






目录
一.决策树的定义
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。
结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类。
二.决策树的特征选择
特征选择在于选取对训练数据具有分类能力的特征。这样可以提高决策树学习的效率。如果用一个特征去分类,得到的结果与随机的分类没有很大差别,那么这次分类是无意义的。因此,我们要选取有意义的特征进行分类。
特征选择就是决定用哪个特征来划分特征空间。
直观上来讲,如果一个特征具有更好的分类能力,或者说,按照各以特征将训练数据集分割成子集,使得各个子集在当前条件下有最好的分类,那么就应该选择这一特征。
三.实验步骤
1.计算基尼指数
基尼指数(Gini不纯度)表示在样本集合中一个随机选中的样本被分错的概率。
Gini指数越小表示集合中被选中的样本被参错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。当集合中所有样本为一个类时,基尼指数为0.
CART决策树使用基尼指数来选择划分属性,采用如下计算公式,数据集D的纯度越高则基尼指数越小:
直观地来说Gini(D)反映了数据集D中随机抽取的两个样本,其类别标记不一致的概率。因此,Gini(D)越小,则数据集D的纯度越高。则被选中的该属性的加权基尼指数定义为:
2.找到最佳的切分特征和阈值
def best_split(self, X, y):
n_features = X.shape[1]
best_gini = float('inf')
best_feature_index = None
best_threshold = None
for feature_index in range(n_features):
thresholds = np.unique(X[:, feature_index])
for threshold in thresholds:
left_indices = np.where(X[:, feature_index] <= threshold)
right_indices = np.where(X[:, feature_index] > threshold)
left_gini = self.gini(y[left_indices])
right_gini = self.gini(y[right_indices])
gini = (len(left_indices[0]) * left_gini + len(right_indices[0]) * right_gini) / len(y)
if gini < best_gini:
best_gini = gini
best_feature_index = feature_index
best_threshold = threshold
return best_feature_index, best_threshold3.递归预测样本类别
def predict(self, X):
# 预测样本类别
return np.array([self._predict_tree(x, self.root) for x in X])
def _predict_tree(self, x, node):
# 辅助函数,递归预测样本类别
if node.value is not None:
return node.value
if x[node.feature_index] <= node.threshold:
return self._predict_tree(x, node.left)
else:
return self._predict_tree(x, node.right)4.输出结果
四.实验结果与代码
1.实验结果
2.代码实现
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
# 读取数据集
iris_data = pd.read_csv("D:\\jiqixuexi\\pythonProject\\.venv\\iris.csv")
x_data = iris_data[['Sepal.Length', 'Sepal.Width', 'Petal.Length', 'Petal.Width']].values
y_data = iris_data[['Species']].values
# 实例化LabelEncoder
label_encoder = LabelEncoder()
# 使用LabelEncoder将y_data中的数据进行编码
y_data_encoded = label_encoder.fit_transform(y_data.flatten())
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data_encoded, test_size=0.4, random_state=42)
class TreeNode:
def __init__(self, feature_index=None, threshold=None, left=None, right=None, value=None):
self.feature_index = feature_index # 特征索引
self.threshold = threshold # 切分点阈值
self.left = left # 左子树
self.right = right # 右子树
self.value = value # 叶节点的类别值
class DecisionTreeClassifier:
def __init__(self, max_depth=None):
# 初始化决策树分类器
self.max_depth = max_depth # 最大深度
self.root = None # 树的根节点
def fit(self, X, y):
# 训练决策树分类器
self.root = self.grow_tree(X, y) # 生成决策树
def predict(self, X):
# 预测样本类别
return np.array([self._predict_tree(x, self.root) for x in X])
def _predict_tree(self, x, node):
# 辅助函数,递归预测样本类别
if node.value is not None:
return node.value
if x[node.feature_index] <= node.threshold:
return self._predict_tree(x, node.left)
else:
return self._predict_tree(x, node.right)
def accuracy_score(self, X, y):
# 计算模型准确率
y_pred = self.predict(X)
return np.mean(y_pred == y)
def gini(self, y):
classes = np.unique(y)
n_instances = len(y)
gini = 0
for c in classes:
p = np.sum(y == c) / n_instances
gini += p * (1 - p)
return gini
def best_split(self, X, y):
n_features = X.shape[1]
best_gini = float('inf')
best_feature_index = None
best_threshold = None
for feature_index in range(n_features):
thresholds = np.unique(X[:, feature_index])
for threshold in thresholds:
left_indices = np.where(X[:, feature_index] <= threshold)
right_indices = np.where(X[:, feature_index] > threshold)
left_gini = self.gini(y[left_indices])
right_gini = self.gini(y[right_indices])
gini = (len(left_indices[0]) * left_gini + len(right_indices[0]) * right_gini) / len(y)
if gini < best_gini:
best_gini = gini
best_feature_index = feature_index
best_threshold = threshold
return best_feature_index, best_threshold
def grow_tree(self, X, y, depth=0):
n_samples, n_features = X.shape
n_classes = len(np.unique(y))
if n_classes == 1 or (self.max_depth and depth >= self.max_depth):
leaf_value = np.argmax(np.bincount(y))
return TreeNode(value=leaf_value)
best_feature_index, best_threshold = self.best_split(X, y)
left_indices = np.where(X[:, best_feature_index] <= best_threshold)
right_indices = np.where(X[:, best_feature_index] > best_threshold)
left_subtree = self.grow_tree(X[left_indices], y[left_indices], depth + 1)
right_subtree = self.grow_tree(X[right_indices], y[right_indices], depth + 1)
return TreeNode(feature_index=best_feature_index, threshold=best_threshold,
left=left_subtree, right=right_subtree)
# 实例化决策树分类器
clf = DecisionTreeClassifier(max_depth=3)
clf.fit(x_train, y_train)
# 输出最优的分类特征索引和切分点阈值
best_feature_index = clf.root.feature_index
best_threshold = clf.root.threshold
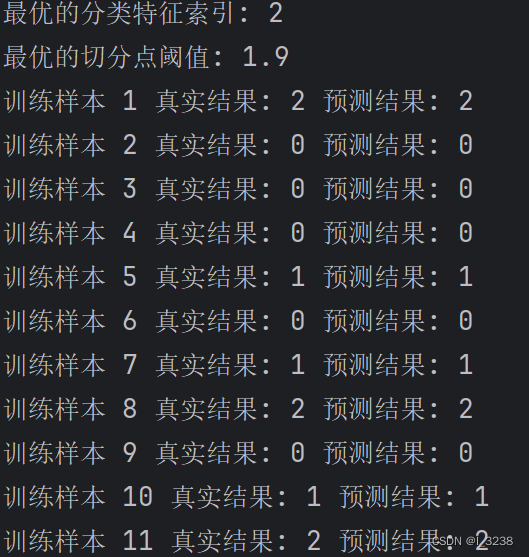
print("最优的分类特征索引:", best_feature_index)
print("最优的切分点阈值:", best_threshold)
# 在训练集上进行预测
y_train_pred = clf.predict(x_train)
for i in range(len(y_train)):
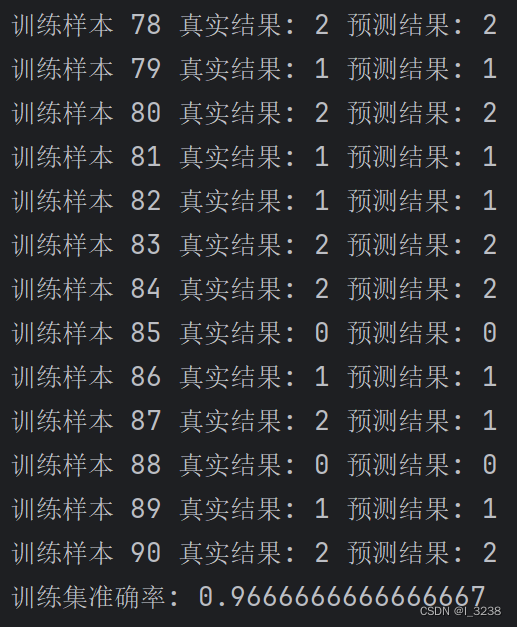
print("训练样本", i + 1, "真实结果:", y_train[i], "预测结果:", y_train_pred[i])
train_accuracy = clf.accuracy_score(x_train, y_train)
print("训练集准确率:", train_accuracy)















 5162
5162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









