









Shape-Erased Feature Learning for Visible-Infrared Person Re-Identification(形状擦除特征学习在可见红外人物再识别中的应用)
期刊合集:最近五年,包含顶刊,顶会,学报>>网址
文章来源:CVPR 2023
代码地址:https://github.com/jiawei151/sgiel_vireid
研究背景
可见光和红外图像之间存在的巨大模态差异及较高视觉上的模糊,学习不同模态之间的共享语义是一个具有挑战性的问题。
体型(shape)是 VI-ReID 模态共享的重要线索之一。为了挖掘更多样化的模态共享线索,作者希望在学习特征中删除与体型相关的语义概念,可以迫使模型提取更多和其他模态共享特征进行识别。为此,文章提出 在两个正交子空间中解相关模态共享特征的形状擦除特征学习范式。在一个子空间中共同学习形状相关特征和在正交补中共同学习形状擦除特征,实现了形状擦除特征与丢弃身体形状信息的身份之间的条件互信息最大化,从而显着增强了学习表征的多样性。
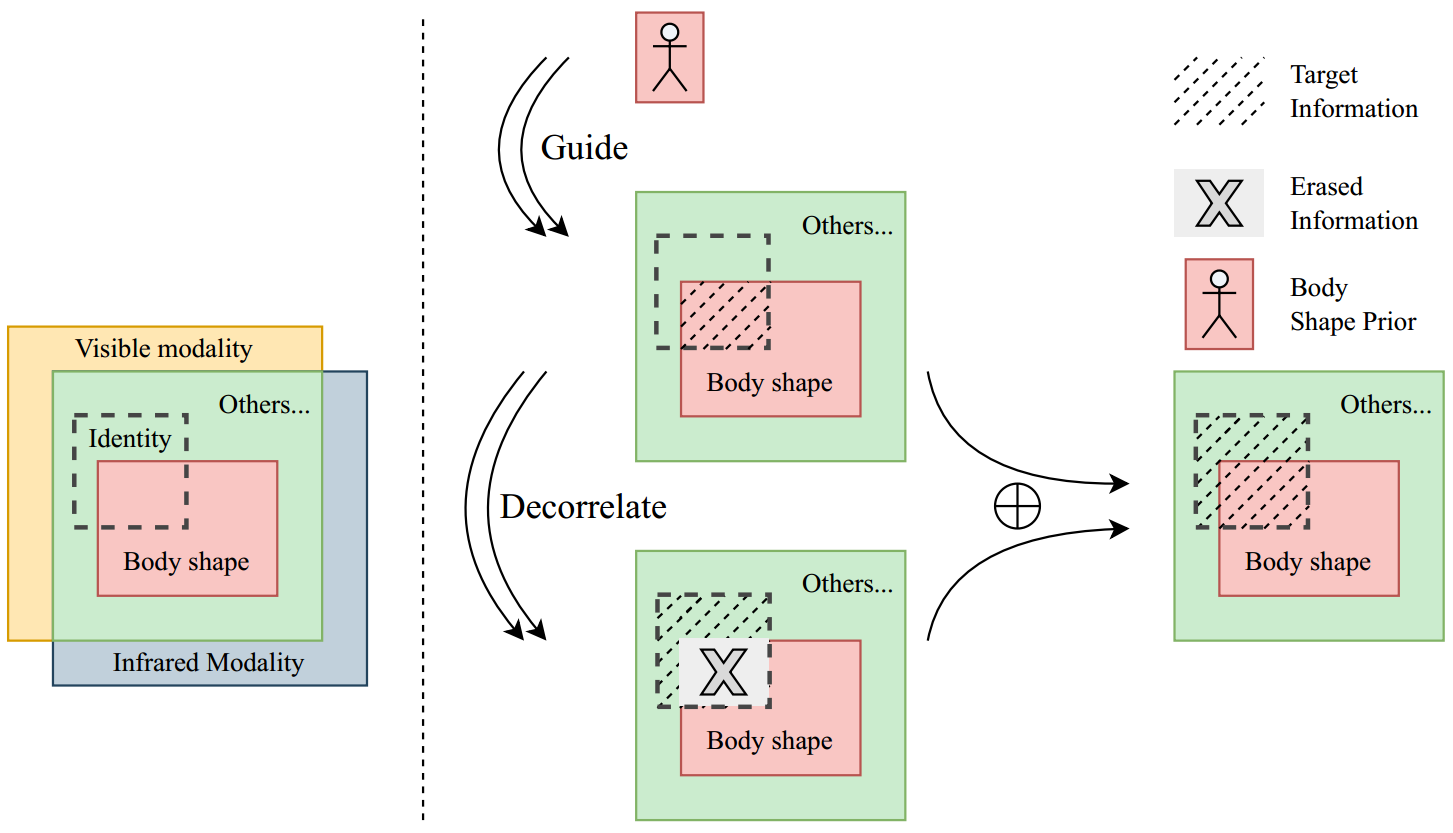
在VI-ReID的线索中,我们可以在许多情况下通过行人的身体形状来识别行人,因为它包含了模态不变信息,并且对光线变化具有鲁棒性。然而,体型并不是解释一个人身份的唯一或充分的语义概念。在某些情况下,仅仅根据体型来区分可能很困难,但我们仍然可以通过其他语义概念来区分他们,比如他们的物品、发型或面部结构。受此启发,我们在图1中虚线左侧的V enn图中说明了可见和红外模态之间的信息理论度量。假设体型(红色表示)和身份相关的模态共享信息(虚线框表示)部分重叠。
需要注意的是部分原因还在于1 arXiv:2304.04205v1 [cs]中包含了与身份无关的信息。身体形状图,例如人体姿势。这种部分重叠的假设表明,VI-ReID的目标信息是身份相关和模态共享的,可以分为两个与体型相关和不相关的独立成分。
基于以上的观察和假设,为了挖掘更多的VI-ReID模态共享线索,我们希望能够删除特征中与体型相关的语义概念,迫使VI-ReID模型提取更多的其他模态共享特征进行识别。如图1虚线右侧所示,将形状擦除的特征与形状相关的特征去相关,同时发现与形状无关的知识,而形状相关的特征可以通过某种给定的身体形状先验来明确引导,这很容易通过现有的预训练的人类解析模型获得[17]。这样,形状相关特征和形状擦除特征都被明确量化,而这两个特征的判别性可以独立保持。
具体而言,我们提出了形状擦除特征学习范式,该范式将正交性引入表征以满足独立约束的放松。然后将该表征分解为位于两个正交子空间中的两个子表征,分别用于形状相关和形状擦除的特征学习。通过在一个子空间中学习和覆盖大多数可判别的体型特征,形状擦除特征被迫在另一个子空间中发现其他模态共享的可判别语义概念,因为形状相关特征在其正交补中受到约束。在上述假设下,我们从互信息的角度构建了这种形状擦除特征学习范式,并证明了形状擦除和形状相关目标的联合学习实现了形状擦除特征与丢弃身体形状信息的身份之间的条件互信息最大化,从而显着增强了学习表征的多样性。最后,我们设计了一个形状引导的多元特征学习框架(SGIEL),该框架共同优化形状相关目标和形状擦除目标,以学习模式共享和判别集成表示。我们的工作贡献总结如下:
作者提出了一种用于 VI-ReID 任务的形状擦除特征学习范式,该范式通过正交分解的方式将形状擦除特征与形状相关特征解相关。具体来说,在一个子空间中,形状相关的特征以身体形状先验(Body Shape Prior)为导向,而形状擦除的特征在其正交补中被约束,从而发现更多其他模态共享的判别语义概念,从而显著增强了学习表征的多样性。
基于所提出的形状擦除特征学习范式,设计了一个形状引导的多样化特征学习框架,该框架联合优化形状相关目标和形状擦除目标,以学习模式共享和判别集成表示。
论文分析
网络框架
3.1、Preliminary(相关准备工作)
VI-ReID Setup
利用随机变量 X(i) 和 Y 来分别表示 VI-ReID 任务中的数据和标签,其中 i = 1 时表示可见模态,i = 2 时表示红外模态。利用 X(i) 和 Y 的观测值构建数据集 D = {D (i) } 2 i=1,其中 D (i) = {X (i) j, y j} Ni j=1。每种模态的样本都是从同一组 C 个人中收集的,但每种模态的每个身份的样本数量可以任意。设 f 和 g 分别表示 图像 编码器和分类器,VI-ReID 的目标是学习一个 f 来提取不同模态和不同相机视图下不变的表示 z (i) = f (x(i)) ∈ R n。
Body Shape Data
借用预训练自我校正人类解析 (SCHP) 模型从背景中分割出人体形状。给定图像的一个像素,直接将 SCHP 预测的头部、躯干或四肢部分的概率相加,以创建身体形状图。具体来说,对于来自数据集 D 的每个样本 x (i),无论是可见光还是红外图像,使用 SCHP 生成具有相同图像大小和标签的配对体型图 x (s),即 D 与其对应的体型数据之间的一对一映射。设 f s 和 g s 分别表示 体型 图编码器和分类器, x (s) 的潜在表示为 z (s) = f s (x (s)) ∈ R m, m < n。
3.2、Shape-Erased Feature Learning Paradigm(形状擦除特征学习范式)
作者得到的范式明确量化了形状相关和形状擦除特征的关键独立假设,以及近似它的松弛。并基于这种松弛的独立约束,提出形状擦除特征学习。
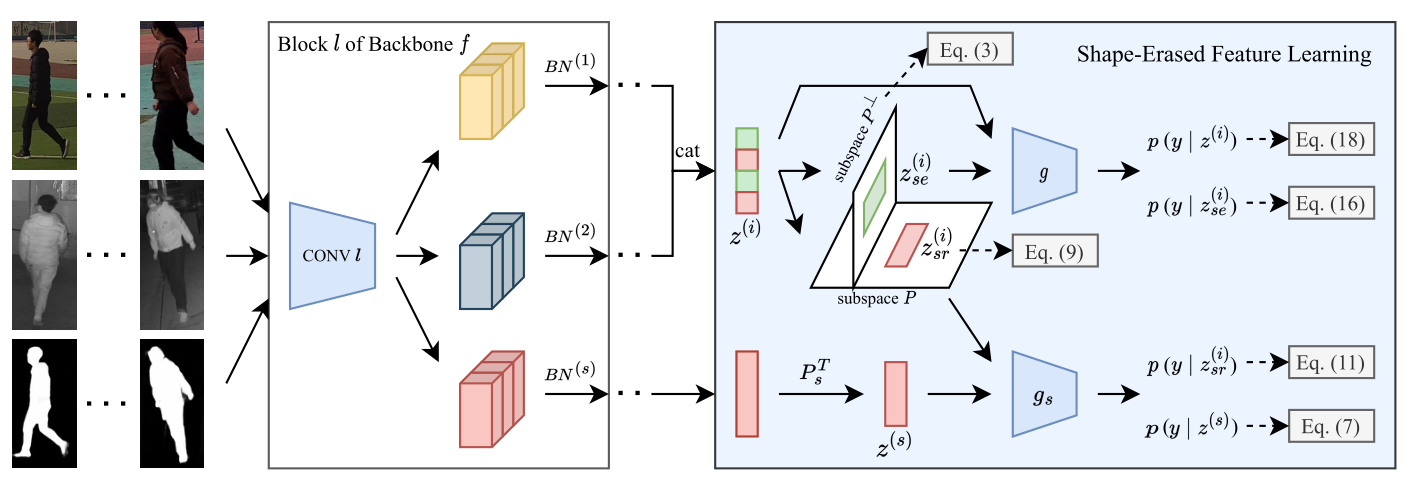
3.2.1、Independence between Z (i) sr and Z (i) se(模态共享的形状相关特征和形状擦除特征之间的独立性)
假设模态共享的形状相关特征是Z (i) sr ,模态共享的形状擦除特征 Z (i) se之间是相互独立的,并且可以从X (i) 中可以提取到整体信息表示X (i) ,由此得到, Z (i) → Z (i) sr, Z (i) → Z (i) se,这两个分量之间的独立性在相互不影响的情况下同时学习任何两个特性是必要的。
这里的独立性用数学符号表示就是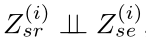
独立表达式如下:
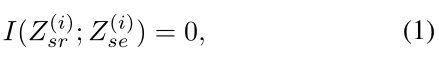
I (·;·)表示互信息,为 0 的情况就证明了括号里的两个元素之间没有任何的关系;由于互信息估计复杂且耗时,所以作者转而将独立性放宽为正交约束,表示为正交分解,得到松弛版的表达式为
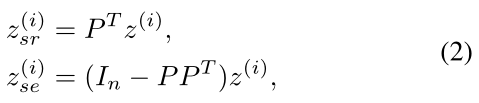
式中,P ∈ R n×m(m < n) 为半正交矩阵,P P T 是一个正交投影。
这样,形状相关的特征是在子空间 P 中学习的,而形状擦除的特征是在正交补 P⊥中学习的,近似满足独立约束。
在实践中,由于 P 通常采用标准正态分布初始化,当 n→∞时,P 变成半正交矩阵的概率趋于 1。为了进一步增强这种正交性,通过下面这个公式对 P T P与单位矩阵 I m 的各维差用 L-1 范数正则化 P:
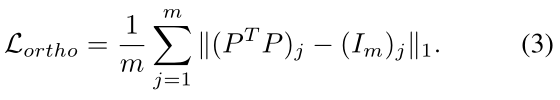
3.2.2、Shape-Erased Feature Learning
论文的最终目标是明确量化 Z (i) sr 和Z (i) se,以便Z (i) se可以在丢弃用于描述X (s)的信息时推断出 Y 的身份。这可以表示为给定体型 X (s) 的 Z (i) se 和 Y 之间的条件互信息最大化:
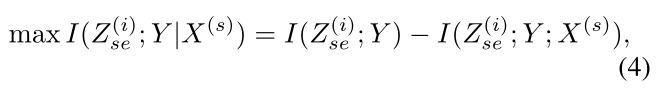
式子中的两项表示互消息。
接着作者做了两个操作:最大化前者,最小化后者
Maximize I( Z (i) se ; Y ).
交叉熵公式:
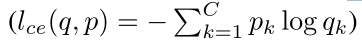
这里通过上述最小化交叉熵来将公式变型:
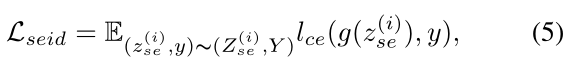
Minimize I(Z (i) se; Y; X (s) )
其中 I(Y; X(s)) 是难以处理的,可以用下面两步近似得到它,简化运算。
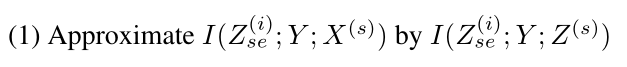
首先,一个充分条件:即 X 的表示特征 Z 至少可以像使用原始数据 X 一样可以描述 Y。其定义如下:
定义 1 (充分性)。当且仅当下列条件时,X 的表示 Z 对 Y 是充分的:

对于Z (s),如果分类损失 L sid 被最小化,
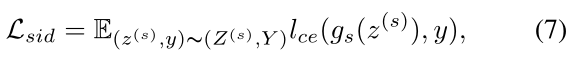
那么可以假设 X (s) 的表示 Z (s) 对 Y 是充分的,就可以近似替代了。
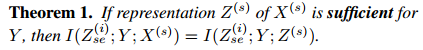
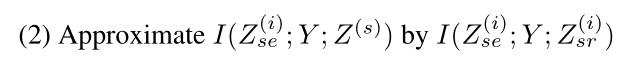
其次,我们希望与形状相关的特征 Z (i) sr 能够完全代表真实的体型特征 Z(s):
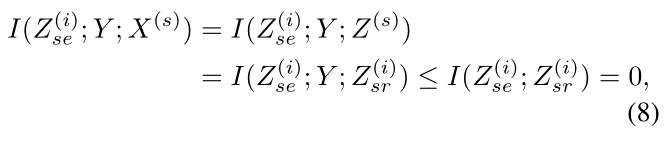
为了 Z (i) sr 能够完全表示 Z (s),由于它们之间存在一对一的映射,我们最大化 I ( Z (i) sr; Z (s)) 通过最小化元素均方误差 (MSE) 来引导 Z (i) sr 模仿 Z (s) 。
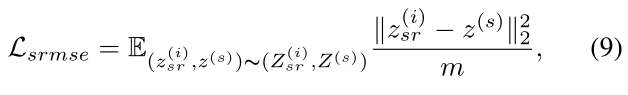
式中 ∥·∥2 为 l 2 范数。
此外,为了减少 X(i) 的 Z (i) sr 与 X(s) 的 Z(s) 之间的差异,需要用到以下公式。
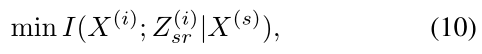
表示给定X(s)视图下Z(i)sr中的剩余信息。
3.3、Overall Framework( )
经过上述的操作,有了以下变化:以前的表示 z (i) 被分解为了两个正交分量,分别是形状相关的Z (i) sr 和形状擦除的and Z (i) se。为了进一步增强Z (i) 的判别性和共享性,对 z (i) 应用了分类损失 Lid 和三元组损失 Ltriplet 。对于三重态对,作者在一个由可见光和红外样品组成的小批量样品中,找到了最难表示的正对和负对。
与 Lsekl 类似,应用以下等式,用相互的方式消除跨模态差异:
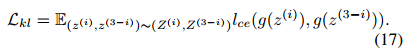
结合上述所有的损失,可得到:
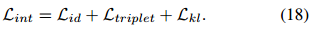
实验结果



总结
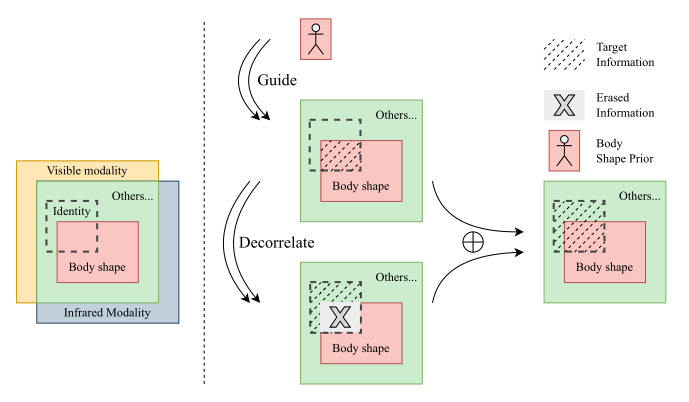
假设体型信息和身份相关的模态共享信息(虚线框表示)部分重叠。为了使提取的特征更加多样化,我们提出了形状擦除特征学习范式,将表征分解为形状相关特征和形状擦除特征。
学习形状擦除特征驱动模型发现除身体形状之外更丰富的模态共享语义概念。
















 9977
9977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











