







1.1机器学习分类和神经网络简介
1.1.1发展历程
1942年 提出机器人三定律:1不能伤害人类 2必须执行人类命令,不能违背第一条 3在第1、2条定律的前提下保护好自己;
2006年高歌猛进
计算智能 感知智能 认知智能
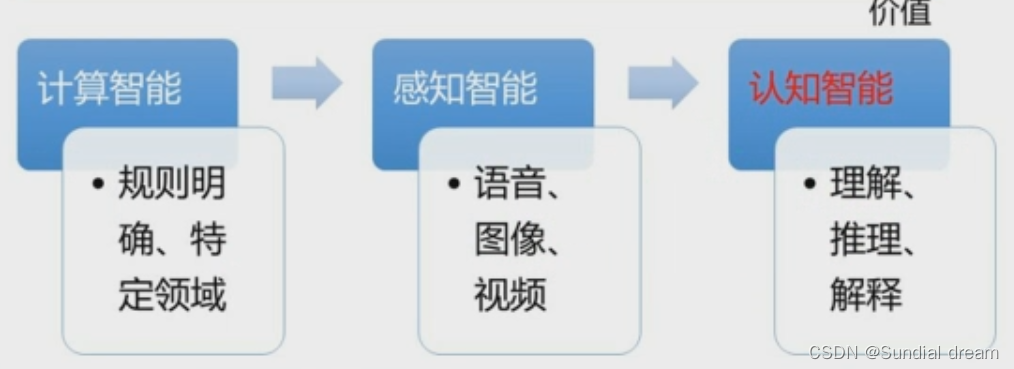
1.1.2人工智能体系
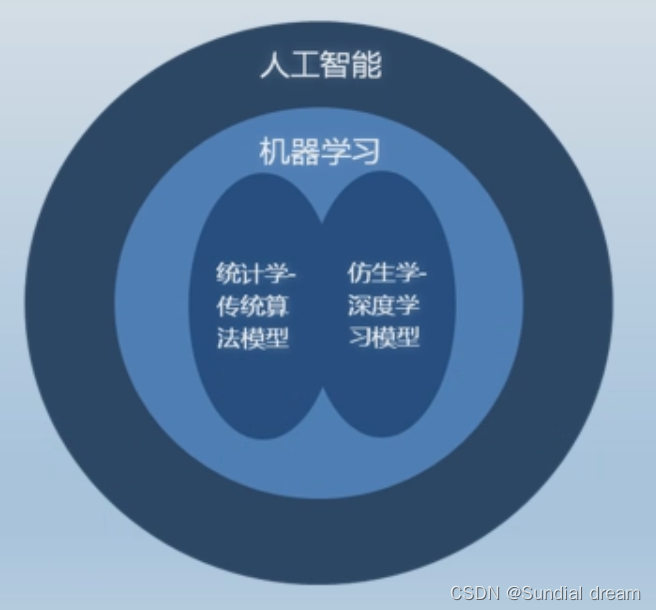
机器学习和人类学习的联系
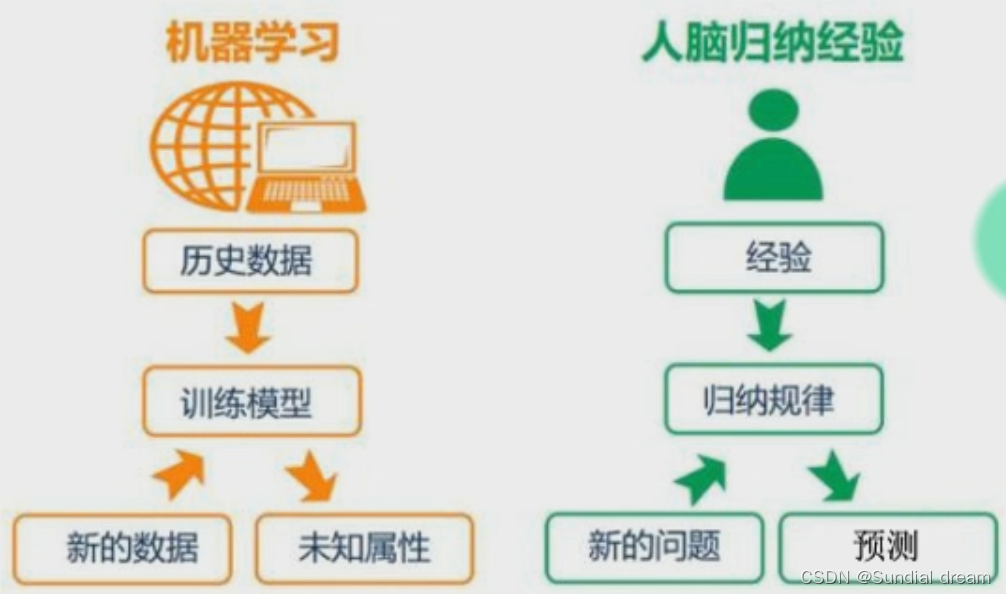
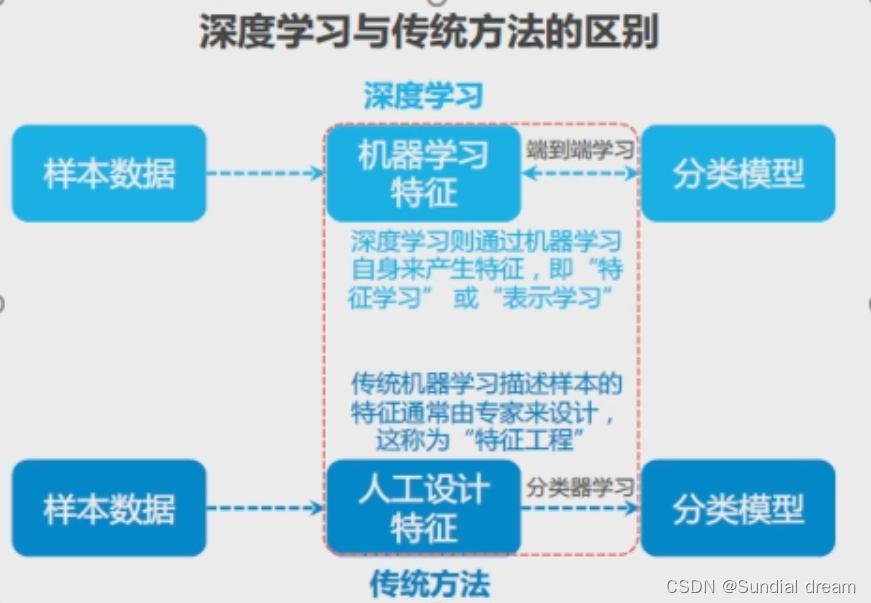
1.1.3机器学习的分类:
1.1.31按学习方式分类:
全监督学习、半监督学习、无监督学习
1.1.32按学习结果分类:
判别模型、生成模型
1.1.33按知识体系分类:
统计学模型、仿生学模型
1.1.34按应用领域分类
图像视觉领域、语音语义领域、自动化领域
1.2线性问题
1.2.1线性可分与线性不可分
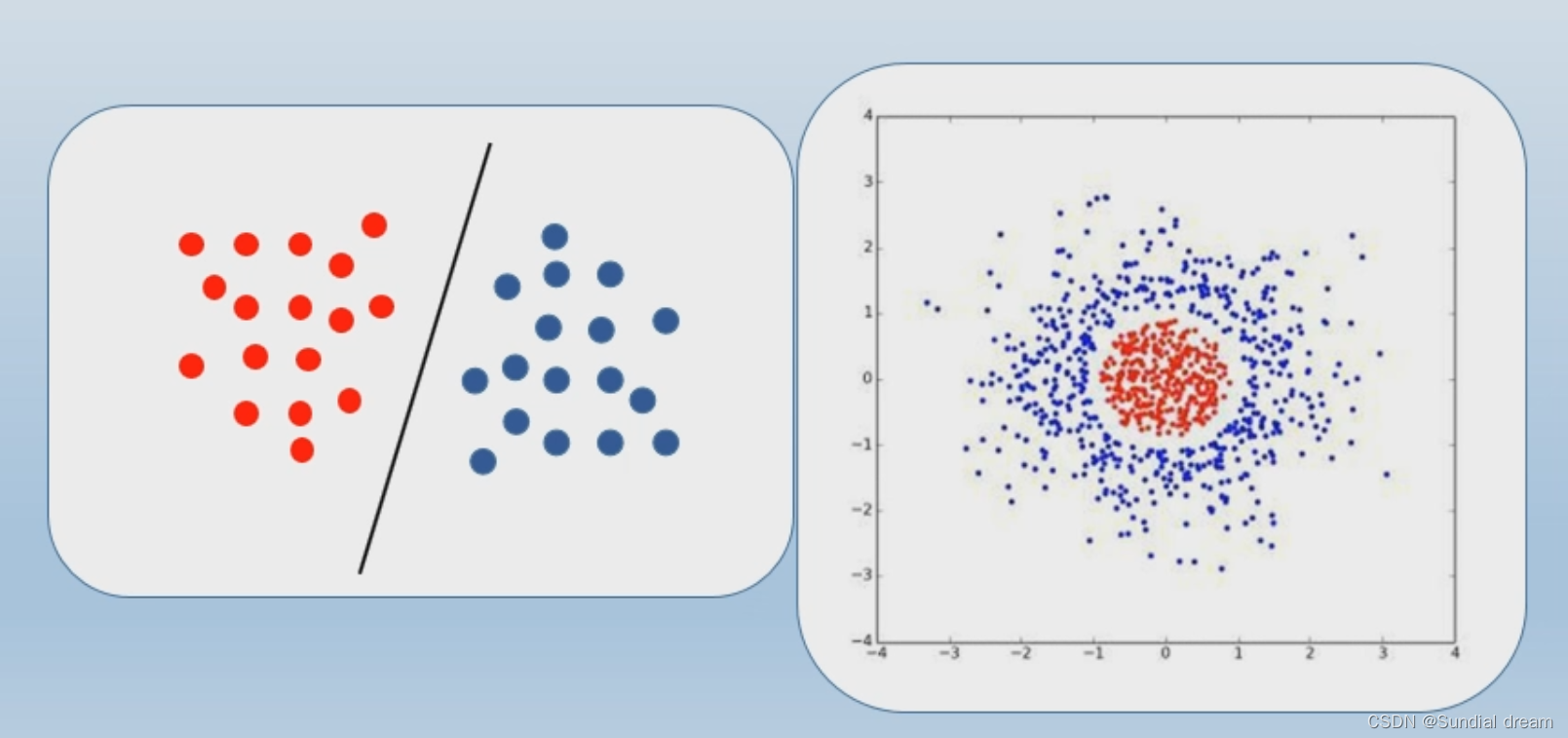
判断一堆数据是否能够线性可分的关键在于数据所在的维度
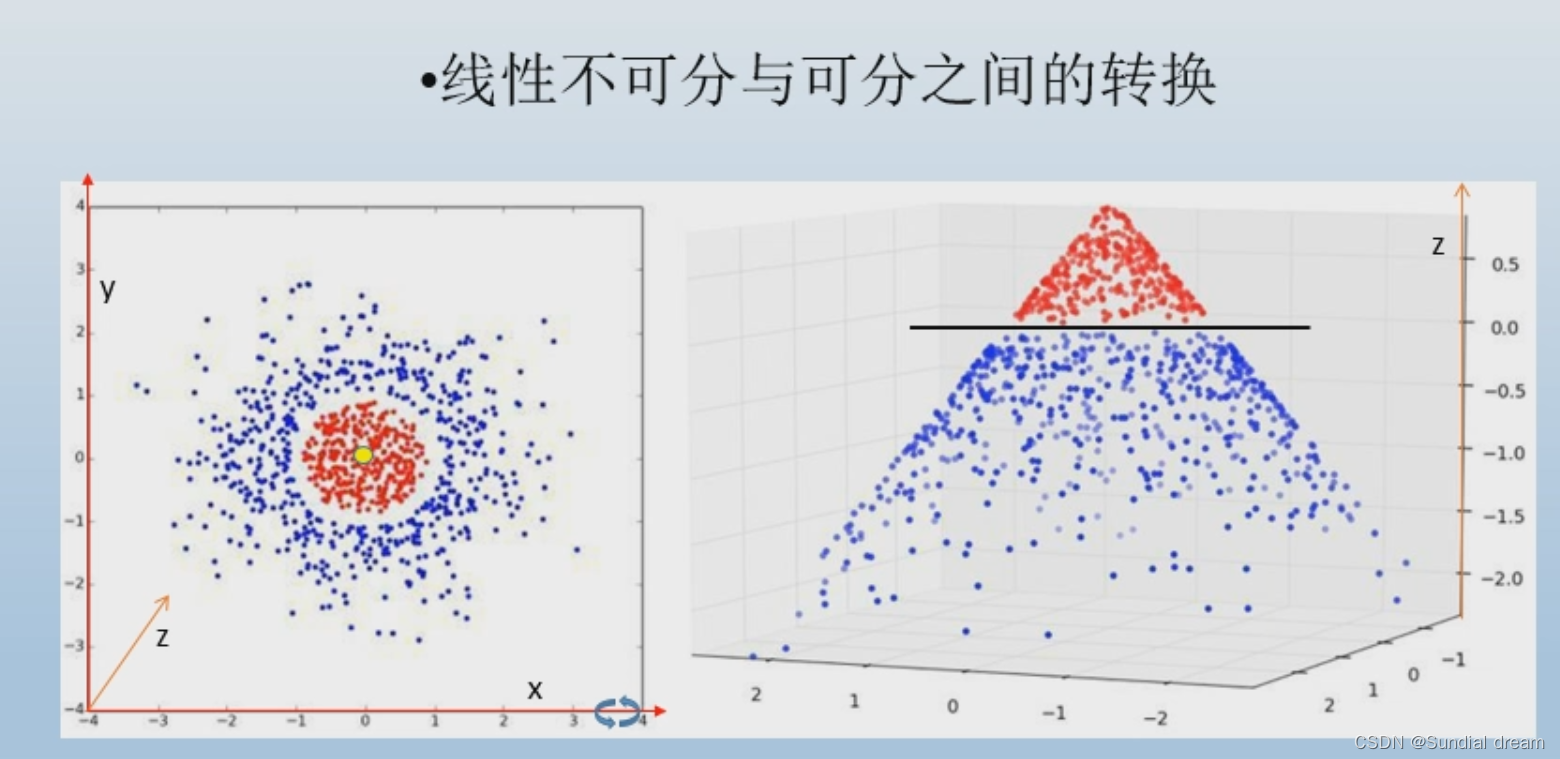
1.2.2 激活函数
激活函数的主要作用就是提供网络的非线性建模能力;
非线性建模能力可以看做是数据从一个空间映射到另一个空间的过程
1.3感知机模型
1.3.1感知机的来源
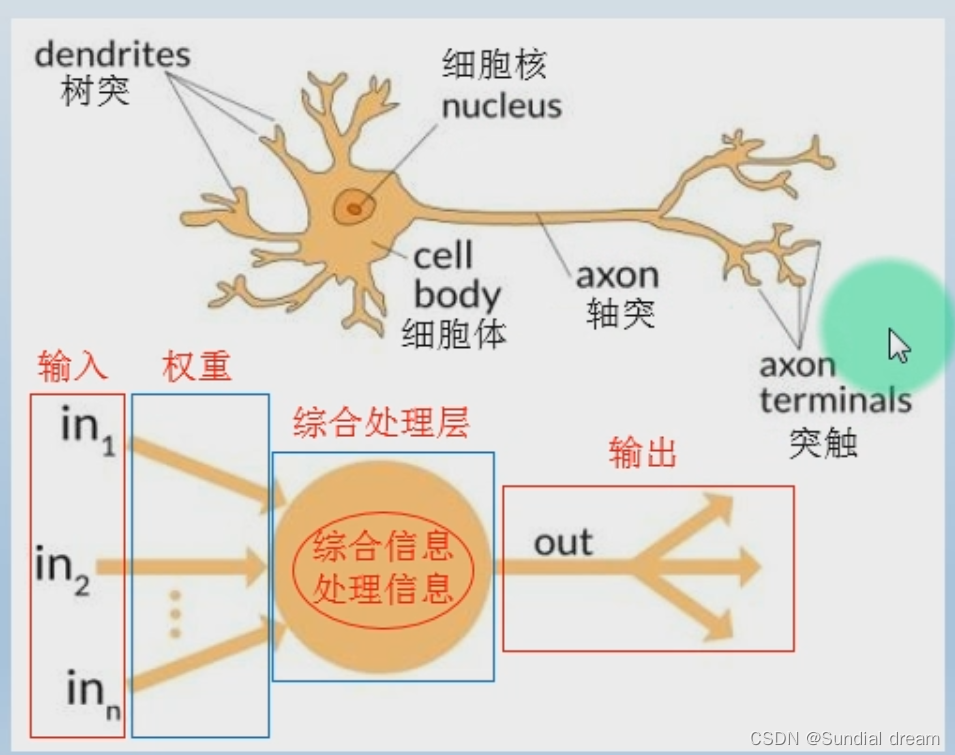
例如:感知器是一组实数向量作为输入,计算这些输入的线性组合,如果结果大于设定的阈值就输出1,否则输出-1.
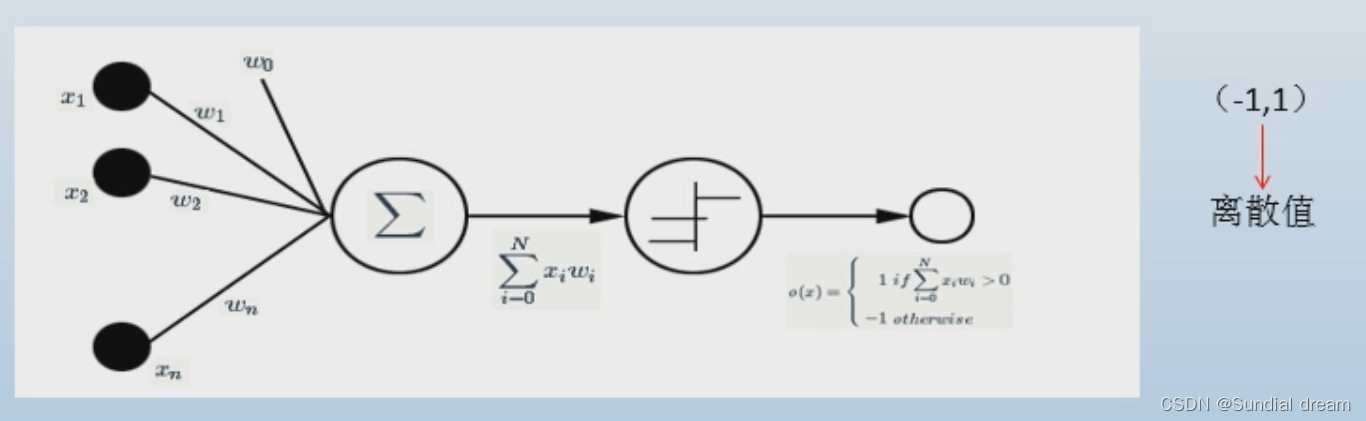
output=f(wx+b)
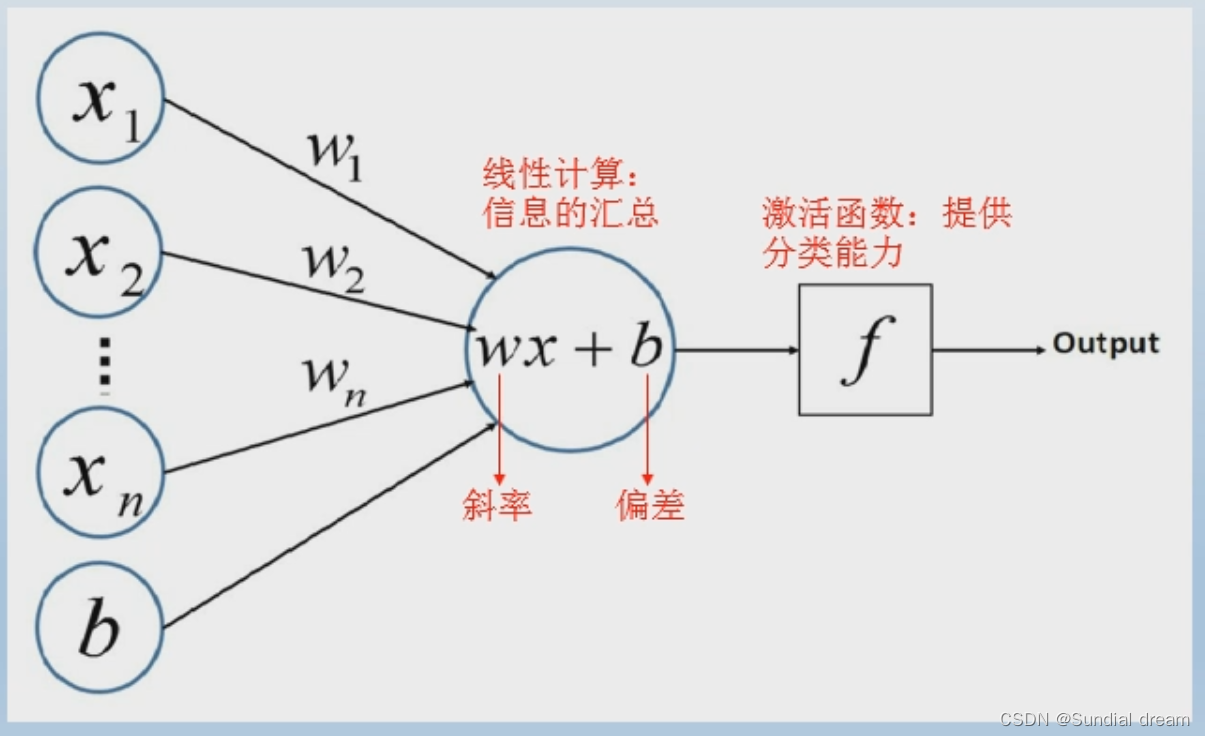
1.3.2感知机的演变
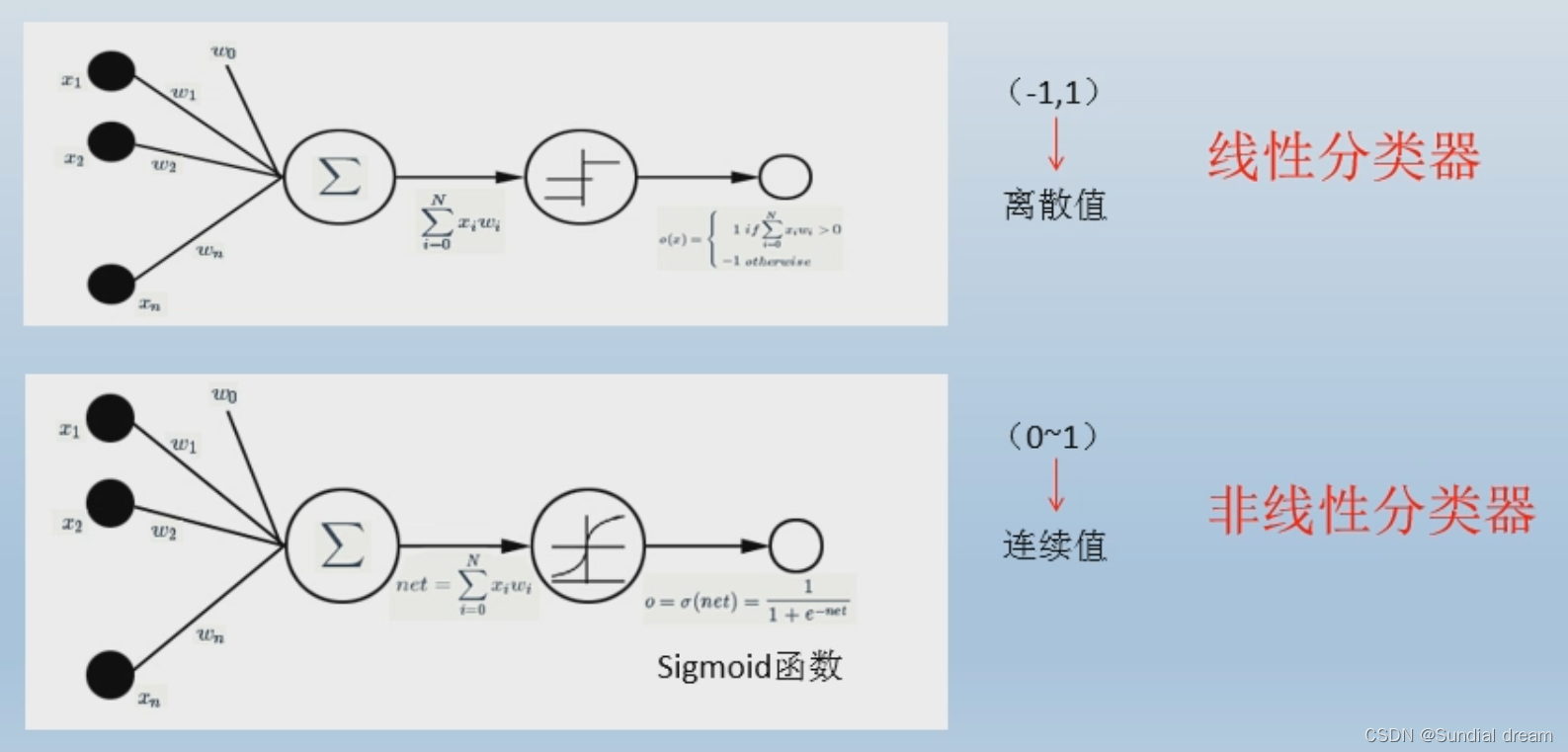
多层感知机结构
(多层感知机也称为深度学习神经网络DNN)
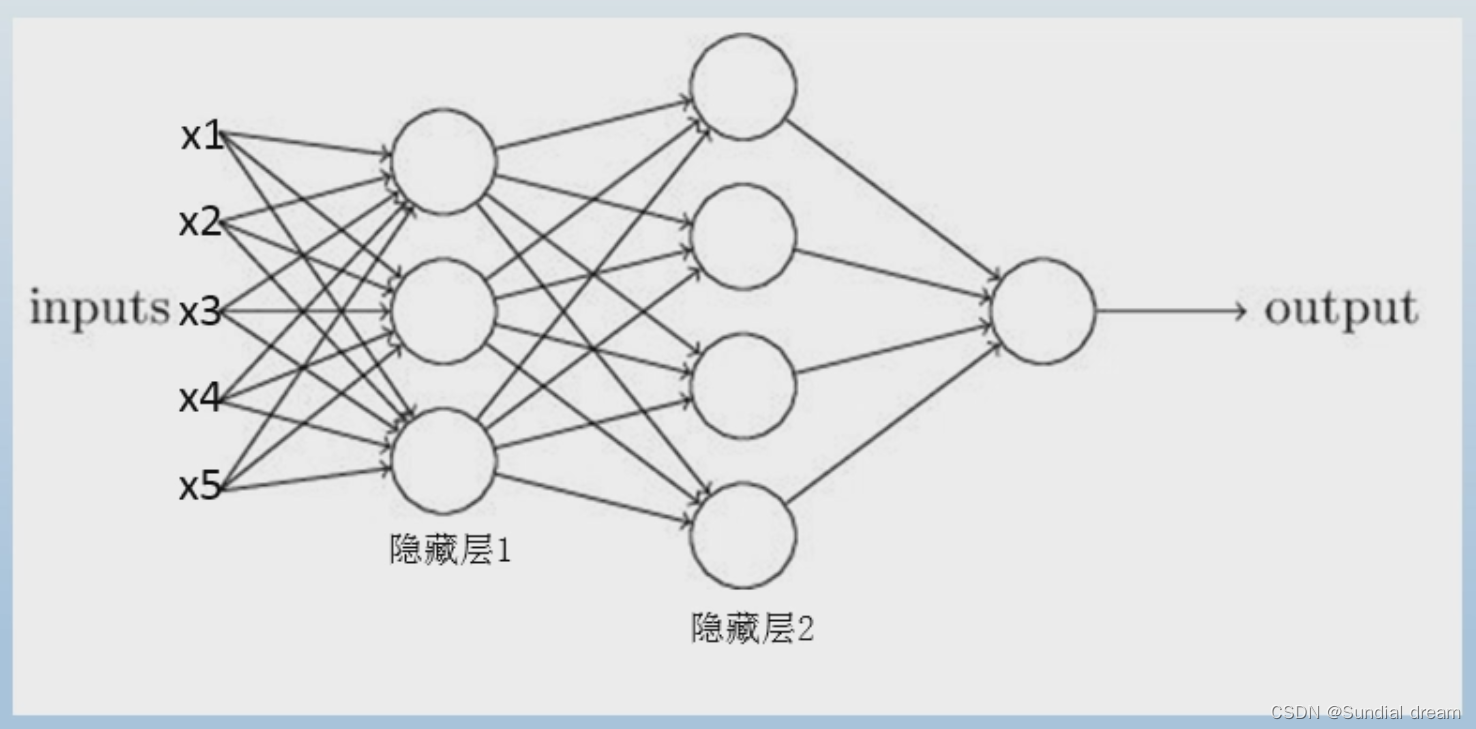
1.4神经网络
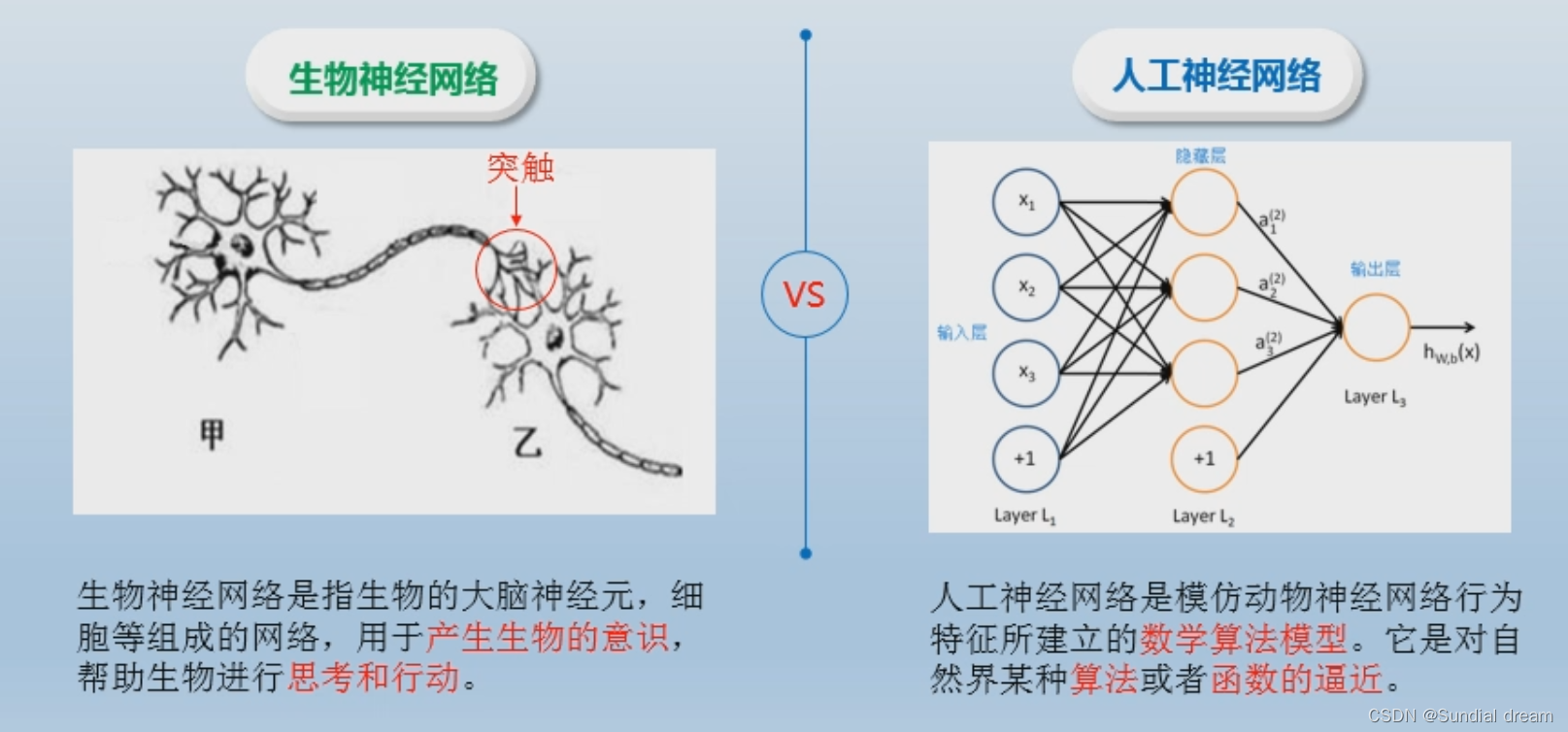
1.4.1前向传播
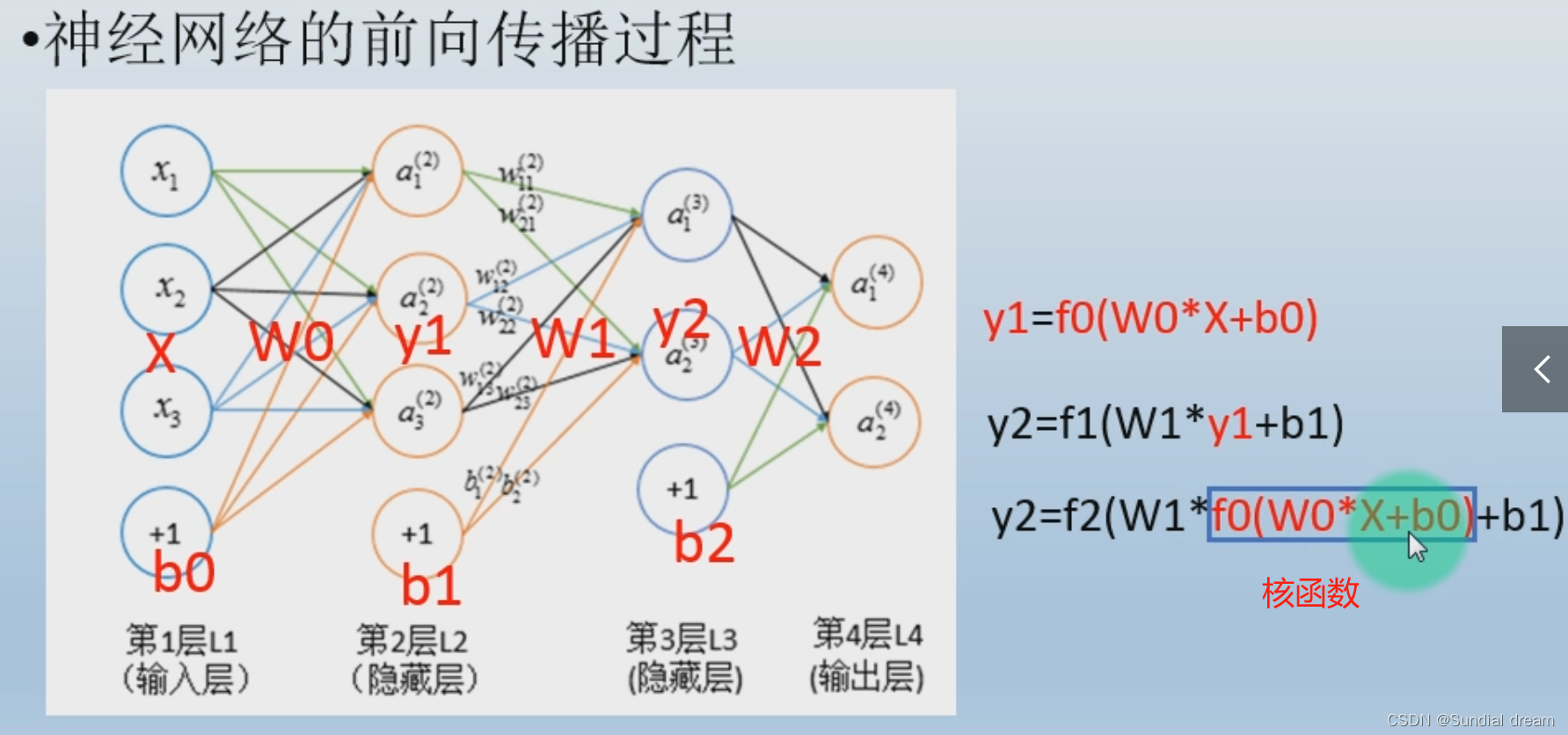
1.4.2后向传播


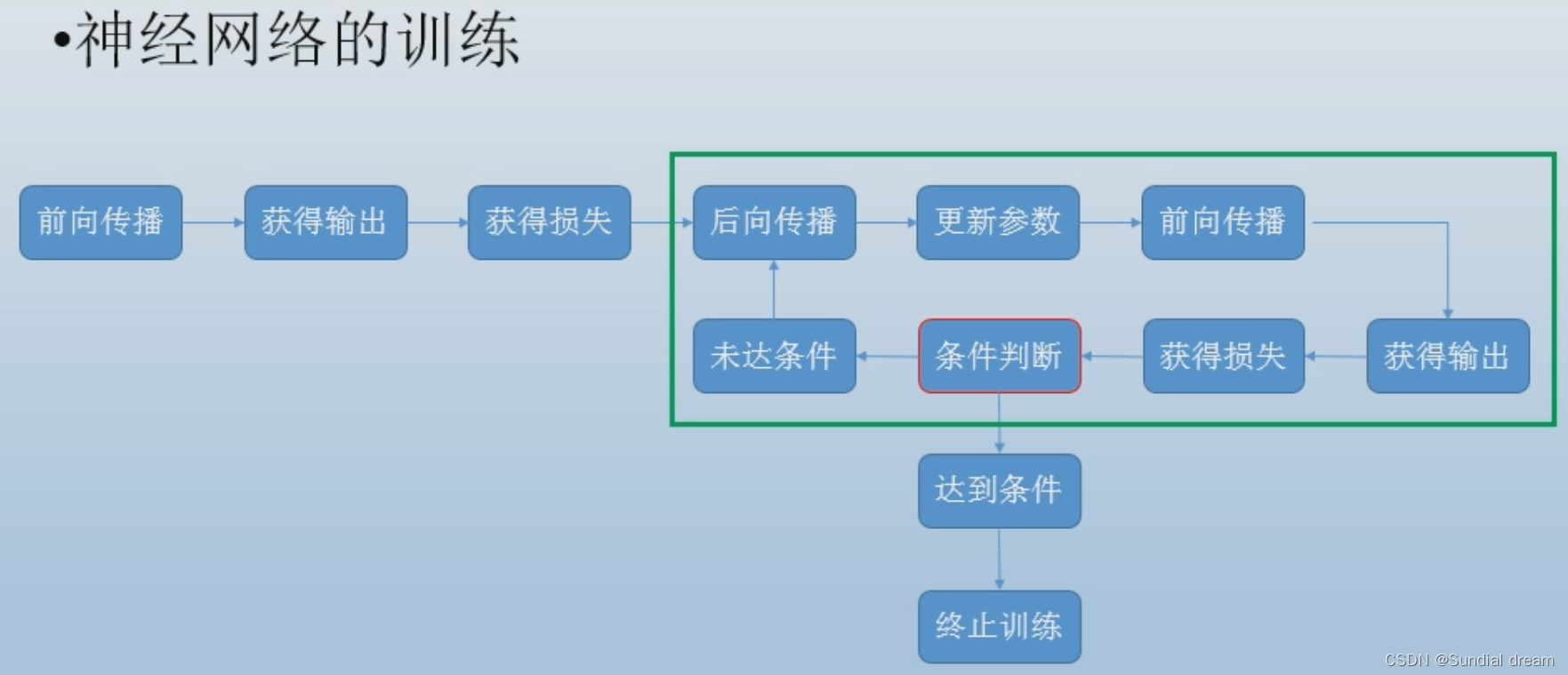
1.4.3神经网络的训练
1.5 损失函数
1.5.1损失是什么

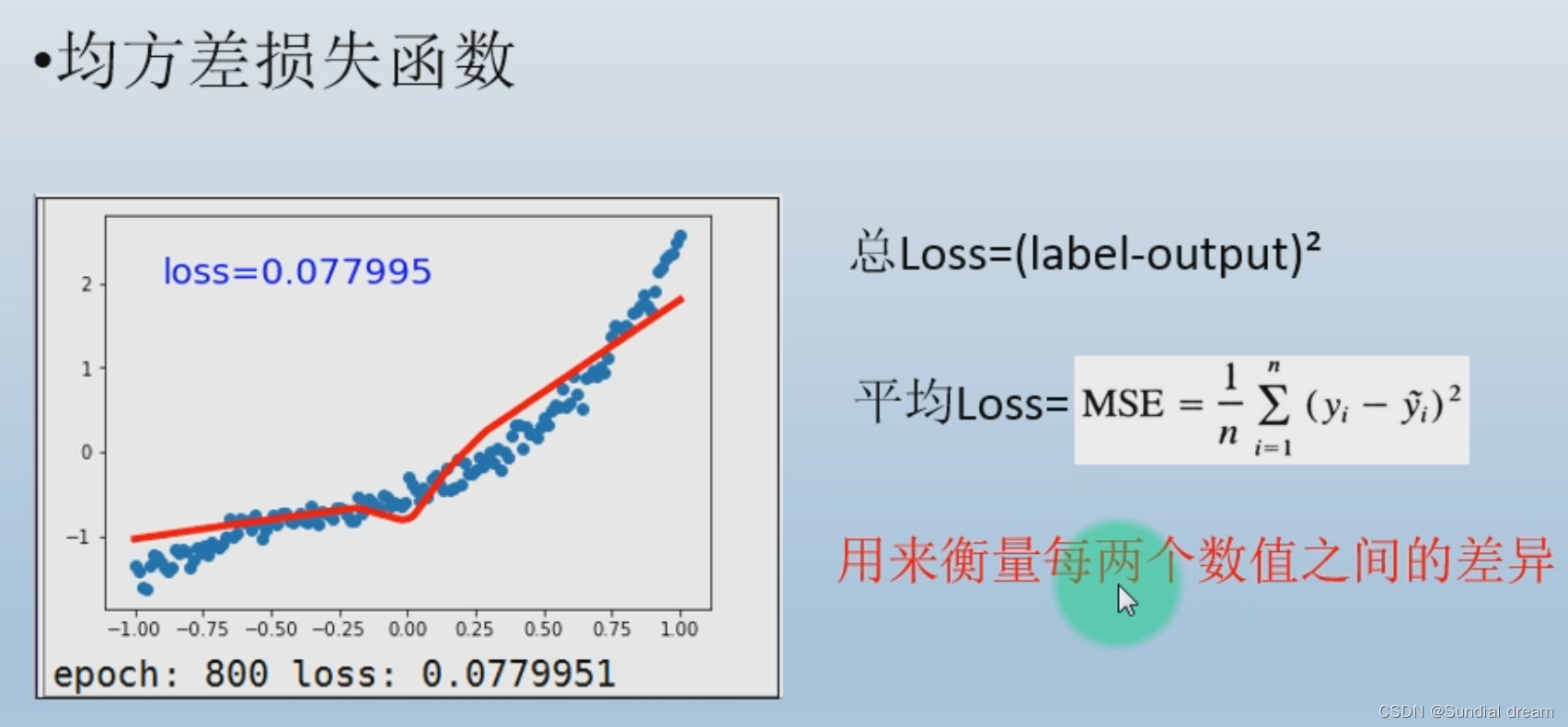
1.5.2 均方差损失函数
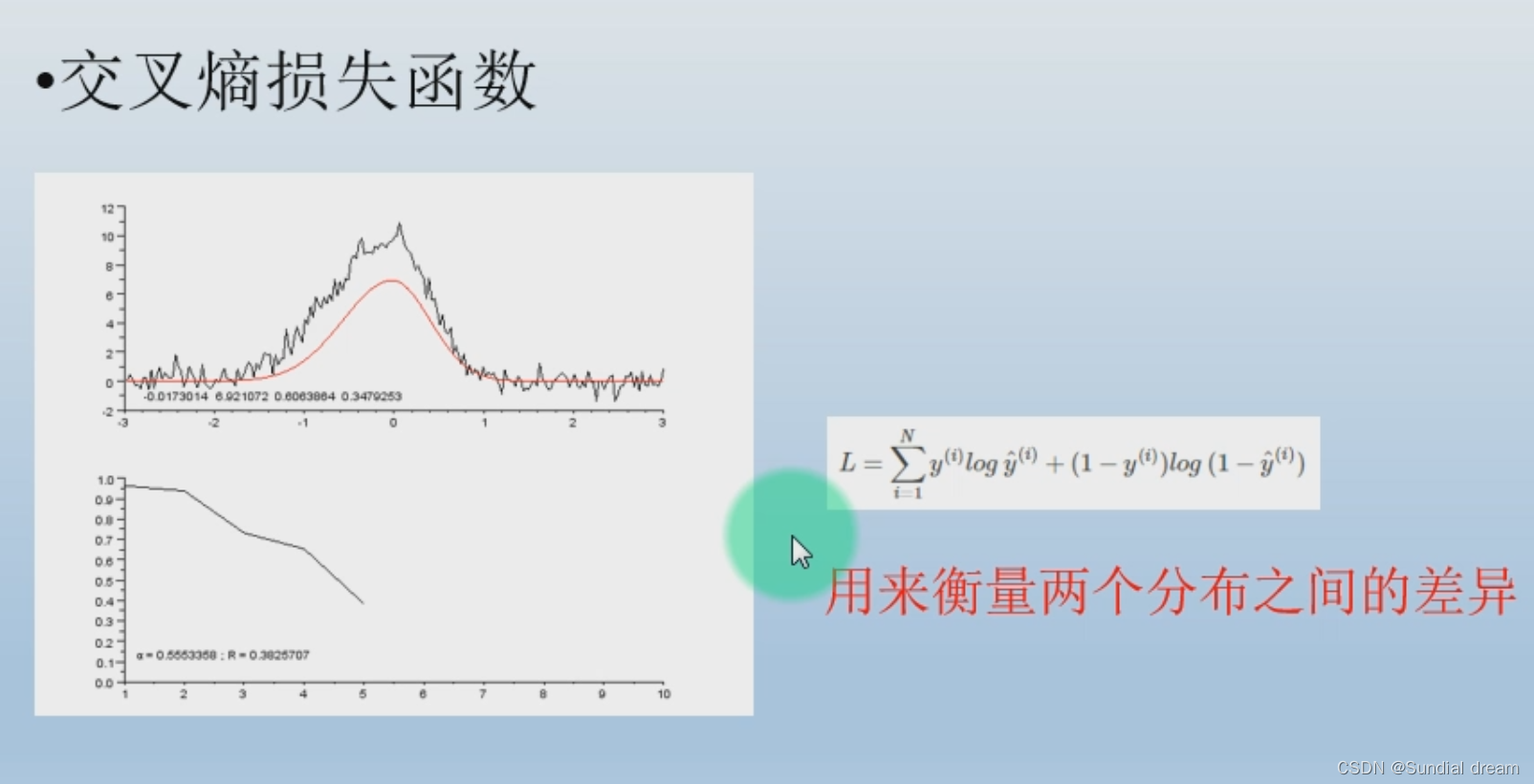
1.5.3交叉熵损失函数
1.6 参数更新

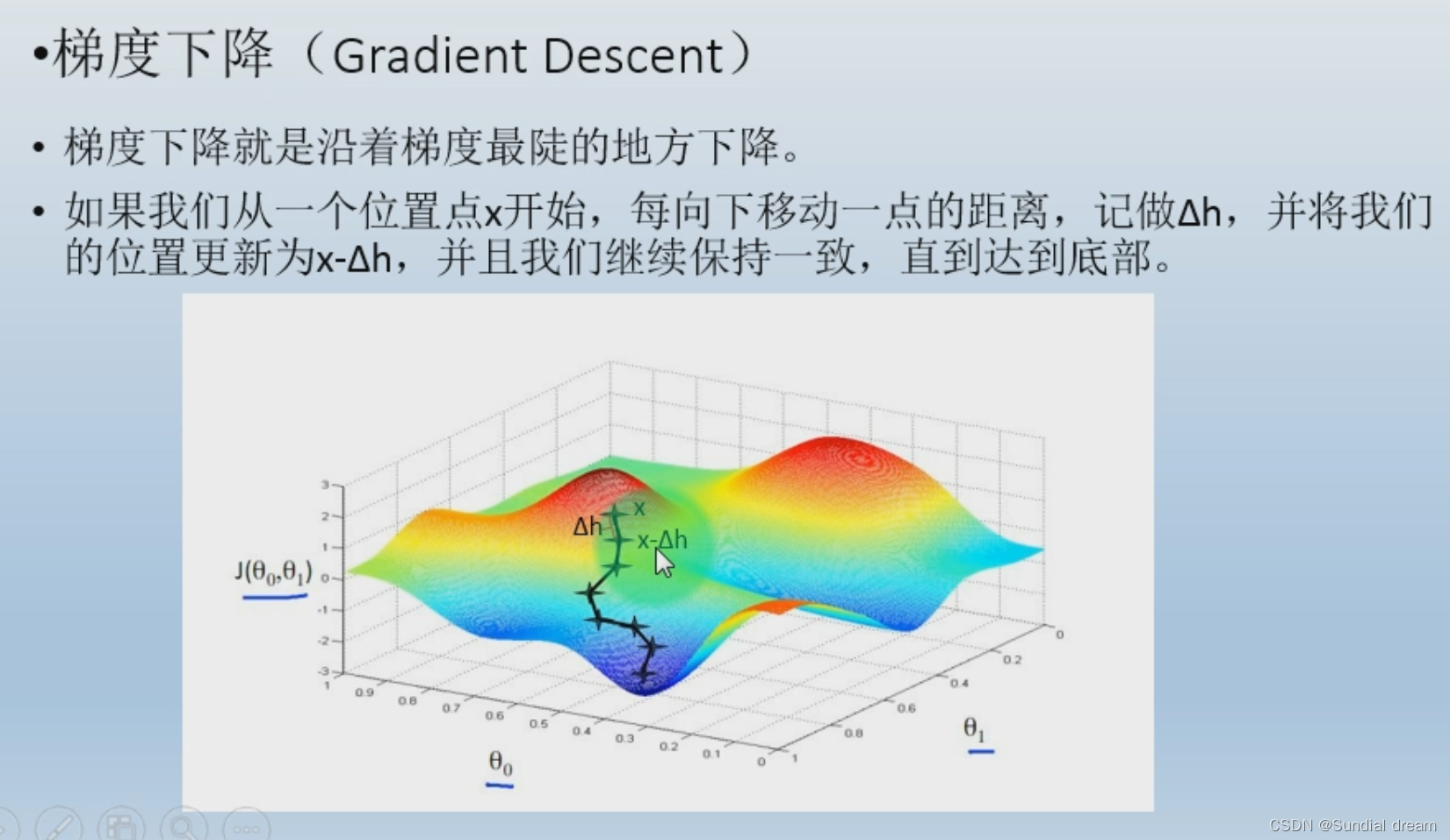
梯度下降
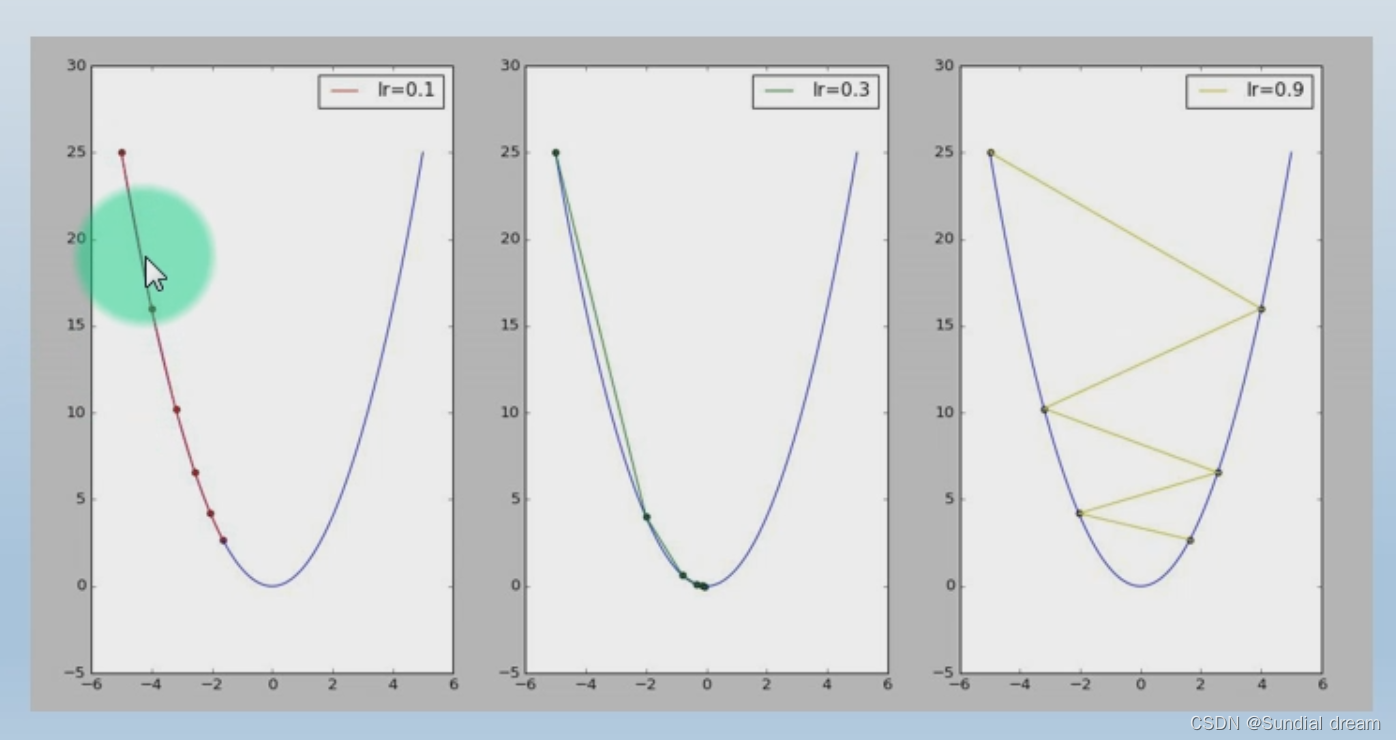
学习率(下降多少合适)
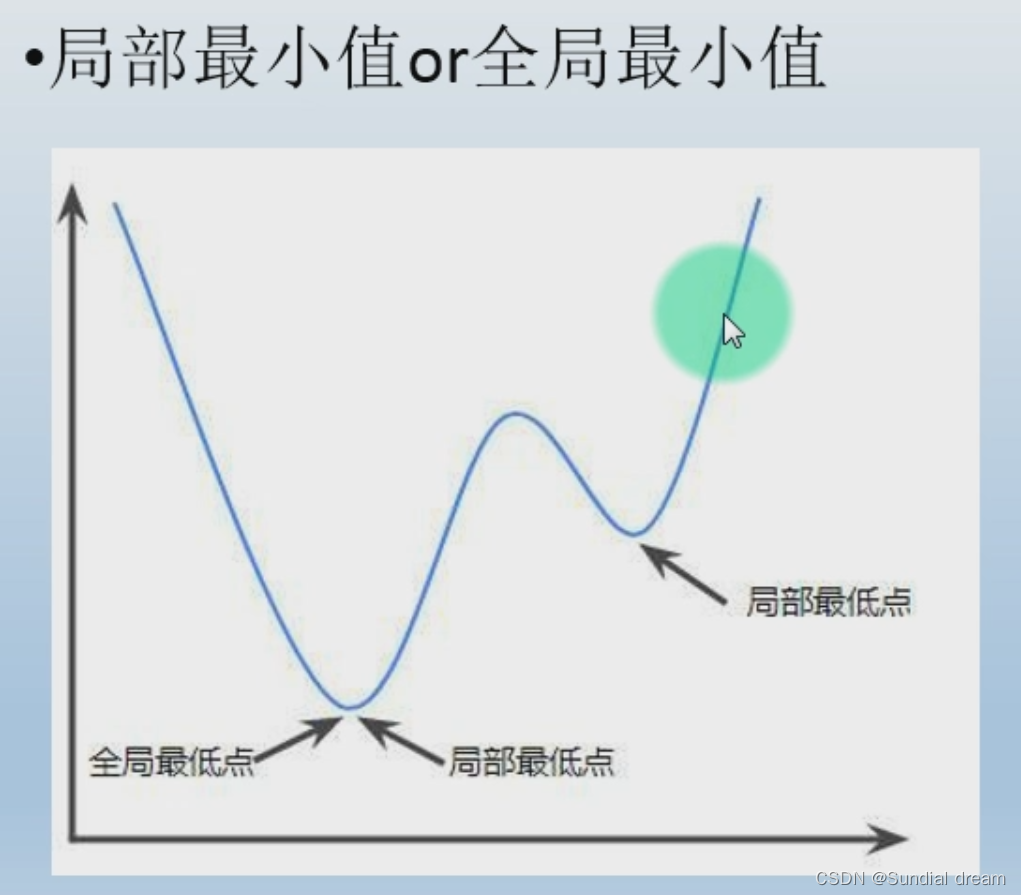
1.7样本
研究中实际观测或调查的一部分个体,不仅做为神经网络模型学习数据特征的来源,还要负责验证和评估模型的好坏程度;
可将数据分为三类 三者比例 6:2:2或8:1:1:
训练集:用来学习;
验证集 用来评判模型性能;
测试集 在现实中检测。
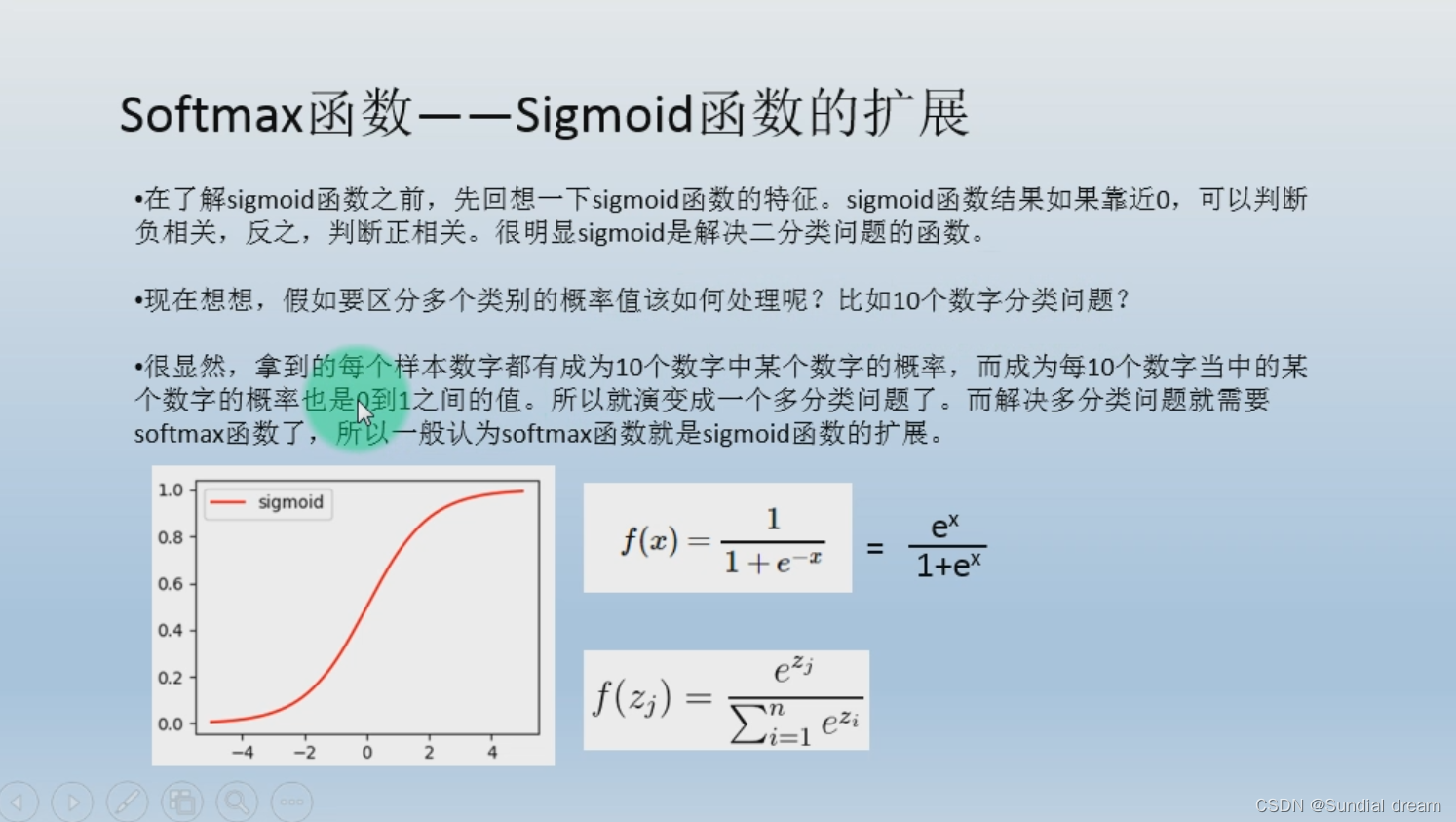
1.8 softmax函数
1、Softmoid函数的扩展
softmoid函数是解决二分类问题的函数,如果要区分多个类别急需要用到softmax
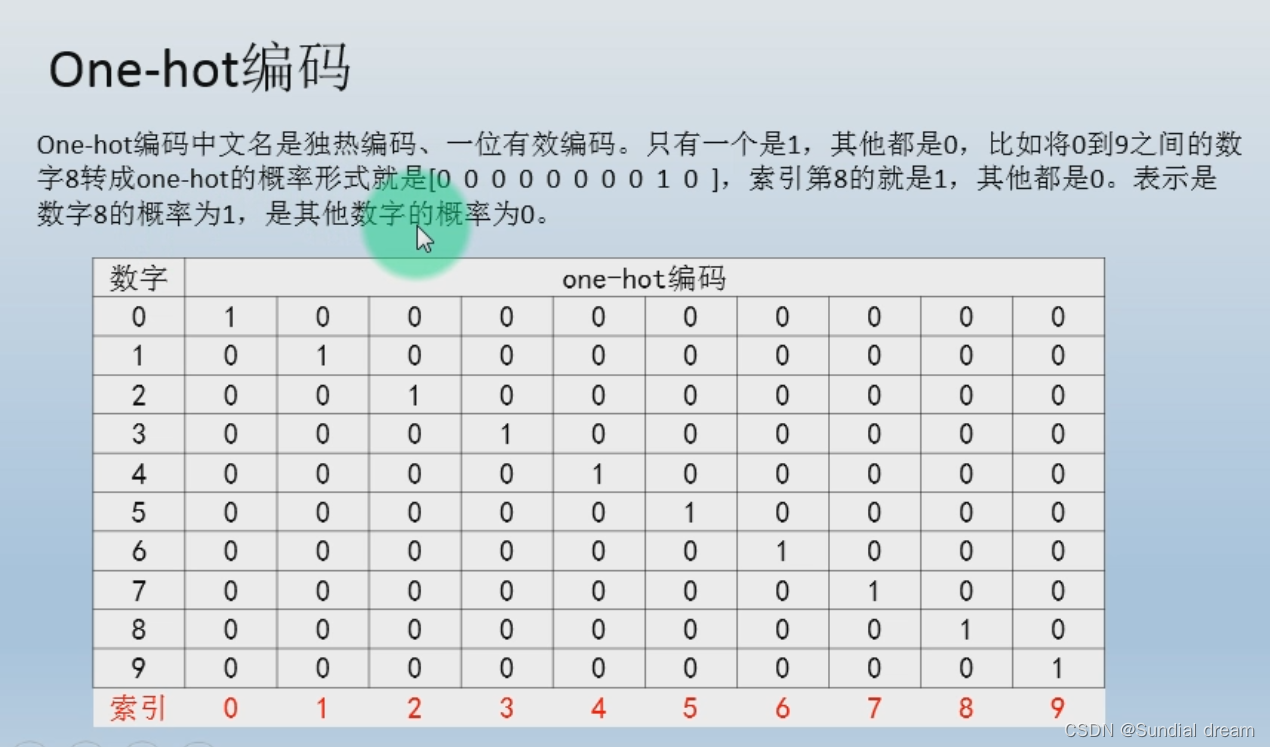
1.9 onehot
1.9.1onehot编码
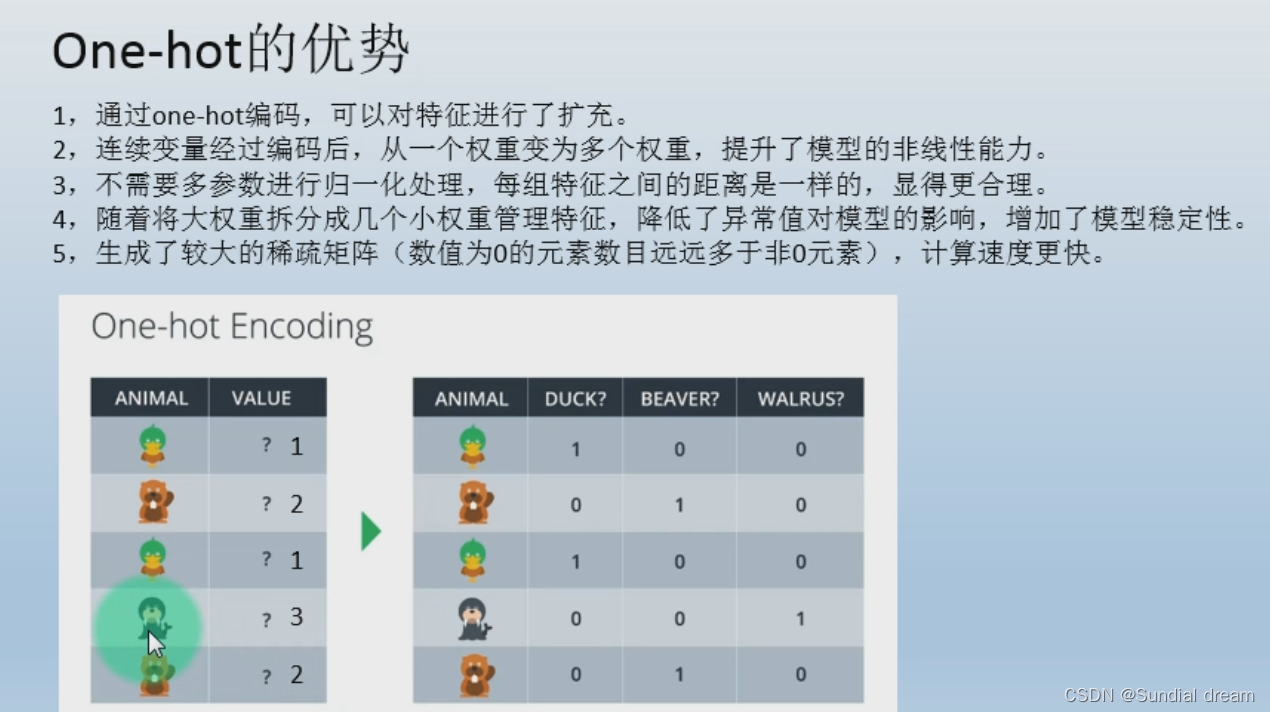
1.9.2 onehot优势
 1.9.3 softmax与onehot结合
1.9.3 softmax与onehot结合

2.0 tensorflow(简单网络实现代码)
tensorflow分为两部分,第一步先搭图;第二部会话
这个是一个两层的0-9数字手写识别代码
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets(".\MNIST_data",one_hot=True)
# mnist = ".\MNIST_data"
import matplotlib.pyplot as plt
class Net:
def __init__(self):
#输入信息
self.x = tf.placeholder(dtype=tf.float32,shape=[None,784])
#输入信息的标签
self.y = tf.placeholder(dtype=tf.float32,shape=[None,10])
#W 权重 [784,256]数字设置由网络与输入数据决定
self.w1= tf.Variable(tf.truncated_normal(shape=[784,256],stddev=0.01,dtype=tf.float32))
#B
self.b1= tf.Variable(tf.zeros(shape=[256],dtype=tf.float32))
#第二层
self.w2= tf.Variable(tf.truncated_normal(shape=[256,10],stddev=0.01,dtype=tf.float32))
self.b2= tf.Variable(tf.zeros(shape=[10],dtype=tf.float32))
#前向
def forward(self):
y1 = tf.nn.relu(tf.matmul(self.x,self.w1)+self.b1)
self.y2 = tf.matmul(y1,self.w2)+self.b2
self.output = tf.nn.softmax(self.y2)
#损失
def loss(self):
self.error = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=self.y,logits=self.y2))
#后向 更新权重
def backward(self):
self.optimizer = tf.train.GradientDescentOptimizer(0.001).minimize(self.error)
#准确率
def accuracy(self):
y = tf.equal(tf.argmax(self.output,axis=1),tf.argmax(self.y,axis=1))
self.acc = tf.reduce_mean(tf.cast(y,dtype=tf.float32))
if __name__ == '__main__':
net= Net()
net.forward()
net.loss()
net.backward()
net.accuracy()
init = tf.global_variables_initializer()
plt.ion()
a=[]
b=[]
c=[]
with tf.Session() as sess:
sess.run(init)
for i in range(50000):
xs,ys = mnist.train.next_batch(100)
error,_ = sess.run([net.error,net.optimizer],feed_dict={net.x:xs,net.y:ys})
if i%100 == 0:
xss,yss = mnist.validation.next_batch(100)
_error,_output,acc = sess.run([net.error,net.output,net.acc],feed_dict={net.x:xss,net.y:yss})
label= np.argmax(yss[0])
out = np.argmax(_output[0])
print("error:",error)
print("label:",label,"output:",out)
print(acc)
a.append(i)
b.append(error)
c.append(_error)
plt.clf()
train, = plt.plot(a,b,linewidth = 1,color = "red")
validate, = plt.plot(a,c,linewidth = 1, color = "blue")
plt.legend([train,validate],["train","validate"],loc= "right top",fontsize = 10)
plt.pause(0.01)
plt.ioff()














 38万+
38万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









