









目录
1.介绍
BERT:当前主流的解决框架,一站式搞定NLP任务。(解决一个NLP任务时的考虑方法之一)
BERT:google开源的框架
BERT:自然语言的通用解决框架
必备知识:Word2vec,RNN(了解词向量模型,RNN模型如何建模)
重点:Transformer网络架构
训练方法: BERT训练方法
google开源提供预训练模型,直接使用
2.Transformer
2.1 引言
BERT时基于Transformer框架的,所以了解Tansformer就基本了解BERT。
提出问题:transformer要做一件什么事呢??
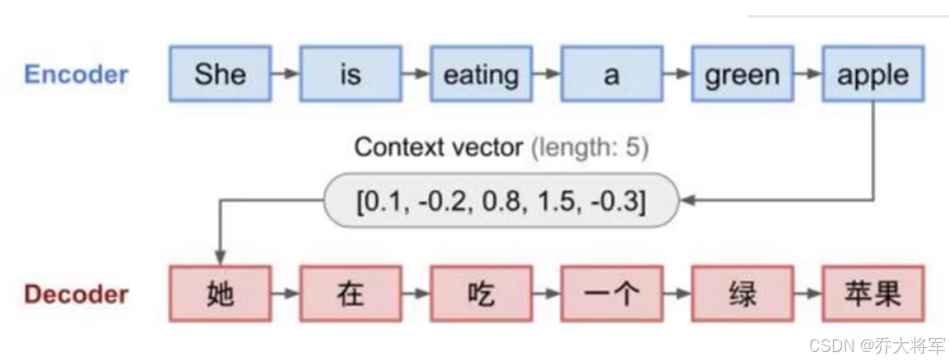
答:就像将自然语言翻译成计算机语言,让其学习。
其基本组成依旧是机器翻译模型中常见的Seq2Seq网络。输入输出都很直观,其核心就是中间的网络架构了。

2.2 传统RNN网络的问题
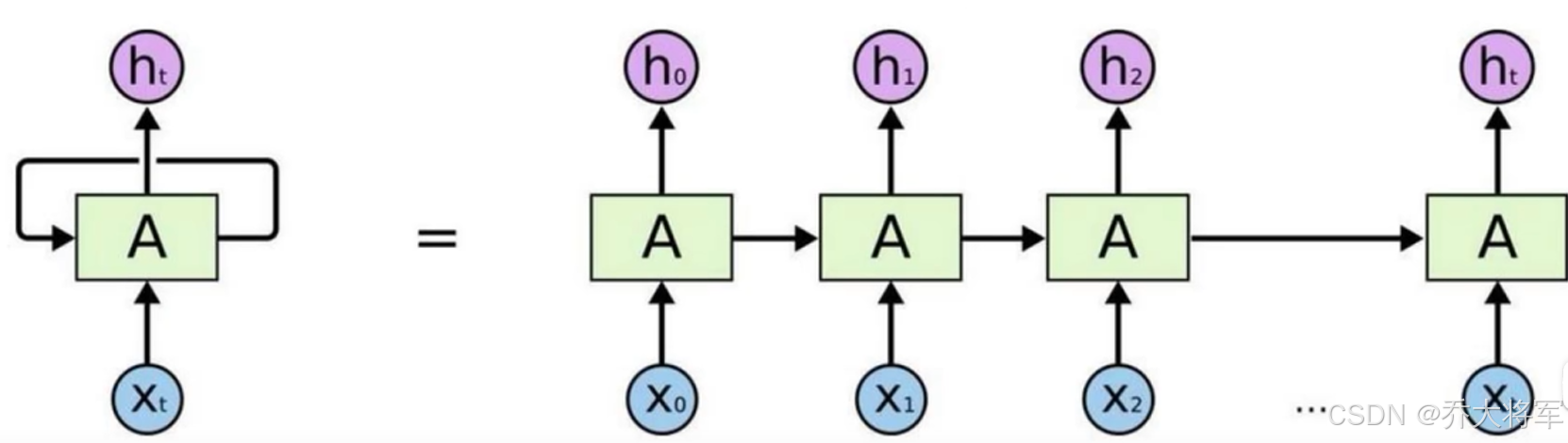
可以看出这种依次计算的方式,计算效率不高,且后面的计算需要依赖前面的计算结果。
预训练好的词向量就不会改变了,这种对于复杂语境应用不好。所以能不能让其并行计算,提高运算效率,且词向量的构成考虑到上下文的语境呢???
答案:self-Attention机制来考虑进行并行计算,输出结果的是同时你算出来的,现在已经基本取代RNN了。
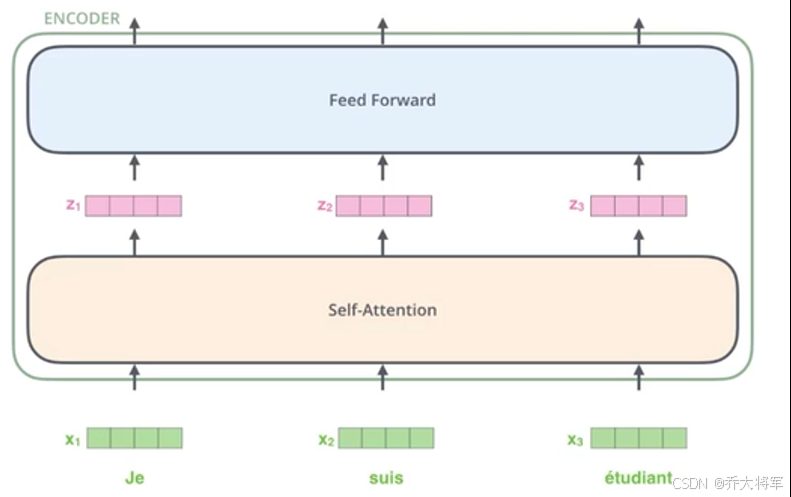
2.3 整体架构
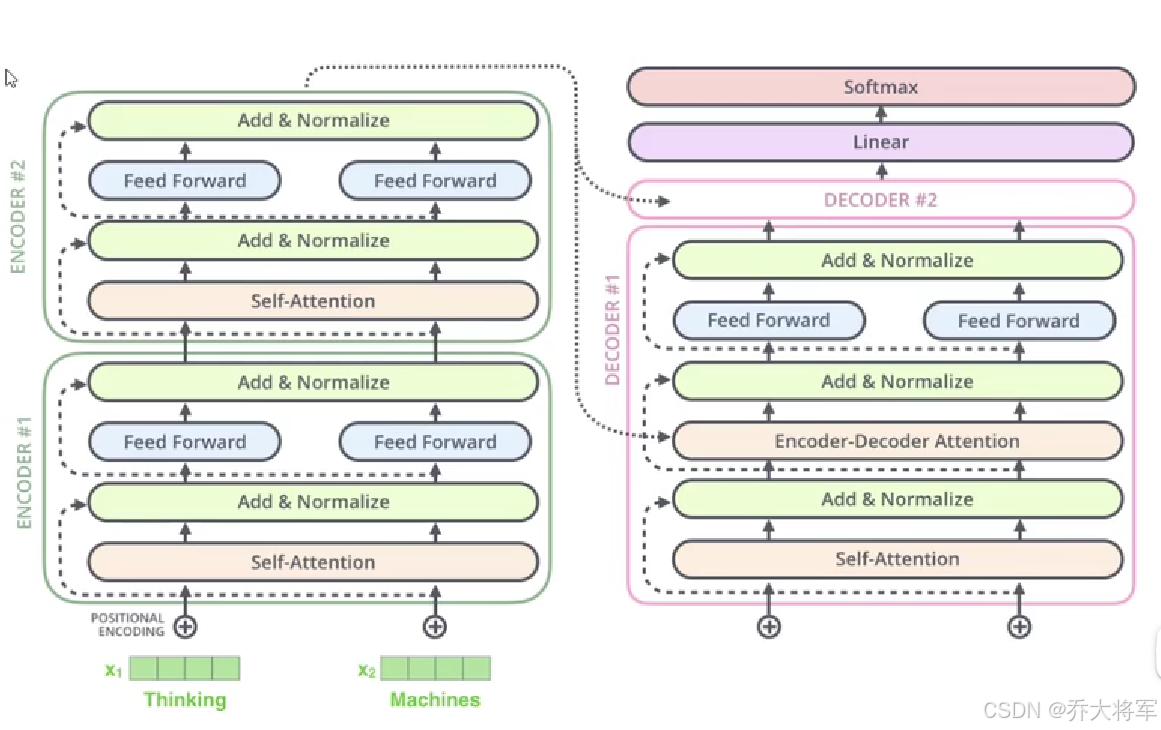
接下来我们将围绕这几个问题来展开对Tansformer的介绍:
1. 输入如何编码?
2.输出结果是什么?
3.Attemtion的目的?
4.怎样组合在一起?
2.4 Attention
对于输入的数据,你的关注点是什么?(不同的数据,关注点不同,比如:一张带背景的人像,关注点是人像而不是背景)

如何才能让计算机关注到这些有价值的信息?
Self-Attention是计算机自己判断。
每个词不能只考虑到自己,在训练的过程中,所有词构成句子,但是每个词分配的权重不同。在编码时,不能只考虑自己,要把上下文都融入,编码成向量。
例如:

it代表的东西不同,怎么让计算机识别出来呢?每个词都要考虑上下文,结合每个词对它的影响来进行编码。

2.5 Self-Attention如何计算
其实,说到底,Self-Attention就是如何编码,提取特征。
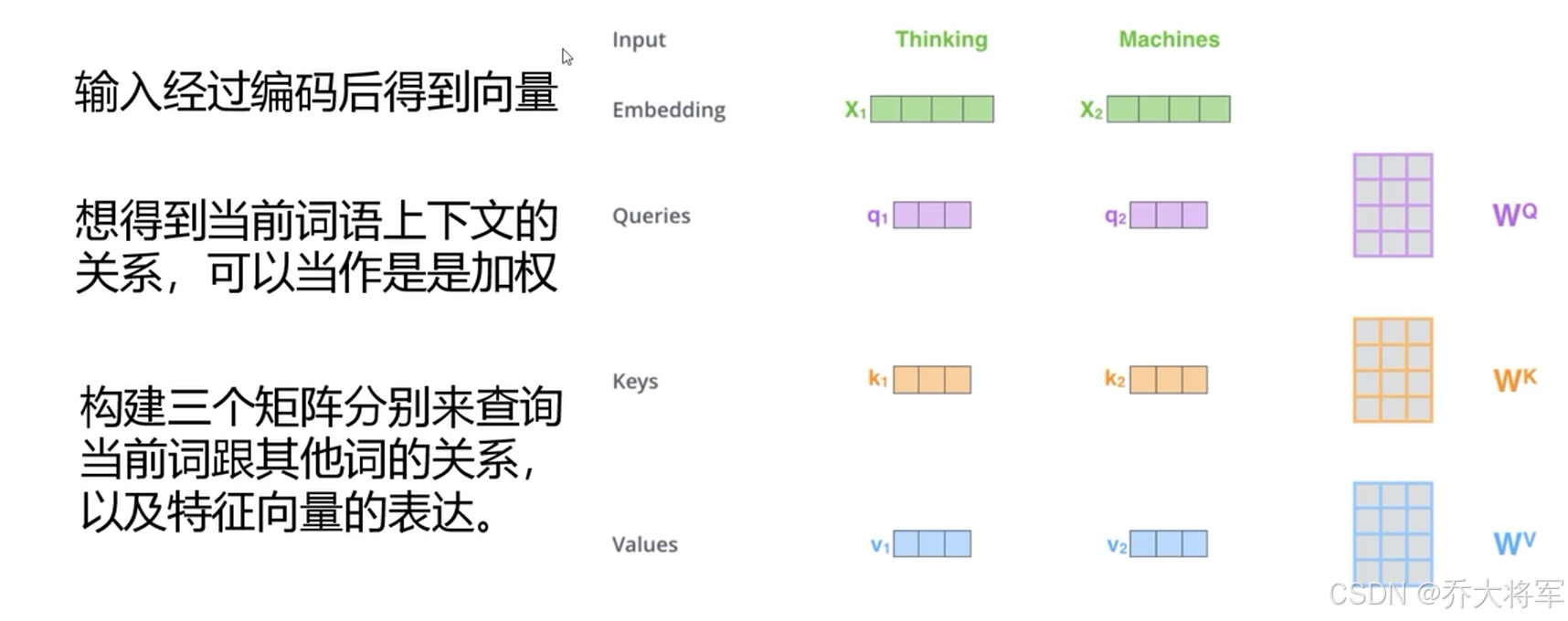
1. 通过Embedding随机或者其他什么方式去初始化词向量表,权重矩阵
2. 训练这三个矩阵

得到,
同理得到
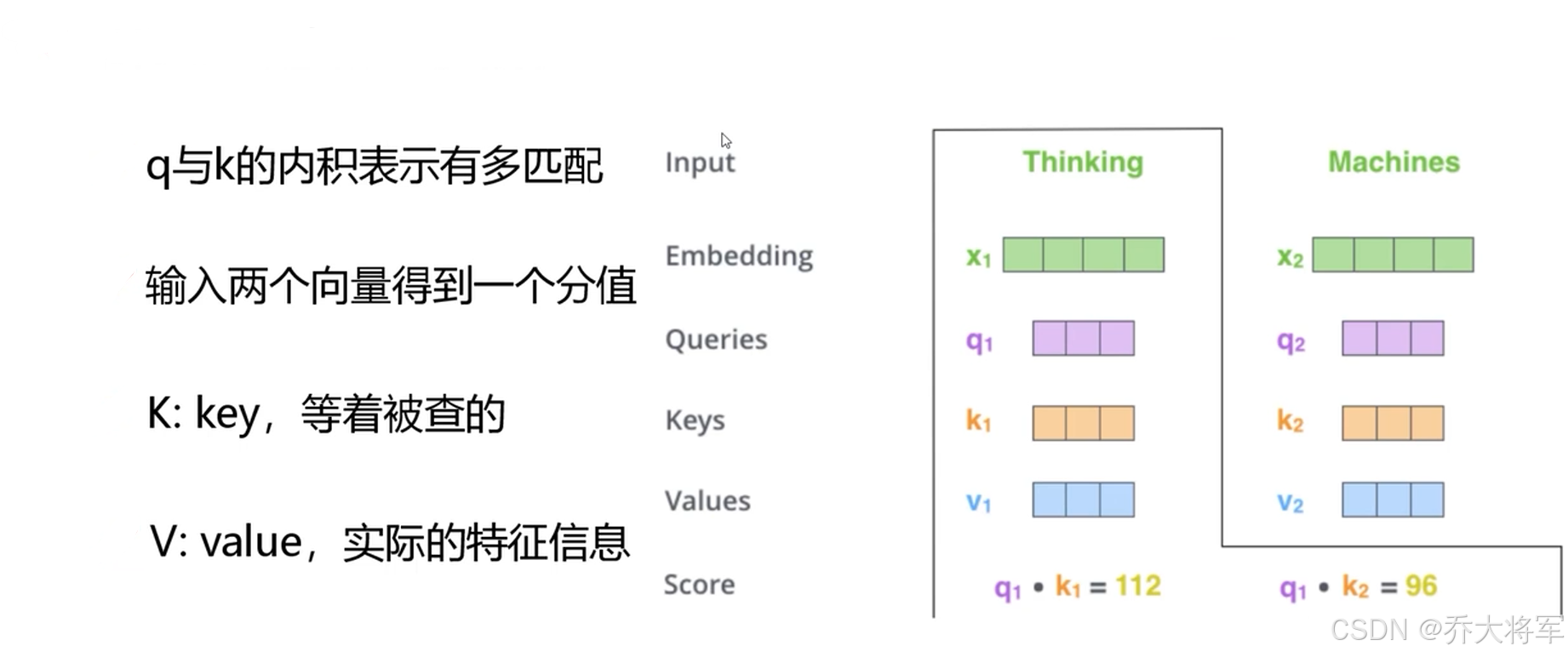
当两个向量求内积,若是两个向量垂直表示其线性无关,其值为0,若是两个向量线性相关其值越大表示两个向量相关性越大。那么表示上下文每个词相关性,值越大相关性越大。

为了不让分值随着向量维度增大而增加,让计算难度增大,最终除以
每一个词的Attention计算
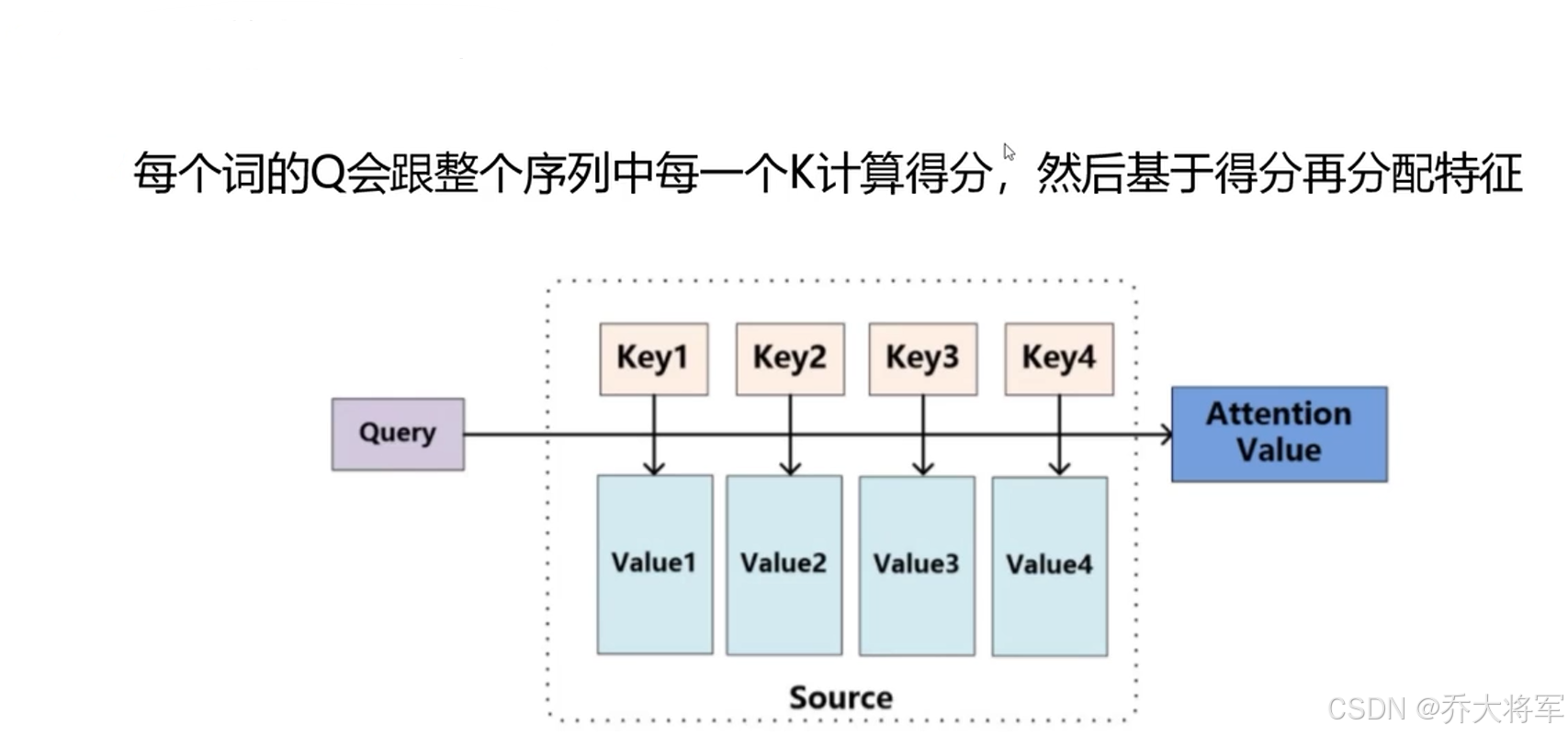
softmax后就得到整个加权结果

经过上述一系列分析,Self-Attention解决了并行计算和词向量的构建编码考虑到了上下文语境的问题。
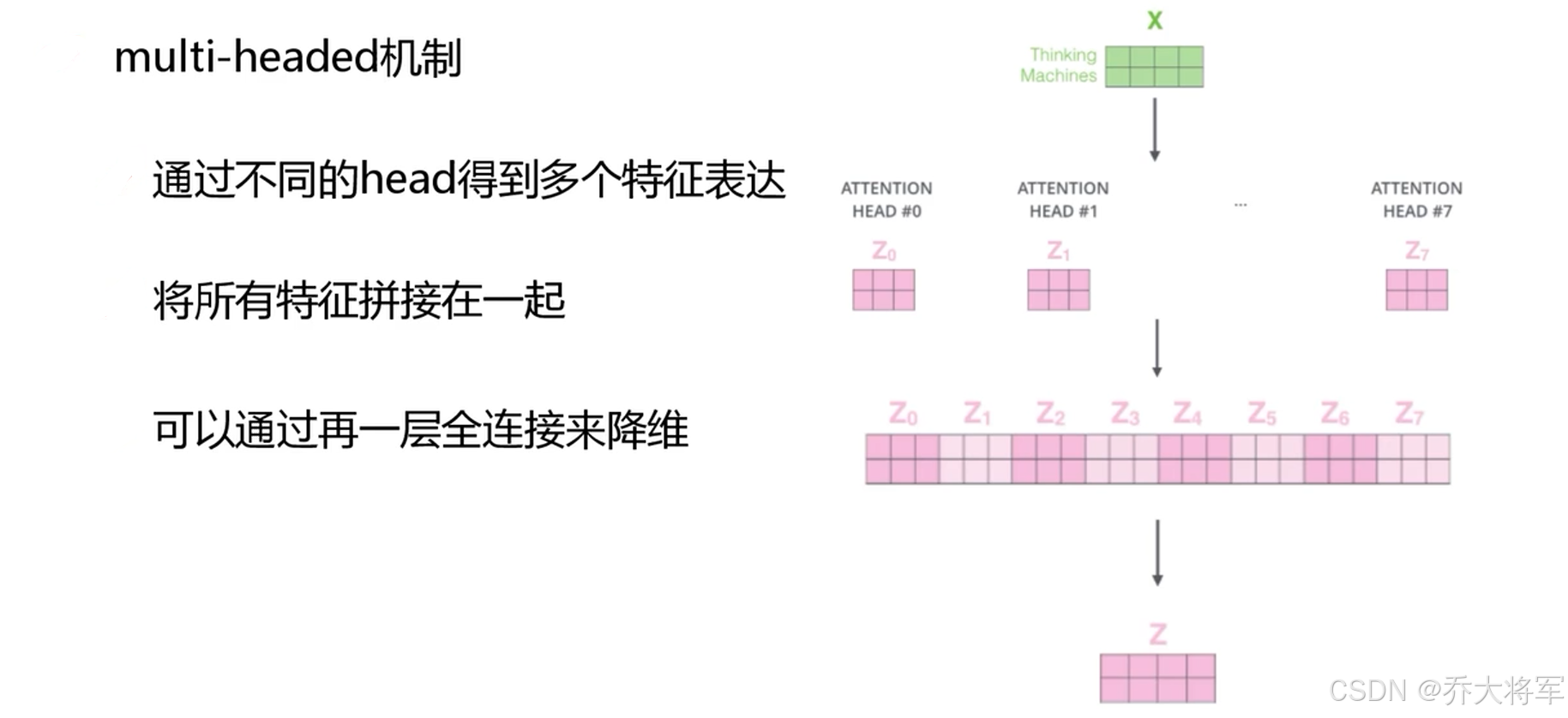
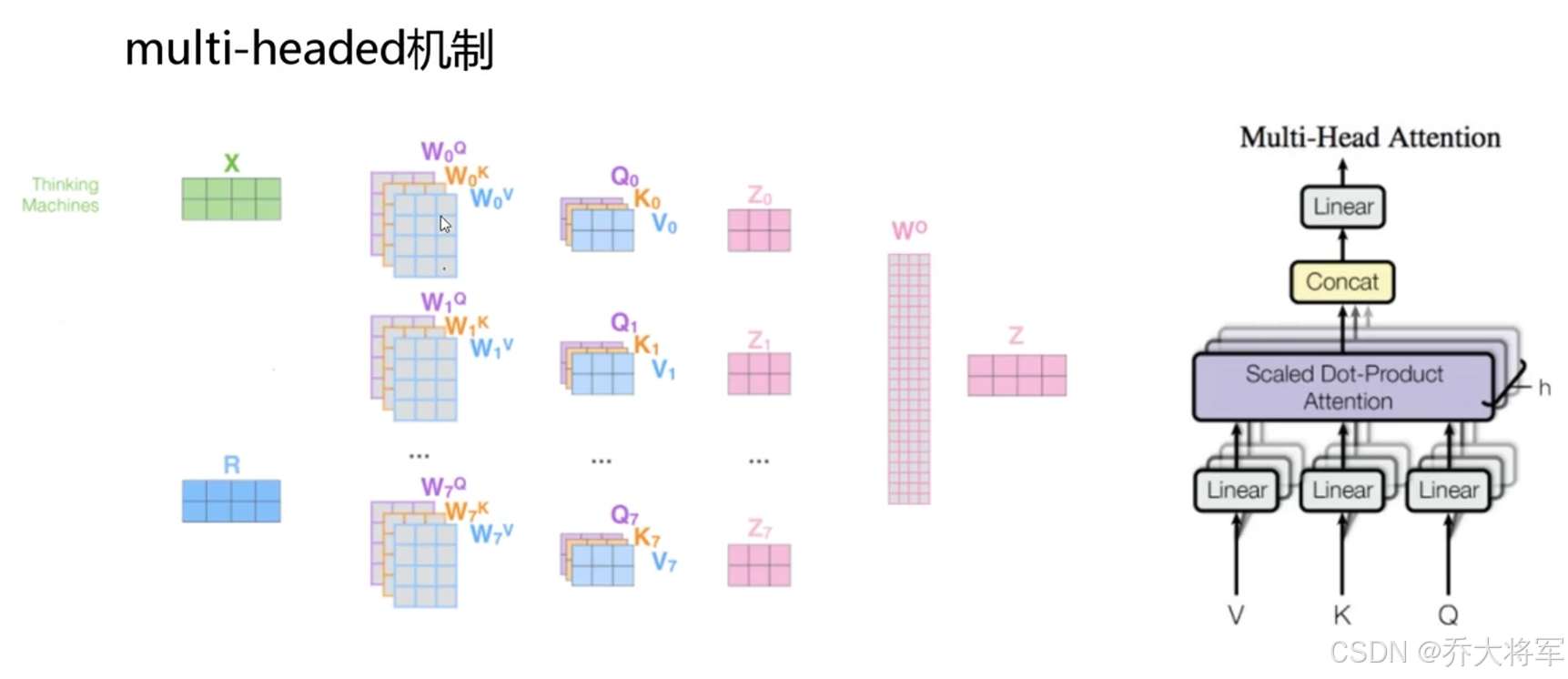
3.multi-headed机制


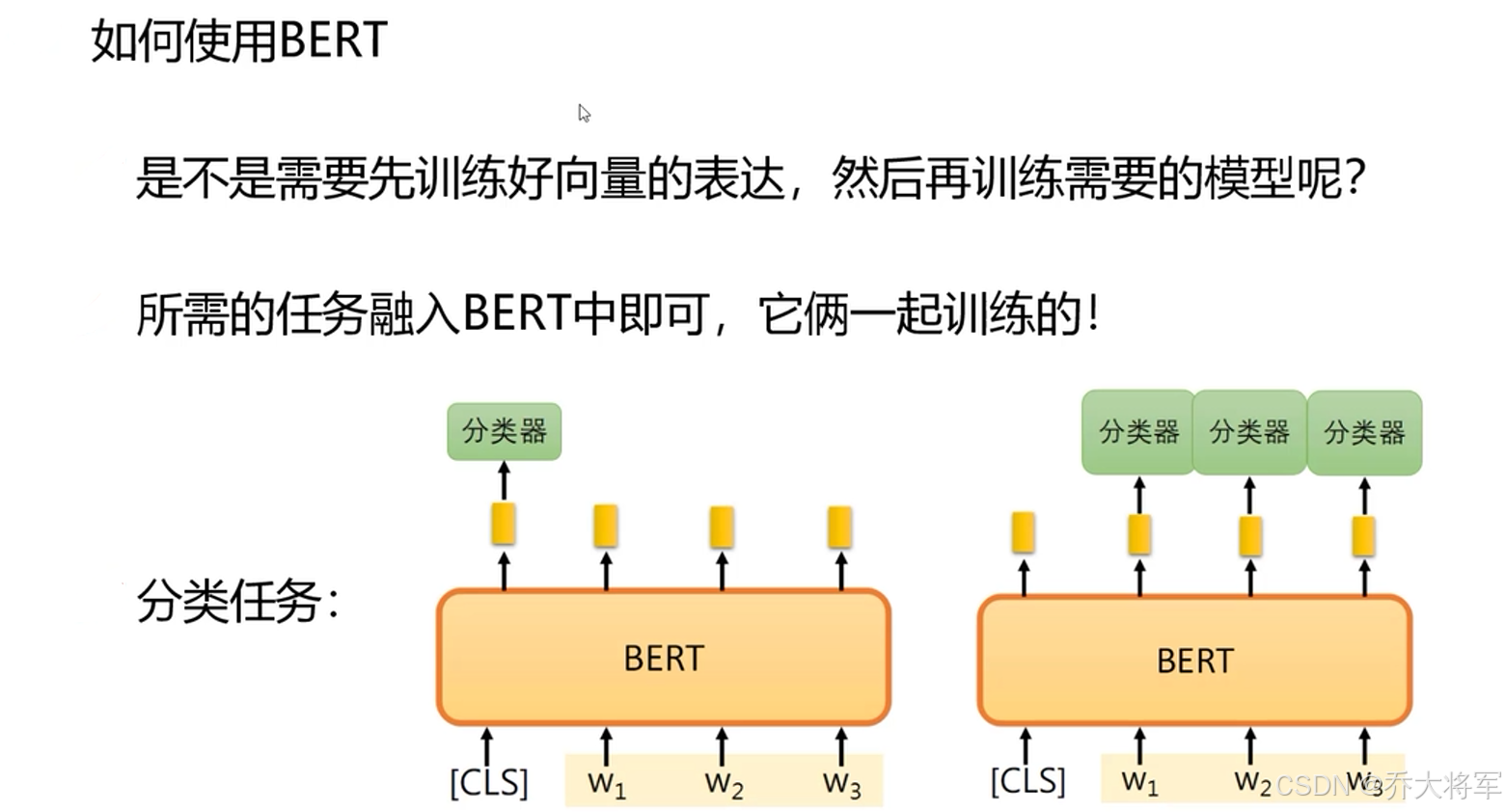
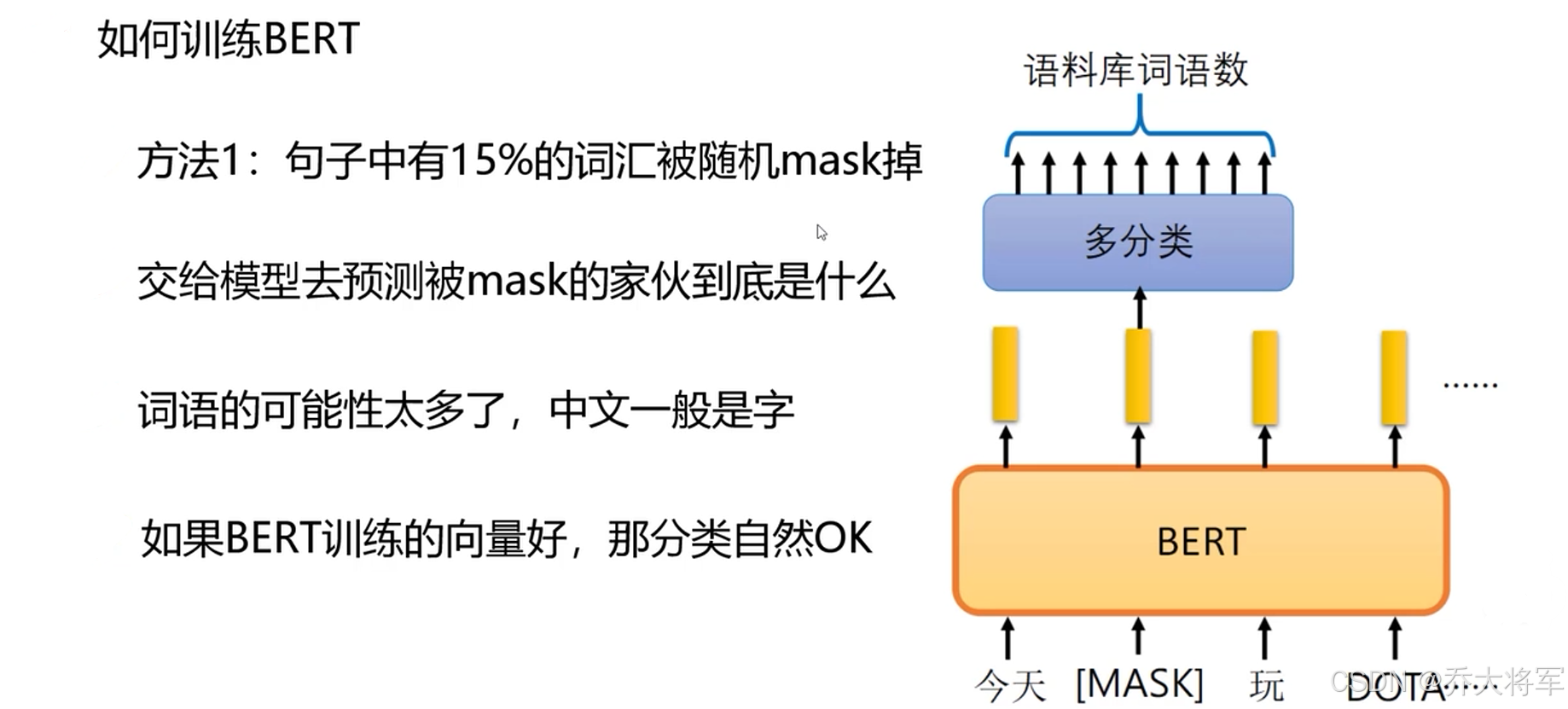
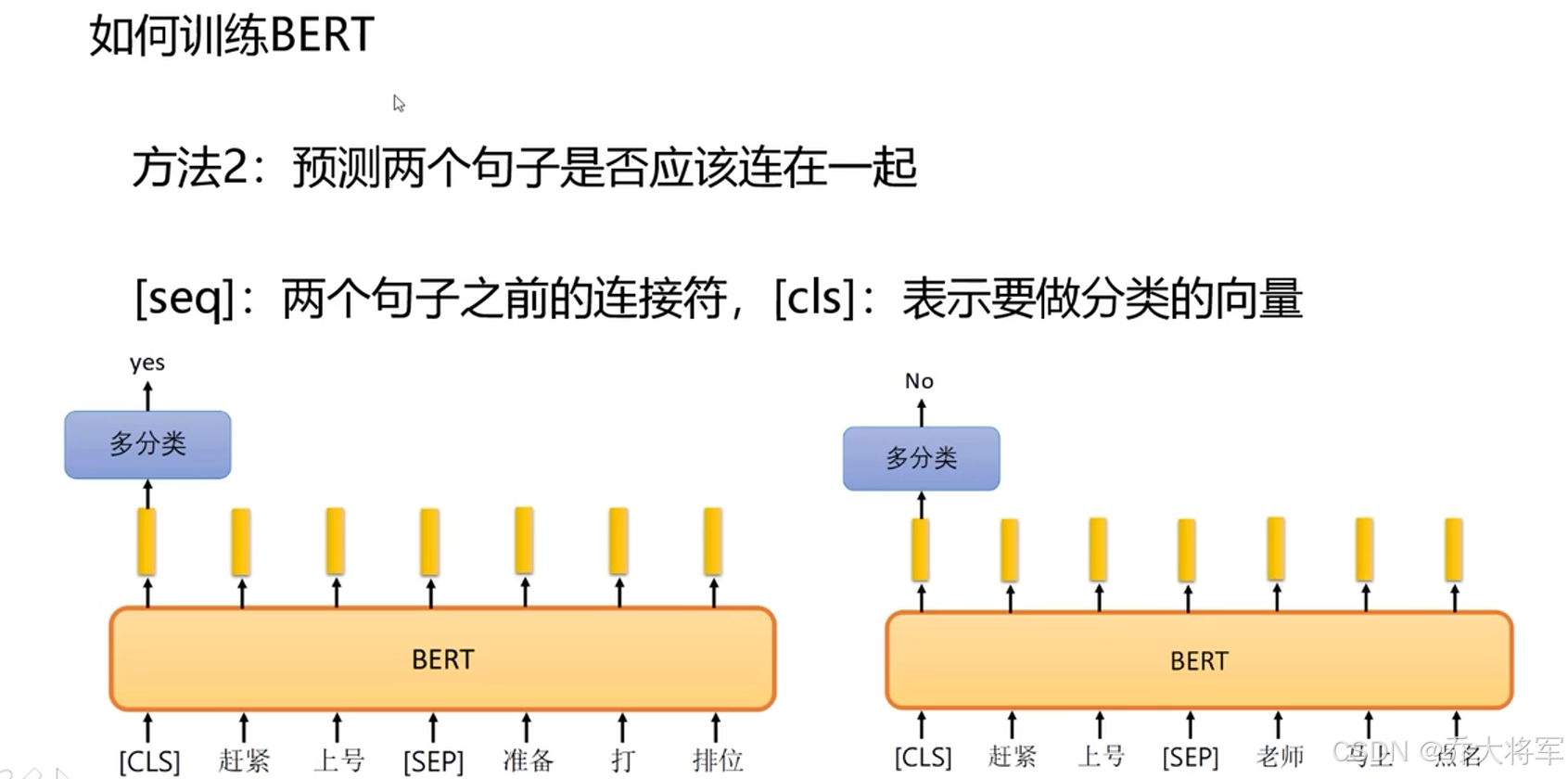
4. BERT训练方法
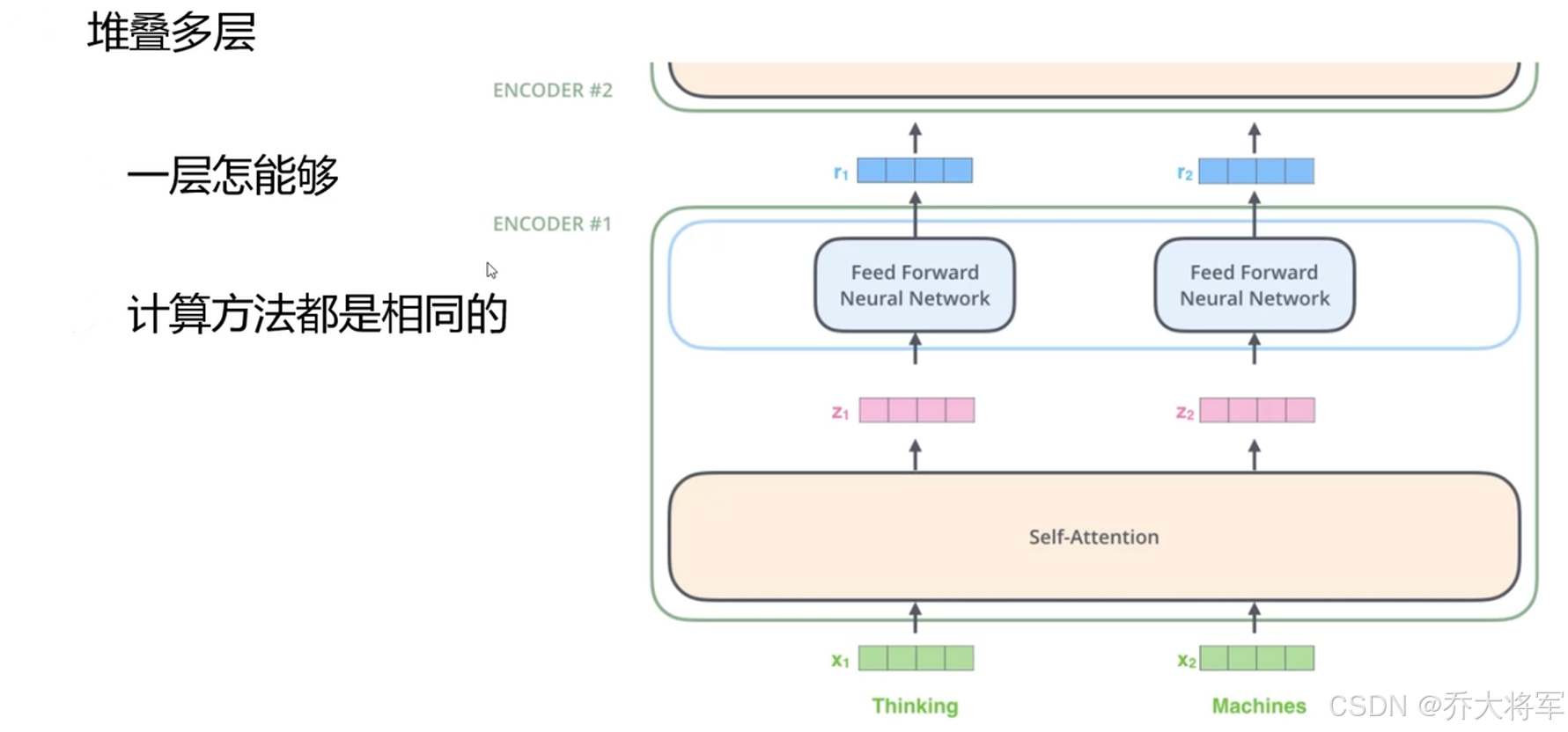
transformer中Encoder是重要的,就是编码方式。再将其进行下游任务微调,使其变成分类,预测等类型的任务。是自然语言处理的万金油模板。















 829
829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









