







今日号外:🔥🔥🔥 DeepSeek团队正式启动为期五天的开源计划 Day2:DeepEP,首个开源的MoE模型训练与推理专用EP通信库。一个专为 Mixture-of-Experts (MoE) 和专家并行(EP)设计的高效通信库,主要用于加速大规模分布式训练和推理任务。
代码仓库:https://github.com/deepseek-ai/DeepEP
✅ 高度优化的All-to-All通信
✅ 支持NVLink和RDMA的节点内/节点间通信
✅ 针对训练及推理预填充阶段,提供高吞吐量 Kernels
✅ 针对推理解码阶段,提供低延迟 Kernels
✅ 原生支持 FP8 数据分发
✅ 灵活控制GPU资源,以实现计算与通信的高效重叠

正题:原生稀疏注意力(NSA)

🔥🔥🔥 长上下文建模对于下一代语言模型至关重要,然而标准注意力机制的高计算成本带来了巨大的计算挑战。稀疏注意力为在保持模型能力的同时提高效率提供了一个有前景的方向。DeepSeek团队发布的最新研究成果——原生稀疏注意力(NSA)给出了答案。DeepSeek NSA 采用动态分层稀疏策略,将粗粒度的标记压缩与细粒度的标记选择相结合,以兼顾全局上下文感知和局部精度。NSA技术能够在不依赖堆算力的情况下,让大模型在处理长上下文、推理以及模型训练时,表现出高效率和高性能。通过在算法层面上做优化,NSA技术在硬件层面友好,并且在训练端原生适配,显著提升了计算效率。实验结果显示,NSA在多项测试中表现优异,特别是在需要推理的任务上,展现了其优越性。
大语言模型基础工作流程
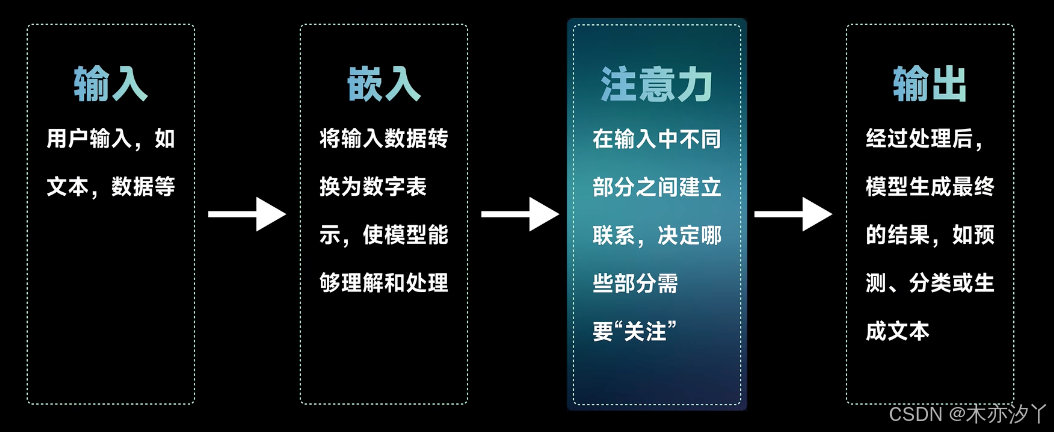
在处理超长文本时,如上传一整本书进行理解分析或进行超长的多路对话时,往往最耗时的是在注意力环节,包括注意力的计算量和显存的消耗,传统的做法是全注意力机制(Full Attention Mechanism)。全注意力机制通过计算输入中所有元素之间的关系,并据此调整每个元素的重要性,从而捕捉全局上下文信息。

查询向量和键向量计算注意力矩阵
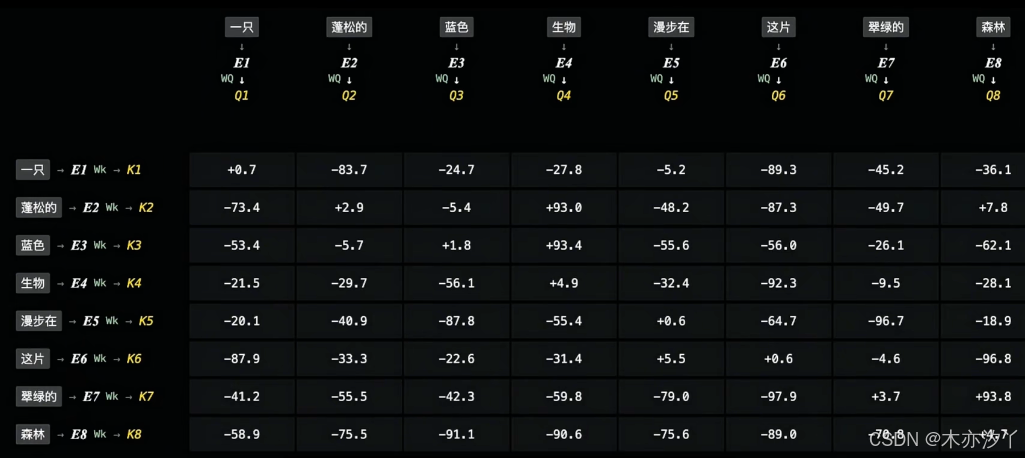
当文档长度增加至上万字乃至更多时,全注意力机制需要把矩阵内所有的单元都乘一遍,意味着算力和显存成本会成倍乃至指数级增长。
稀疏注意力机制的核心研究思路就是划重点,它并不是把所有的单元全部都计算一遍,而是通过某种机制去筛选,只保留重要的信息。然后在不影响下游效果的情况下,显著地缩小计算规模。不过在目前已有的稀疏注意力的研究中存在两个痛点:
- 训练层面痛点:现有稀疏注意力机制研究中仅在推理阶段实现理想中的理论加速,缺乏对训练阶段的支持。
- 硬件层面痛点:在实际部署中,现有稀疏注意力机制缺乏硬件对齐,无法在硬件层面实现等比例的速度提升。
原生稀疏注意力(Native Sparse Attention)
DeepSeek团队此次提出的NSA就给出了一条硬件层面友好,并且在训练端原生适配的稀疏注意力思路。
算法优化
首先DeepSeek团队从算力和内存的瓶颈切入,当在GPU上做注意力计算时,真正卡住脖子的往往是内存的带宽或不连续的数据访问,因此eepSeek团在建模的时候使用了分层设计,通过压缩分支、选择分支、滑动窗口分支,这三个分支来处理上下文。
NSA分层分支设计思路
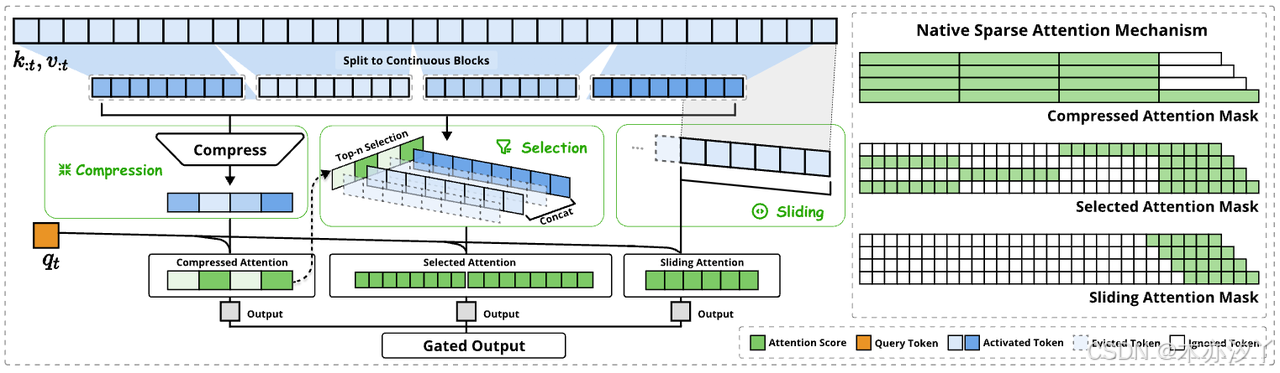

例如:我们让大模型来读一本书的时候,那第一层压缩分支就相当于是看大纲,将书分为多个段落,并提取每个段落的核心信息,帮助模型快速的理解整体的内容。第二层选择分支就像是在挑重点,基于第一层的理解找出最重要的段落,进行深入的分析。那最后第三层滑动窗口分支则是在读细节,通过移动窗口的方式,仔细处理局部文本之间的关联。
硬件对齐优化
为了让NSA发挥它最大的效率,DeepSeek团队对硬件层面也做了一些针对性的优化。考虑到在处理大量的数据的时候,多头注意力机制非常消耗内存且它的解码效率也不是很高,所以DeepSeek团队采用了共享数据的设计方案,包括分组查询注意力和多查询注意力。
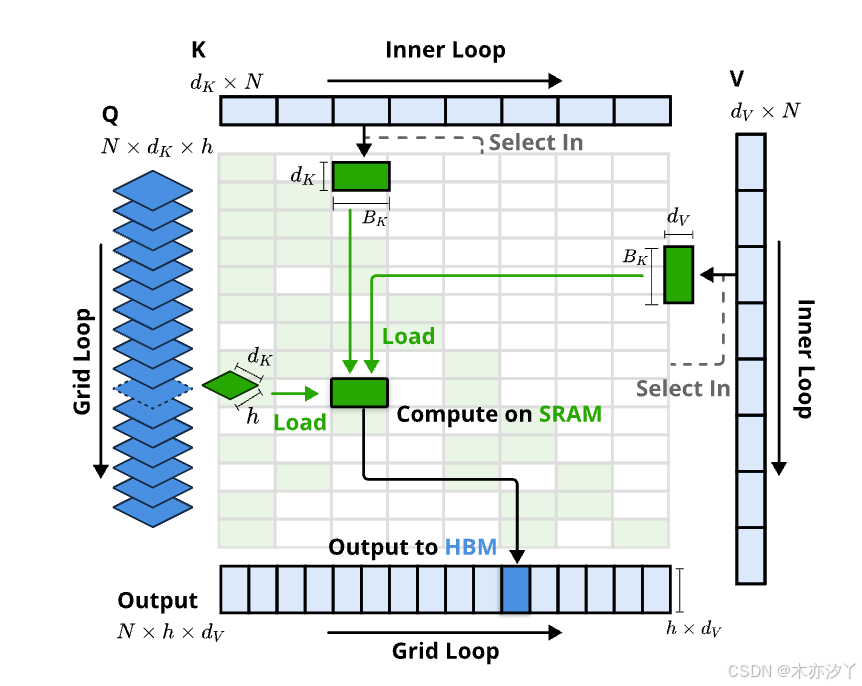
- 基于组的数据加载:一次性加载一个查询位置的所有相关数据,而不是逐个加载。这样可以更有效地处理每个查询,减少重复加载的情况。
- 共享KV获取:将连续的键/值数据批量加载到内存中,避免每次都加载不同的数据块,这样可以减少内存访问的次数,提高效率。
- 外循环网格化:由于每个查询块需要的计算量差不多,将所有查询和输出的操作安排到Triton的调度器中,这样可以更高效地利用硬件资源,减少计算的重复操作。
小结
通过这些优化,NSA不仅保持了原有的性能,还能更充分的利用硬件的资源。另外NSA不是在模型训练完毕后才去削减不必要的计算的,而是在训练阶段就已经开始采取了分块压缩,分块选择和滑动窗口的策略,让模型从一开始就学会如何有效地利用资源。
测试对比
但这样做会不会影响模型的表达能力呢?
- 对比NSA和Full Attn进行不同类型的基准测试,包括知识储备、推理能力和编程技术等三大类,共9项测试内容。表现如下:
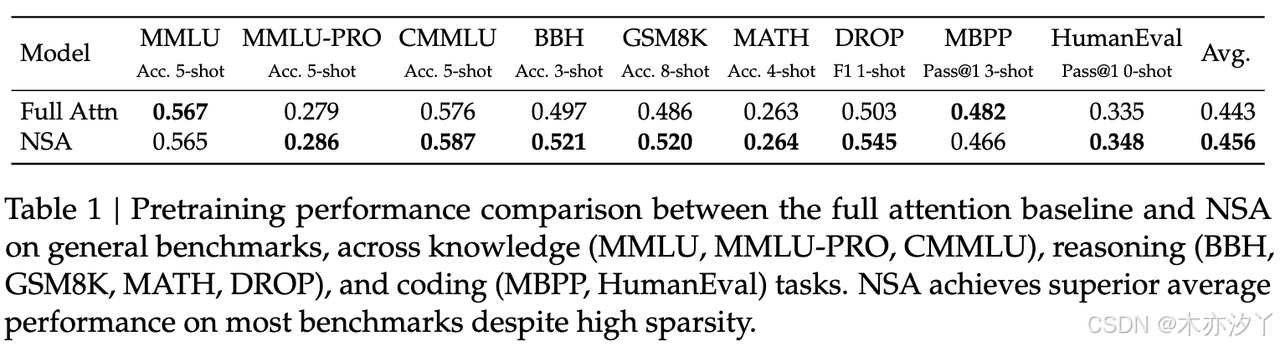
DROP测试:阅读理解基准测试,要求模型从段落中提取相关信息,并进行离散推理,如排序、计数等操作。该测试旨在评估模型处理复杂文本并执行离散推理的能力。
GSM8K测试:该基准测试包含8500道小学数学题目,旨在评估模型的数学推理能力。这些问题通常需要多步推理,测试模型解决数学问题的能力。
这说明了NSA虽然简化了模型的结构,但是并没有影响模型的性能,反而提升了效果。而且通过这样新的训练方式,可以让模型更好地抓住关键的信息,过滤掉无关的干扰。
-
在长文本理解任务方面,LongBench基准测试表现情况。
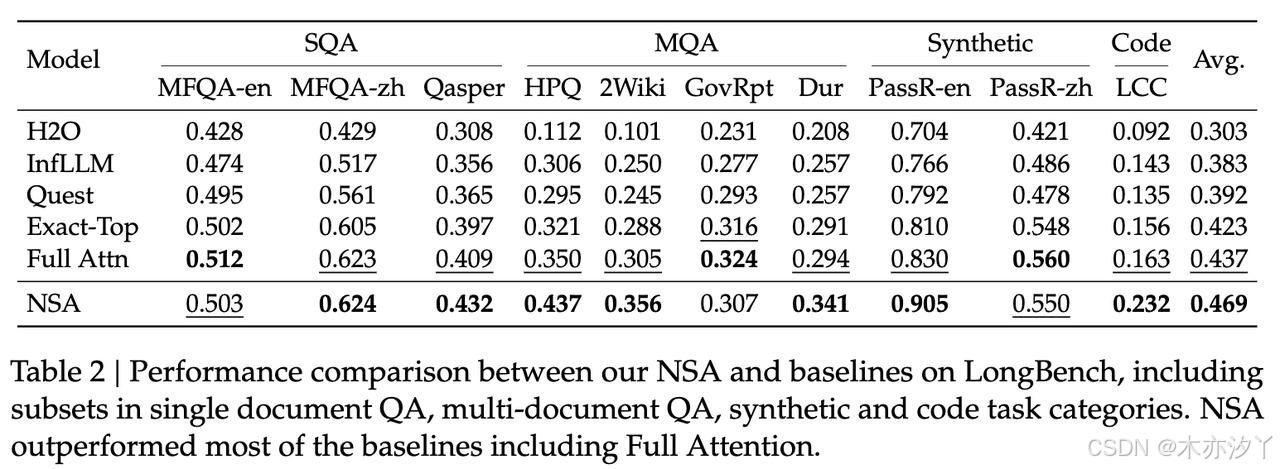
LLC测试:代码理解基准测试,主要用于评估代码理解能力的基准测试。
PassR-en测试:段落检索基准测试,主要评估模型在段落检索任务中的性能。
-
思维链推理能力方面,COT推理测试:
为了评估NSA与下游训练范式的兼容性,DeepSeek团队通过后训练提升其思维链数学推理能力。采用DeepSeek-R1的知识蒸馏,并利用10B tokens和32k长度的推理痕迹进行监督微调,生成了Full Attention-R和NSA-R两个模型。随后,在AIME24基准上评估这两个模型使用0.7的采样温度和0.95的top-p值生成16个答案并计算平均分数,同时测试了8k和16k tokens上下文限制对准确性的影响。

-
训练速度对比
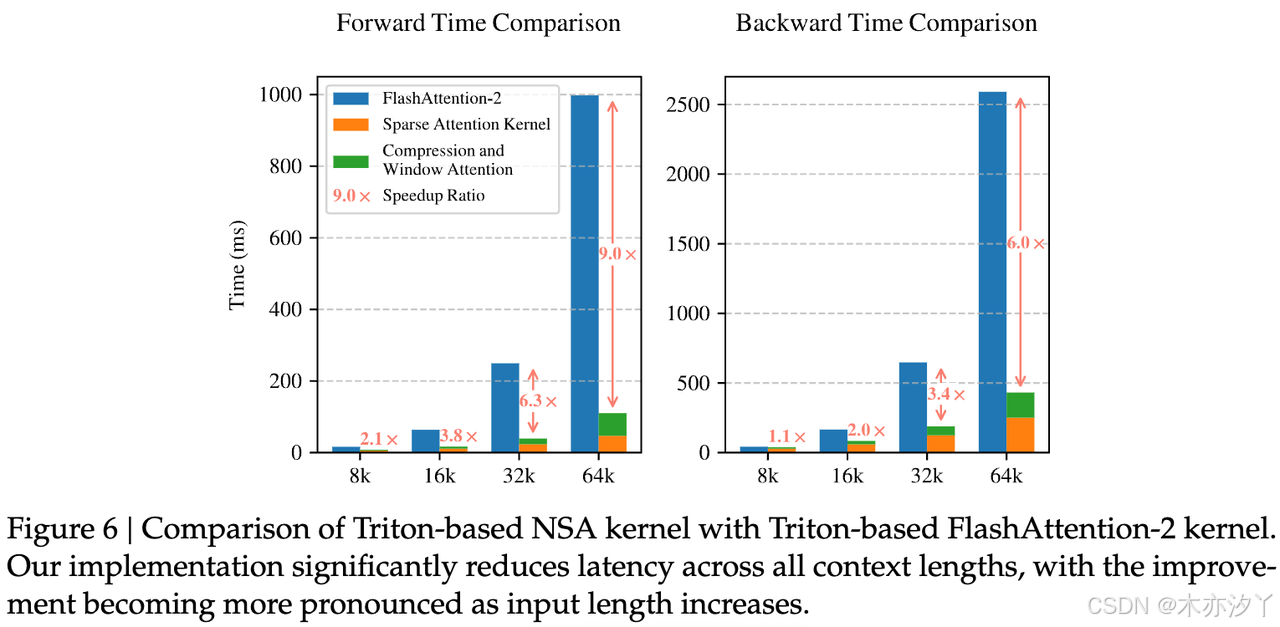
在计算效率方面,DeepSeek团队使用了8块A100的GPU,来测试NSA和Full Attn的计算效率。结果显示,NSA的计算优势会随着处理文本长度的增加,而变得更加的明显,特别是在处理64K上下文字符长度的文本时,NSA在向前计算速度上快了9倍,在反向计算速度上快了6倍。
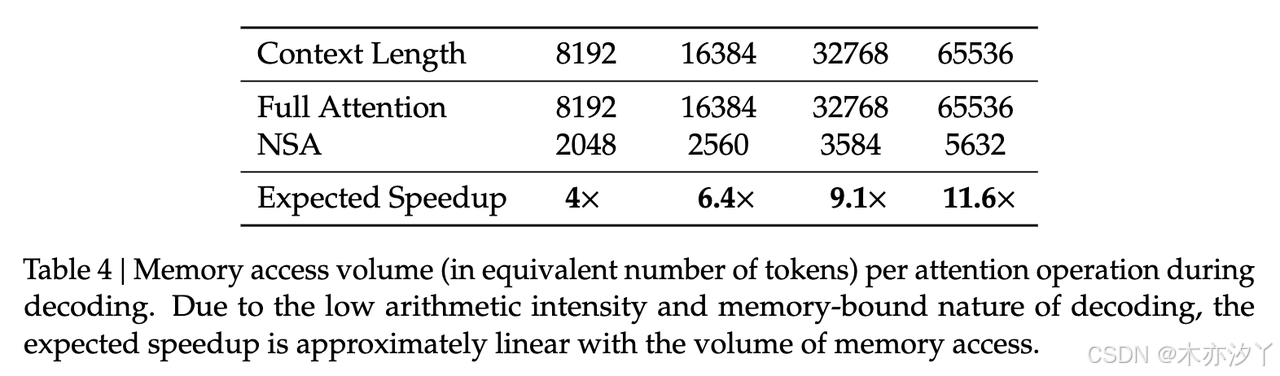
- 解密速度对比
因为NSA分层分支设计思路,加载的信息比Full Attn少。这种设计让NSA在出来长文本的速度优势更加明显。特别是在处理64K上下文长度的文本时,速度提升可以达到11.6倍。



















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









