






yolov8s+Gem全局注意力,助你大幅涨点
一、介绍
YOLOv8是一个高性能的计算机视觉模型,用于物体检测、分割、姿态估计等任务。每个YOLOv8模型的变体都针对其相应的任务进行了优化,确保了高性能和准确性。这些模型与不同的操作模式兼容,包括推断、验证、训练和导出,便于在部署和开发的不同阶段使用。
以YOLOv8s为例,这个模型版本在COCO数据集上训练的平均精度(mAP值)为44.9,拥有大约2860万的参数和大约286亿的浮点运算。YOLOv8模型系列的这种多功能性和健壮性使它们适用于计算机视觉中的多种应用。
然而,每种模型都有其局限性。YOLOv8s可能存在的弊端包括处理高分辨率图像时的速度变慢,以及可能在非常复杂或拥挤的场景中检测性能下降。此外,由于它使用的是基于锚点的检测方法,因此可能对一些不常见的物体形状或不规则大小的物体检测不足。
相较原版YOLOv8s模型,我们添加了全局注意力机制,即可以通过保留空间和通道信息之间的关联来提高模型的性能。将输入特征映射通过通道注意力子模块和空间注意力子模块形成GAM的输出特征
二、实现过程
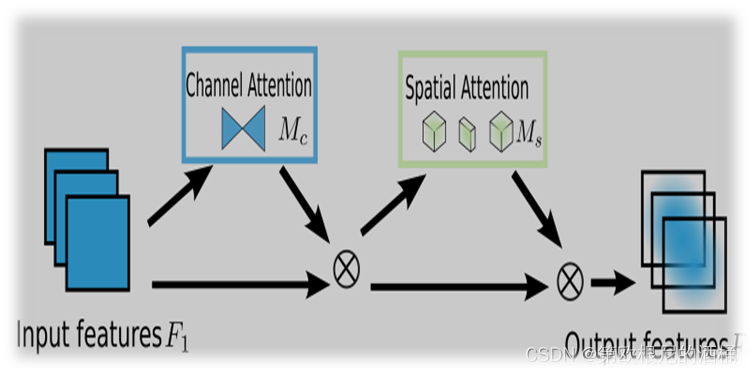 图一 GAM输出特征实现过程
图一 GAM输出特征实现过程
- 通道注意力(channel)
第一步处理将输入通道数从in_channels减少到输出的int(in_channels / rate)。这一步降低了特征的维度,减少了后续计算的复杂性。
ReLU 激活:ReLU激活函数引入非线性,有助于模型学习更复杂的特征表示。
再升维操作:第二个nn.Linear层将通道数从int(in_channels / rate)恢复到 in_channels。这一步恢复了特征的原始维度。 - 空间注意力 :
首先对第一层卷积做降维处理,减少计算量,同时对输出进行批归一化,第二层卷积将特征维度恢复到原始输入特征的维度,对第二层卷积的输出再次进行批归一化,进一步稳定网络训练。 - 特征加权应用
在通道注意力和空间注意力计算完后,计算出的加权结果被应用于原始输入特征x。通过这种方式,原始特征被重新加权,使得网络的焦点更集中于那些被认为更重要的通道和空间区域。

三、代码实现
(参考博客:http://t.csdnimg.cn/uGMff)
1.修改ultralytics-main\ultralytics\nn\modules\conv.py,添加代码
import torch
import torch.nn as nn
class GAM_Attention(nn.Module):
def __init__(self, in_channels, c2, rate=4):
super(GAM_Attention, self).__init__()
self.channel_attention = nn.Sequential(
nn.Linear(in_channels, int(in_channels / rate)),
nn.ReLU(inplace=True),
nn.Linear(int(in_channels / rate), in_channels)
)
self.spatial_attention = nn.Sequential(
nn.Conv2d(in_channels, int(in_channels / rate), kernel_size=7, padding=3),
nn.BatchNorm2d(int(in_channels / rate)),
nn.ReLU(inplace=True),
nn.Conv2d(int(in_channels / rate), in_channels, kernel_size=7, padding=3),
nn.BatchNorm2d(in_channels)
)

2.注册及引用GAM注意力代码,修改ultralytics-main\ultralytics\nn\modules\__init__.py

ultralytics-main\ultralytics\nn\tasks.py

tasks里写入调用方式
在700行的位置左右,注意对照图片
elif m in {GAM_Attention}:
c1, c2 = ch[f], args[0]
if c2 != nc: # if not output
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]

修改yaml文件
yolov8s-Backbone-ATT.yaml
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 8 # number of classes 自定义
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8-SPPCSPC.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.43, 0.45, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.68, 0.68, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 3, GAM_Attention, [1024]]
- [-1, 1, SPPF, [1024, 5]] # 10
#C2f_DySnakeConv
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
# - [-1, 3, GAM_Attention, [1024]]
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
3训练

在源目录下新建py文件,即可运行
from ultralytics import YOLO
if __name__ == '__main__':
# 加载模型
model = YOLO("yolov8s-Backbone-ATT.yaml") # 从头开始构建新模型
#model = YOLO("yolov8s.yaml")
#model = YOLO("/home/hd/Desktop/WpPYProject/ultralytics-main/runs/detect/cfg35/weights/best.pt") # 加载预训练模型(推荐用于训练)
# Use the model
results = model.train(data="./ultralytics/cfg/datasets/new.yaml", epochs=120, batch=16, workers=16,close_mosaic=0, name='gem') # 训练模型
# results = model.val() # 在验证集上评估模型性能
# results = model("https://ultralytics.com/images/bus.jpg") # 预测图像
#success = model.export(format="onnx") # 将模型导出为 ONNX 格式
#python -m torch.distributed.launch --nproc_per_node=4 main.py
四、消融实验
消融实验(Ablation Study)是一种科学研究方法,通常用于机器学习、医学和其他科学领域。在机器学习领域,消融实验的目的是理解模型的每个组成部分对模型性能的具体贡献。通过逐个移除或“消融”模型的特定部分(比如一个特征、网络层或一组参数),研究人员可以观察到每个部分的重要性以及它们对最终性能的影响。
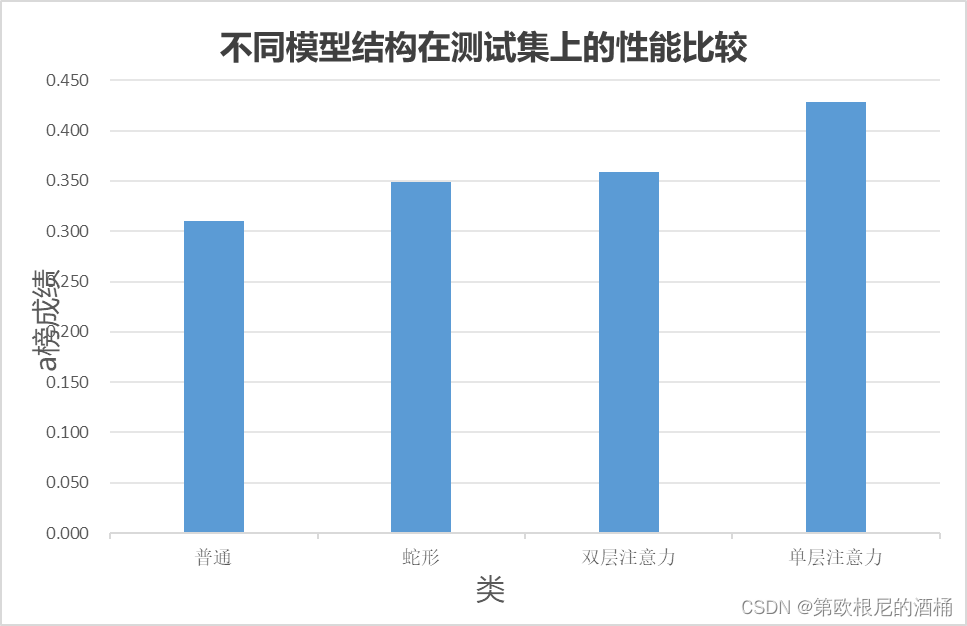
- “单层注意力”结构可能提供了最佳的性能,可能因为它在处理特定的数据集或任务时更为有效。
- “双层注意力”在这个实验中的性能不如单层,这可能意味着双层注意力并没有带来预期中的性能提升,或者可能是由于过度拟合、参数不当设置等原因导致性能下降。
















 3723
3723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











