到了另一种解释- “最大似然估计”,也很不错:
最大似然的思想使已有的数据发生的概率最大化,
p(y|x;θ)=hθ(x)y(1−hθ(x)(1−y)) y=1 or 0
最大似然概率的表述:
L(θ|x;y)=∏i=1mp(y(i)|x(i);θ)=∏i=1mhθ(x)y(i)(1−hθ(x))1−y(i)
将其转换为对数似然函数形式载乘以常数1/(2m)便是(2)的形式.
PS:统计学习中常用的损失函数有以下几种:
(1) 0-1损失函数(0-1 loss function):
L(Y,f(X))={1,0,Y≠f(X)Y=f(X)
(2) 平方损失函数(quadratic loss function)
L(Y,f(X))=(Y−f(X))2
(3) 绝对损失函数(absolute loss function)
L(Y,f(X))=|Y−f(X)|
(4) 对数损失函数(logarithmic loss function) 或对数似然损失函数(log-likelihood loss function)
L(Y,P(Y|X))=−logP(Y|X)
















 68
68

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









