







一、“Aha Moment” - 顿悟时刻
本文将快速上手实践DeepSeek提出的GRPO算法,并手动复现DeepSeek R1论文中的模型顿悟时刻,即通过GRPO训练,让模型诞生思考链。这也是整个DeepSeek R1模型训练的至关重要的环节,也是DeepSeek R1模型为大模型技术做出的卓越贡献。
不同于传统的强化学习训练算法,或者常用的PPO算法,GRPO算法更加省时高效,通过暴力枚举策略、以及自我策略对比的方法快速提升模型在推理问题上制定策略的能力。这也是目前强化学习领域、被验证的最有效的提升大模型推理能力的方法。
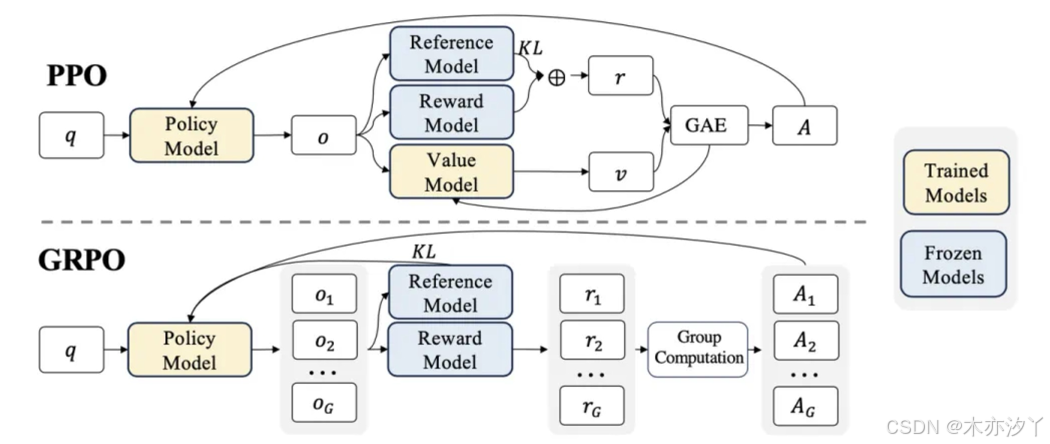
- GRPO算法实现方法,这些主流的强化学习框架均支持GRPO算法,可以一键进行调用:
本次采用最基础的trl库,并围绕Qwen2.5-1.5B-instruct模型的GRPO强化学习训练,并复现DeepSeek R1模型训练过程中的aha时刻,从此诞生思考过程。
- 模型下载
魔搭社区模型权重下载地址:https://modelscope.cn/models/Qwen/Qwen2.5-1.5B-Instruct
pip install modelscopemkdir ./Qwen2.5-1.5B-Instruct
modelscope download --model Qwen/Qwen2.5-1.5B-Instruct --local_dir ./Qwen2.5-1.5B-Instruct- 准备数据集
数据集选自OpenAI/GSM8K数据集:https://huggingface.co/datasets/openai/gsm8k
OpenAI GSM8K 数据集 是一个广泛用于评估推理和数学能力的多样化数学题目数据集。该数据集包含大约 8,000 个数学问题,涵盖了从小学到高中的各种数学领域,包括算术、代数、几何等。GSM8K 旨在挑战大型语言模型在没有显式提示的情况下,解决更复杂的数学推理问题。数据集中的问题通常需要模型进行多步推理,远超基本的算术计算,因此它被广泛用于测试模型在理解和处理数字推理的能力。
GSM8K 数据集的设计基于自然语言形式,呈现为问题-解答对的形式,且包含了问题的详细解析步骤。该数据集被广泛应用于模型的 零样本推理 和 少样本学习 任务,是当前研究中用于验证语言模型推理能力的重要基准之一。
二、训练前调用
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "./models/Qwen2.5-1.5B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "John buys 2 packs of gum and 3 candy bars. Each stick of gum cost half as much as the candy bar. If the candy bar cost $1.5 each, how much did he pay in total?"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)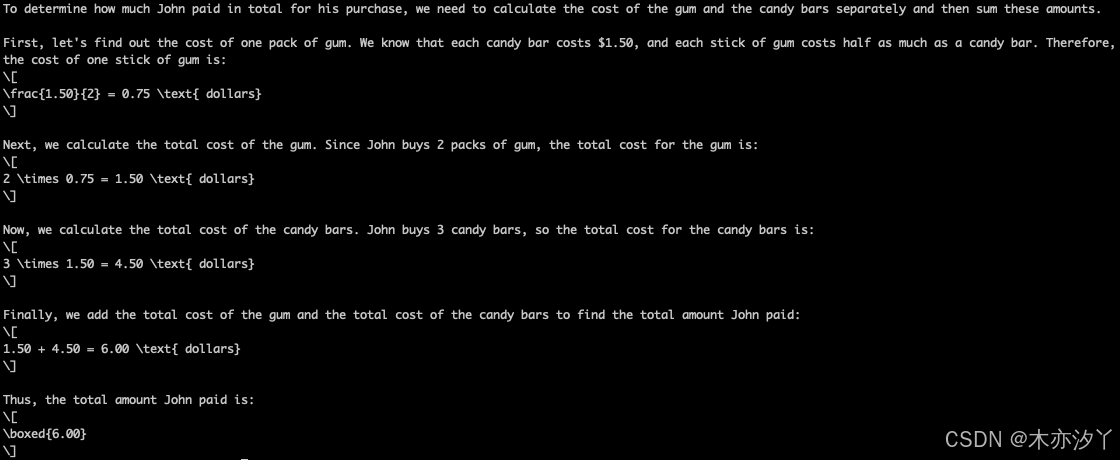
三、GRPO复现aha时刻
完整代码
import re
import torch
from datasets import load_dataset, Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM
from trl import GRPOConfig, GRPOTrainer
SYSTEM_PROMPT = """
Respond in the following format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
"""
XML_COT_FORMAT = """\
<reasoning>
{reasoning}
</reasoning>
<answer>
{answer}
</answer>
"""
def extract_xml_answer(text: str) -> str:
answer = text.split("<answer>")[-1]
answer = answer.split("</answer>")[0]
return answer.strip()
def extract_hash_answer(text: str) -> str | None:
if "####" not in text:
return None
return text.split("####")[1].strip()
# uncomment middle messages for 1-shot prompting
def get_gsm8k_questions(split = "train") -> Dataset:
data = load_dataset('openai/gsm8k', 'main')[split] # type: ignore
data = data.map(lambda x: { # type: ignore
'prompt': [
{'role': 'system', 'content': SYSTEM_PROMPT},
{'role': 'user', 'content': x['question']}
],
'answer': extract_hash_answer(x['answer'])
}) # type: ignore
return data # type: ignore
# Reward functions
def correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions]
q = prompts[0][-1]['content']
extracted_responses = [extract_xml_answer(r) for r in responses]
print('-'*20, f"Question:\n{q}", f"\nAnswer:\n{answer[0]}", f"\nResponse:\n{responses[0]}", f"\nExtracted:\n{extracted_responses[0]}")
return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)]
def int_reward_func(completions, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions]
extracted_responses = [extract_xml_answer(r) for r in responses]
return [0.5 if r.isdigit() else 0.0 for r in extracted_responses]
def strict_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"^<reasoning>\n.*?\n</reasoning>\n<answer>\n.*?\n</answer>\n$"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
def soft_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"<reasoning>.*?</reasoning>\s*<answer>.*?</answer>"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
def count_xml(text) -> float:
count = 0.0
if text.count("<reasoning>\n") == 1:
count += 0.125
if text.count("\n</reasoning>\n") == 1:
count += 0.125
if text.count("\n<answer>\n") == 1:
count += 0.125
count -= len(text.split("\n</answer>\n")[-1])*0.001
if text.count("\n</answer>") == 1:
count += 0.125
count -= (len(text.split("\n</answer>")[-1]) - 1)*0.001
return count
def xmlcount_reward_func(completions, **kwargs) -> list[float]:
contents = [completion[0]["content"] for completion in completions]
return [count_xml(c) for c in contents]
model_name = "models/Qwen2.5-1.5B-Instruct"
output_dir="models/Qwen2.5-1.5B-GRPO"
run_name="Qwen2.5-1.5B-GRPO-gsm8k"
training_args = GRPOConfig(
output_dir=output_dir,
run_name=run_name,
learning_rate=5e-6,
adam_beta1 = 0.9,
adam_beta2 = 0.99,
weight_decay = 0.1,
warmup_ratio = 0.1,
lr_scheduler_type='cosine',
logging_steps=1,
bf16=True,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
num_generations=4,
max_prompt_length=256,
max_completion_length=200,
num_train_epochs=1,
save_steps=100,
max_grad_norm=0.1,
log_on_each_node=False,
use_vllm=False,
vllm_gpu_memory_utilization=.3,
vllm_device="cuda",
report_to="none"
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map=None
).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
dataset = get_gsm8k_questions()
trainer = GRPOTrainer(
model=model,
processing_class=tokenizer,
reward_funcs=[
xmlcount_reward_func,
soft_format_reward_func,
strict_format_reward_func,
int_reward_func,
correctness_reward_func],
args=training_args,
train_dataset=dataset,
)
trainer.train()
trainer.save_model(output_dir)nohup env HF_ENDPOINT=https://hf-mirror.com python rl_grpo.py > ./grpo.log 2>&1 &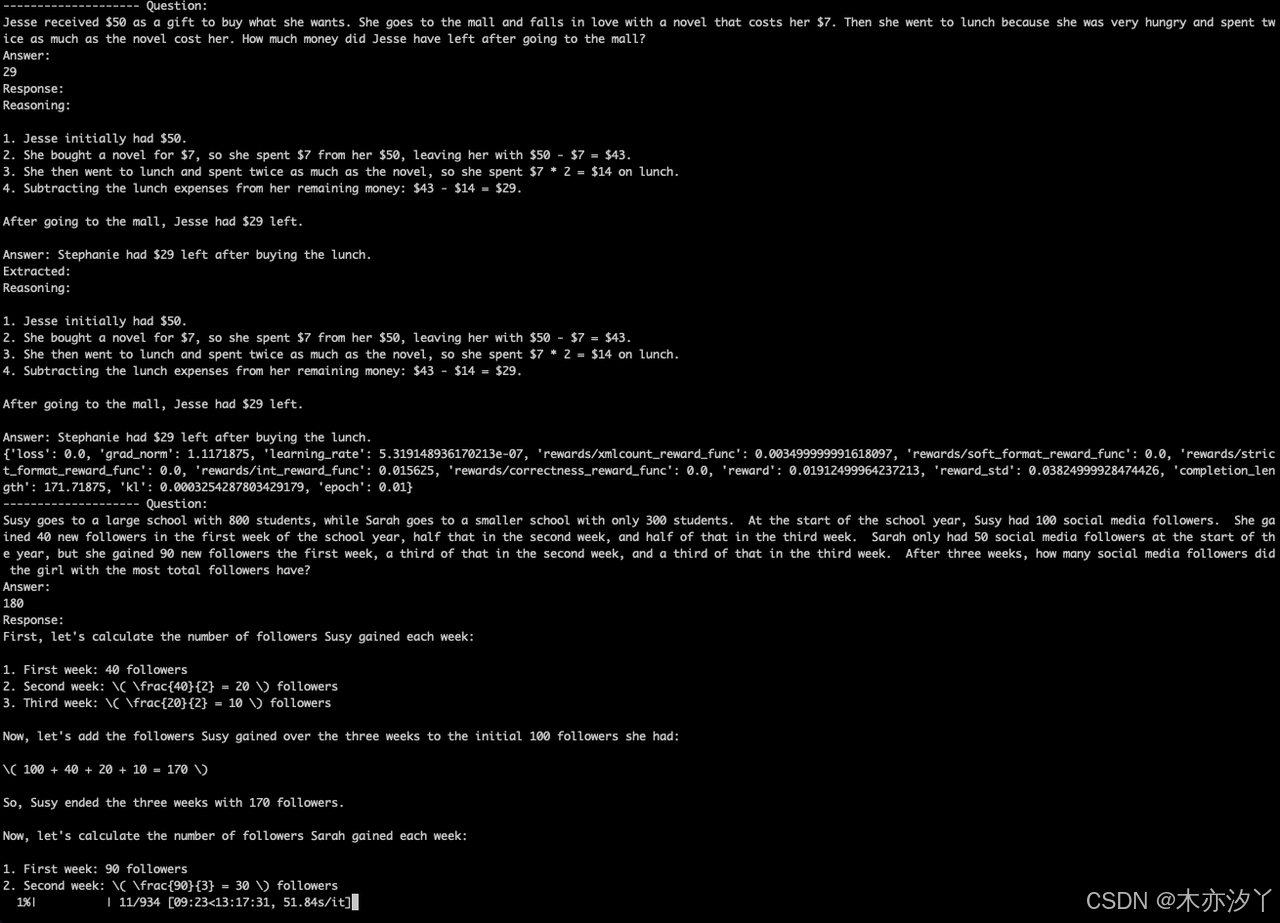
我们在两卡3090上,GRPO训练过程需要约40G显存,并运行13个小时左右。
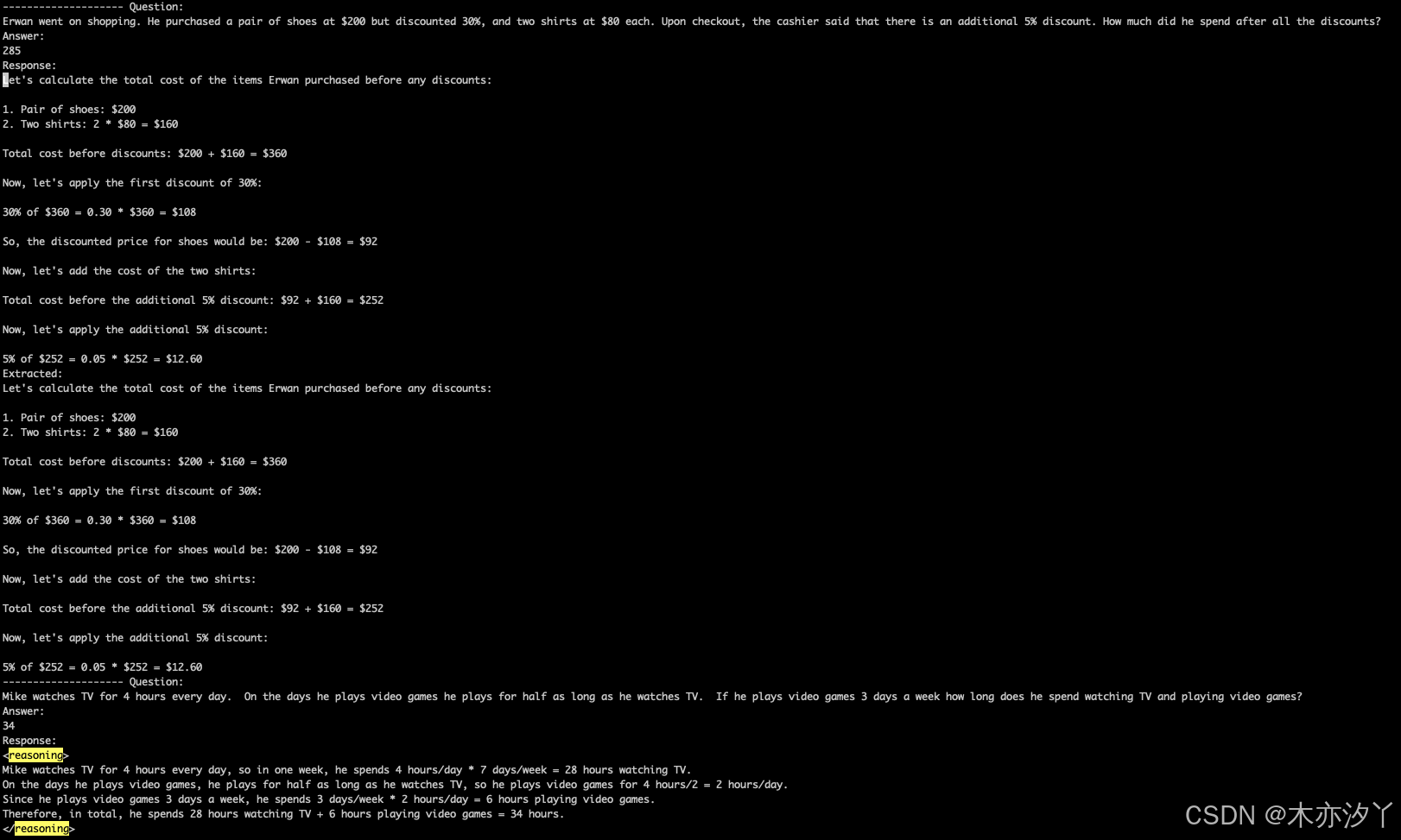
从训练日志中我们发现,前一个问题还没有思考过程,后一个问题诞生了思考过程。
代码解析
定义提示词模板
SYSTEM_PROMPT = """..."""这是一个多行字符串,定义了一个系统提示prompt的格式。"<reasoning>"和"</reasoning>":这部分表示推理过程的地方。推理过程可能包括模型分析问题、提出假设、推理等逻辑推导步骤。"<answer>"和"</answer>":这部分表示最终的回答或结论的地方。根据推理结果,模型将给出答案。
模型文本输出格式模板
XML_COT_FORMAT = """..."""这个字符串定义了一个 XML 风格的格式,并允许动态插入reasoning和answer的内容。"<reasoning>{reasoning}</reasoning>":这里{reasoning}是一个占位符,表示实际的推理过程会被插入到该位置。"<answer>{answer}</answer>":类似地,{answer}是占位符,用于插入最终答案。
数据格式处理函数组
extract_xml_answer用于从 XML 风格的文本中提取<answer>标签之间的内容。extract_hash_answer用于从文本中提取####后的内容,若没有找到####,返回None。get_gsm8k_questions加载GSM8K数据集,并将问题与系统提示结合,格式化后返回。
奖励函数组
correctness_reward_func:根据正确性对答案进行奖励。int_reward_func:根据是否为数字对输出进行奖励。strict_format_reward_func:根据严格的格式要求检查并奖励。soft_format_reward_func:根据稍微宽松的格式要求检查并奖励。count_xml:计算文本中的 XML 标签结构并给予奖励。xmlcount_reward_func:为每个输出计算 XML 标签结构的符合度并返回奖励。
四、训练后调用
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "./models/Qwen2.5-1.5B-GRPO"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "John buys 2 packs of gum and 3 candy bars. Each stick of gum cost half as much as the candy bar. If the candy bar cost $1.5 each, how much did he pay in total?"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)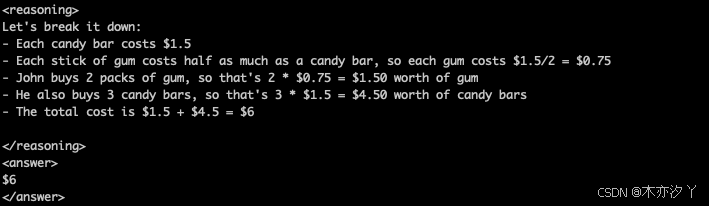



















 883
883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









