








TensorRT-LLM是NVIDIA推出的一个开源库,用于定义、优化和执行大型语言模型(LLM)在生产环境的推理。
该库是基于 TensorRT 深度学习编译框架来构建、编译并执行计算图,并借鉴了许多 FastTransformer 中高效的 Kernels 实现,然后利用 NCCL 完成设备之间的通讯。
考虑到技术的发展和需求的差异,开发者还可以定制算子来满足定制需求,比如基于 cutlass 开发定制 GEMM。TensorRT-LLM 是一款致力于提供高性能并不断完善其实用性的 NVIDIA 官方推理方案。
开源社区
TensorRT-LLM已经在GitHub上开源,分为Release branch和Dev branch,其中Release branch每月更新一次,而Dev branch则更频繁地更新来自官方或社区中的功能,方便开发者体验、评估最新功能。
开源地址:https://github.com/NVIDIA/TensorRT-LLM
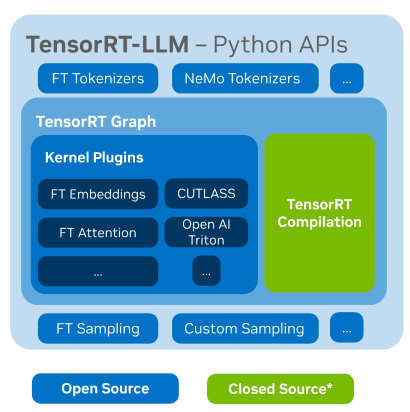
主要功能
Attention
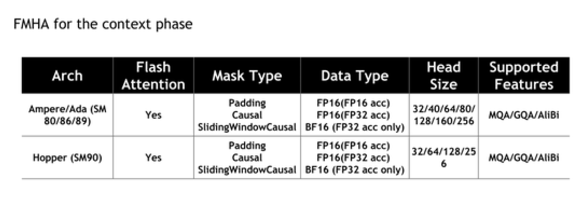
FMHA(Fused multi-head attention)
由于 Transformer 中最为耗时的部分是 self-attention 的计算,因此官方设计了 FMHA 来优化 self-attention 的计算,并提供了累加器分别为 fp16 和 fp32 不同的版本。
另外,除了速度上的提升外,对内存的占用也大大降低。还提供了基于 flash attention 的实现,可以将 sequence-length 扩展到任意长度。
FMHA 的详细信息,其中 MQA 为 Multi Query Attention,GQA 为 Group Query Attention。
MMHA(Masked Multi-Head Attention)
FMHA 主要用在 context phase 阶段的计算,而 MMHA 主要提供 generation phase 阶段 attention 的加速,并提供了 Volta 和之后架构的支持。相比 FastTransformer 的实现,TensorRT-LLM 有进一步优化,性能提升高达 2x。
量化技术
默认采用 FP16/BF16 的精度推理,可以更低精度的方式实现推理加速。
常用量化方式主要分为 PTQ(Post Training Quantization)和 QAT(Quantization-aware Training),对于 TensorRT-LLM 而言,这两种量化方式的推理逻辑是相同的。对于 LLM 量化技术,一个重要的特点是算法设计和工程实现的 co-design,即对应量化方法设计之初,就要考虑硬件的特性。否则,有可能达不到预期的推理速度提升。
TensorRT 中 PTQ 量化步骤一般分为如下几步,首先对模型做量化,然后对权重和模型转化成 TensorRT-LLM 的表示。对于一些定制化的操作,还需要用户自己编写 kernels。
常用的 PTQ 量化方法包括 INT8 weight-only、SmoothQuant、GPTQ 和 AWQ,这些方法都是典型的 co-design 的方法。
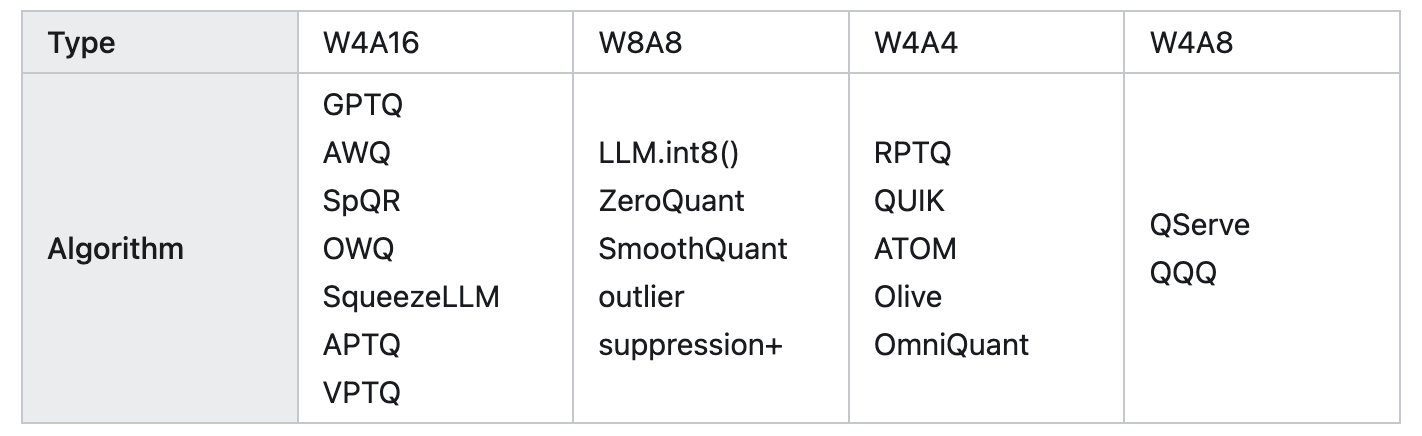
第一个量化方法是INT8 weight-only 直接把权重量化到 INT8,但是激活值还是保持为 FP16。该方法的好处就是模型存储2x减小,加载 weights 的存储带宽减半,达到了提升推理性能的目的。这种方式业界称作 W8A16,即权重为 INT8,激活值为 FP16/BF16——以 INT8 精度存储,以 FP16/BF16 格式计算。该方法直观,不改变 weights,容易实现,具有较好的泛化性能。
第二个量化方法是 SmoothQuant,该方法是 NVIDIA 和社区联合设计的。它观察到权重通常服从高斯分布,容易量化,但是激活值存在离群点,量化比特位利用不高。SmoothQuant 通过先对激活值做平滑操作即除以一个scale将对应分布进行压缩,同时为了保证等价性,需要对权重乘以相同的 scale。之后,权重和激活都可以量化。对应的存储和计算精度都可以是 INT8 或者 FP8,可以利用 INT8 或者 FP8 的 TensorCore 进行计算。在实现细节上,权重支持 Per-tensor 和 Per-channel 的量化,激活值支持 Per-tensor 和 Per-token 的量化。
第三个量化方法是 GPTQ,一种逐层量化的方法,通过最小化重构损失来实现。GPTQ 属于 weight-only 的方式,计算采用 FP16 的数据格式。该方法用在量化大模型时,由于量化本身开销就比较大,所以作者设计了一些 trick 来降低量化本身的开销,比如 Lazy batch-updates 和以相同顺序量化所有行的权重。GPTQ 还可以与其他方法结合使用如 grouping 策略。并且,针对不同的情况,TensorRT-LLM 提供了不同的实现优化性能。具体地,对 batch size 较小的情况,用 cuda core 实现;相对地,batch size 较大时,采用 tensor core 实现。
第四个量化方式是 AWQ。该方法认为不是所有权重都是同等重要的,其中只有 0.1%-1% 的权重(salient weights)对模型精度贡献更大,并且这些权重取决于激活值分布而不是权重分布。该方法的量化过程类似于 SmoothQuant,差异主要在于 scale 是基于激活值分布计算得到的。
多卡和多机支持
TensorRT-LLM 目前提供了 Tensor Parallelism 和 Pipeline Parallelism 两种并行机制,支持单机单卡、单机多卡、多机多卡的推理需求。在一些场景中,大模型过大无法放在单个 GPU 上推理,或者可以放下但是影响了计算效率,都需要多卡或者多机进行推理,以提升性能。
TP 是垂直地分割模型然后将各个部分置于不同的设备上,这样会引入设备之间频繁的数据通讯,一般用于设备之间有高度互联的场景,如 NVLINK。另一种分割方式是横向切分,此时只有一个横前面,对应通信方式是点对点的通信,适合于设备通信带宽较弱的场景。
In-flight batching
Batching 是提高推理性能一个比较常用的做法,但在 LLM 推理场景中,一个 batch 中每个 sample/request 的输出长度是无法预测的。如果按照静态batching的方法,一个batch的时延取决于 sample/request 中输出最长的那个。因此,虽然输出较短的 sample/request 已经结束,但是并未释放计算资源,其时延与输出最长的那个 sample/request 时延相同。
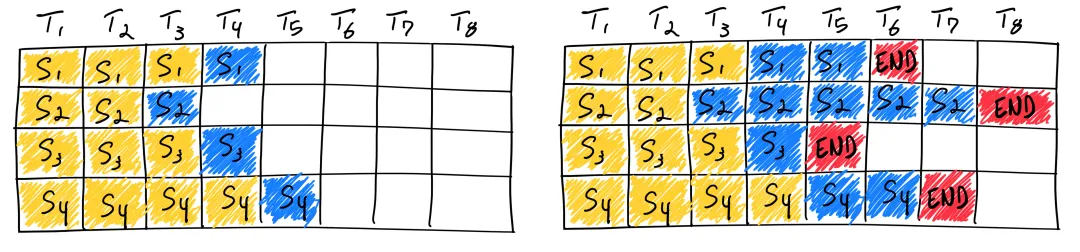
In-Flight Batching 又名 Continuous Batching 或 iteration-level batching,该技术可以提升推理吞吐率,降低推理时延。In-flight batching 的做法是在已经结束的 sample/request 处插入新的 sample/request。这样,不但减少了单个 sample/request 的延时,避免了资源浪费问题,同时也提升了整个系统的吞吐。
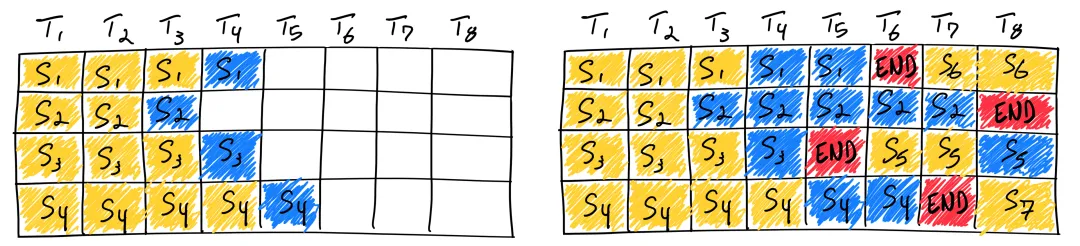
易用
TensorRT-LLM提供了类似于PyTorch的API,降低了开发者的学习成本。同时,该库支持多种编程语言接口,包括Python和C++,方便开发者根据需求选择合适的开发环境。此外,TensorRT-LLM还提供了许多预定义好的模型,方便用户直接使用。


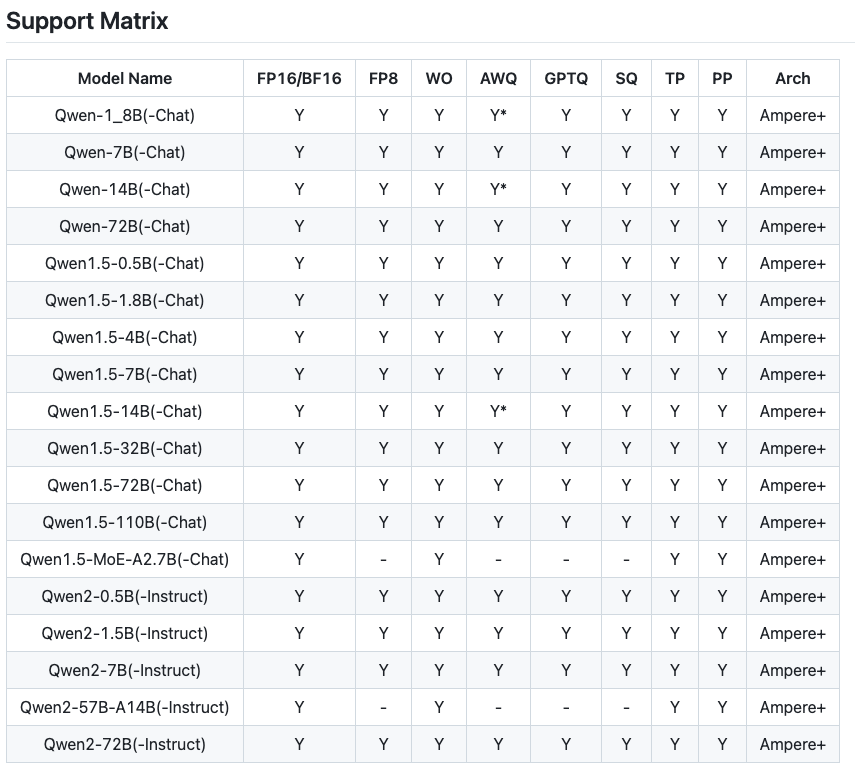
性能
TensorRT-LLM在性能上表现出色,与Hugging Face Transformers(HF)相比,性能提升约2~3倍。此外,TensorRT-LLM通过支持多种量化精度和高效的缓存机制,可以进一步提升了推理效率。此次引用其他模型的评测效果对比:
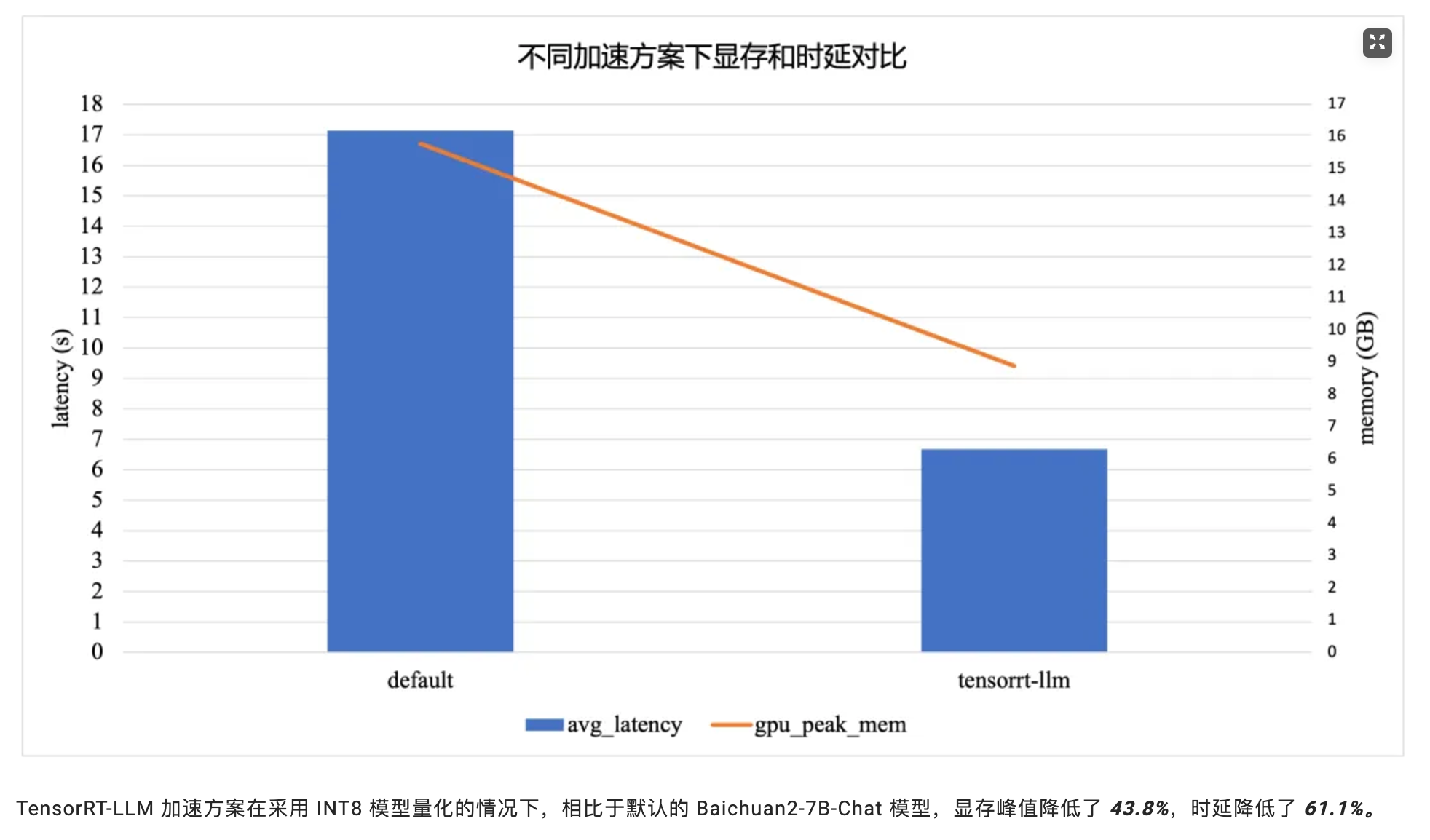
推理快速实践

- 安装 NVIDIA Container Toolkit
- 下载合适的镜像,选择对应的cuda版本,操作系统建议下载ubuntu22.04系统的版本对应Python3.10版本
# 可以使用Docker Proxy镜像加速:https://dockerproxy.net
docker pull nvidia/cuda:12.4.0-devel-ubuntu22.04 - 启动容器
# Obtain and start the basic docker image environment (optional).
docker run --rm --ipc=host --runtime=nvidia --gpus all --entrypoint /bin/bash -it nvidia/cuda:12.4.0-devel-ubuntu22.04- 安装TensorRT-LLM,进入容器
# Install dependencies, TensorRT-LLM requires Python 3.10
apt-get update && apt-get -y install python3.10 python3-pip openmpi-bin libopenmpi-dev git git-lfs
# Install the latest preview version (corresponding to the main branch) of TensorRT-LLM.
# If you want to install the stable version (corresponding to the release branch), please
# remove the `--pre` option.
pip3 install tensorrt_llm -U --pre --extra-index-url https://pypi.nvidia.com
# Check installation
python3 -c "import tensorrt_llm"- 下载代码(可以使用gitcode加速),验证chatglm-6b模型推理
# 可以使用gitcode加速
# git clone https://gitcode.com/gh_mirrors/te/TensorRT-LLM.git
git clone https://github.com/NVIDIA/TensorRT-LLM.git
cd TensorRT-LLM
pip install -r examples/chatglm/requirements.txt
git lfs install- 下载模型,选择modelscope进行下载
CHATGLM_PATH="/root/TensorRT-LLM/examples/chatglm"
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git $CHATGLM_PATH/chatglm3-6b
- 模型格式转换
# Convert checkpoint from HF to TRT-LLM format
python3 $CHATGLM_PATH/convert_checkpoint.py \
--model_dir $CHATGLM_PATH/chatglm3-6b \
--dtype float16 \
--output_dir $CHATGLM_PATH/chatglm3-6b/trt_ckpt/fp16/1-gpu/
# Build TensorRT-LLM model from checkpoint
trtllm-build --checkpoint_dir $CHATGLM_PATH/chatglm3-6b/trt_ckpt/fp16/1-gpu/ \
--gemm_plugin float16 \
--output_dir $CHATGLM_PATH/chatglm3-6b//trt_engines/fp16/1-gpu/
- 量化 -【
INT8 weight-only】
# Build the chatglm3-6b using a single GPU and apply INT8 weight-only quantization.
python3 $CHATGLM_PATH/convert_checkpoint.py \
--model_dir $CHATGLM_PATH/chatglm3-6b \
--dtype float16 \
--use_weight_only \
--output_dir $CHATGLM_PATH/chatglm3-6b/trt_ckpt/int8_weight_only/1-gpu/
trtllm-build --checkpoint_dir $CHATGLM_PATH/chatglm3-6b/trt_ckpt/int8_weight_only/1-gpu/ \
--gemm_plugin float16 \
--output_dir $CHATGLM_PATH/chatglm3-6b/trt_engines/int8_weight_only/1-gpu/
- 运行引擎进行推理,未量化vs量化
python3 /root/TensorRT-LLM/examples/run.py --input_text "世界上第二高的山峰是哪座?" \
--max_output_len 50 \
--tokenizer_dir $CHATGLM_PATH/chatglm3-6b \
--engine_dir $CHATGLM_PATH/chatglm3-6b/trt_engines/fp16/1-gpu/
python3 /root/TensorRT-LLM/examples/run.py --input_text "世界上第二高的山峰是哪座?" \
--max_output_len 50 \
--tokenizer_dir $CHATGLM_PATH/chatglm3-6b \
--engine_dir $CHATGLM_PATH/chatglm3-6b/trt_engines/int8_weight_only/1-gpu/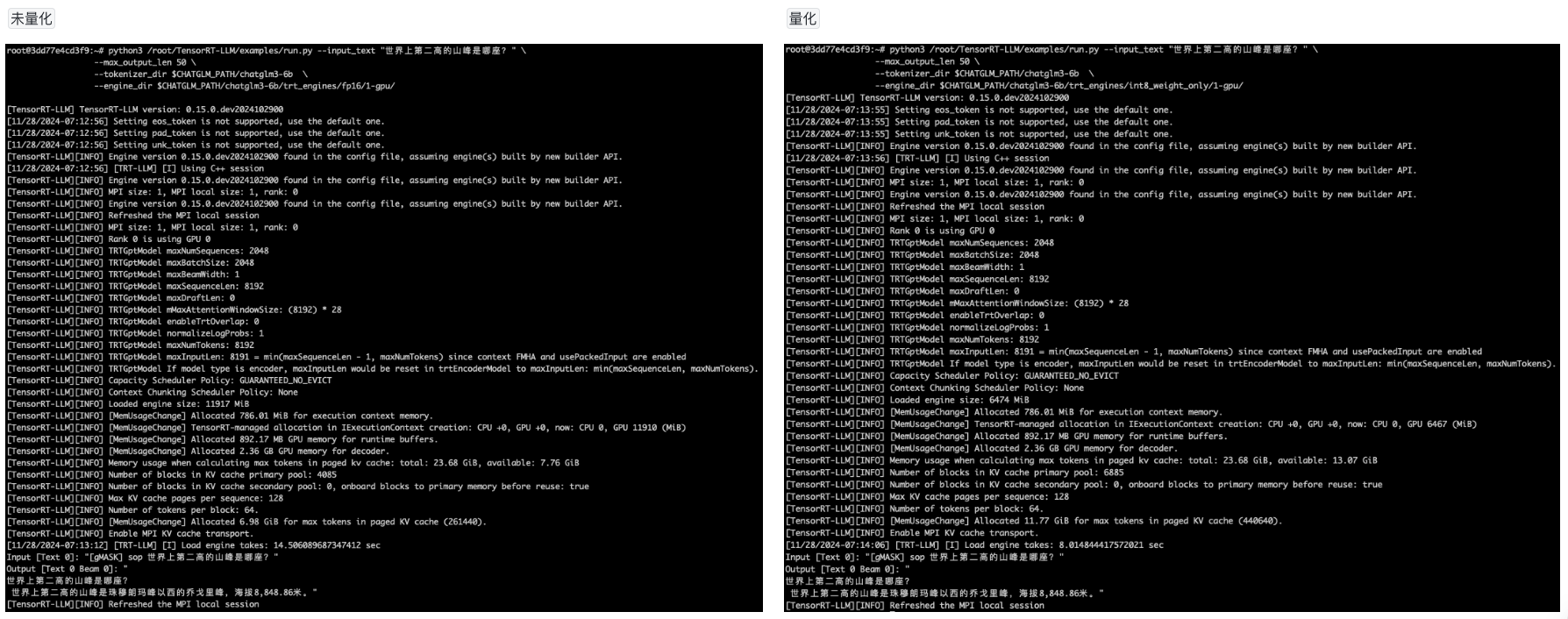



















 2859
2859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









