







在人工智能与自然语言处理交汇点,有一种技术正悄然改变与数据交互的方式——将日常语言转化为精准SQL查询。这一“text-to-sql”转换任务,使非专业人士也能轻松驾驭复杂的数据库操作,极大地拓宽了数据应用的边界。
然而,现有前沿方法往往依赖于封闭源代码的大型语言模型,它们虽然功能强大,却伴随着模型透明度缺失、数据隐私风险增大以及高昂推理成本等难题。有没有既开放、高效又安全的替代方案呢?鲁班模锤今天带来的论文《CodeS: Towards Building Open-source Language Models for Text-to-SQL》正在尝试破局。

课题背景
Text-to-sql的任务是指将用户的自然语言的提问(文本)转化成能在数据库上执行的结构化查询查询语言(SQL)。下图为对某一 “银行金融”数据库提出自然语言的问题,再转化为数据库查询语言(SQL)的过程。这个过程使得不熟悉SQL或数据库结构的用户也能够使用自然语言与数据库交互。

依赖部分现有的大模型也能实施,例如闭源的大语言模型 DIN-SQL(基于GPT-4)、SQL-PaLM(基于PaLM-2)或是C3(基于GPT-3.5)。尽管这些模型在Text-to-sql性能上表现出色,但也可能存在以下问题:
-
闭源模型隐藏了落地的具体架构以及训练/推理细节,阻碍了针对特定应用的持续开发。(这里突然想起来最近有位大佬说某大厂坚持闭源,回头另文点评)
-
通过API调用这些云端模型可能会带来数据隐私风险,因为必须将数据发送给模型提供商。
-
大多数闭源模型具有大量参数(例如基于GPT-3.5则有175B个参数),导致显著的推理开销,通常反映在调用API的花销上
综上所述,研究者推出了专为SQL生成而设计的开源语言模型CodeS。其特点是体量小,与ChatGPT和GPT-4比小10-100倍,而性能上却可以比肩SOTA。
知识补充:SOTA是“State of the Art”的缩写,这个术语通常用于描述某个领域或技术中当前最先进的成果或最高水平的性能。

基座模型StarCoder
StarCoder 和 StarCoderBase 是针对代码的大语言模型 (代码 LLM),模型基于 GitHub 上的许可数据训练而得,训练数据中包括 80 多种编程语言、Git 提交、GitHub 问题和 Jupyter notebook。与 LLaMA 类似,基于 1 万亿个词元训练了一个约15B参数的模型。此外还针对一个35B词元的Python 数据集对 StarCoderBase 模型进行了微调,从而获得了一个称之为 StarCoder 的新模型。当然这个系列有1B/3B/7B/15B四种规模的基座模型。


CodeS结构拆解
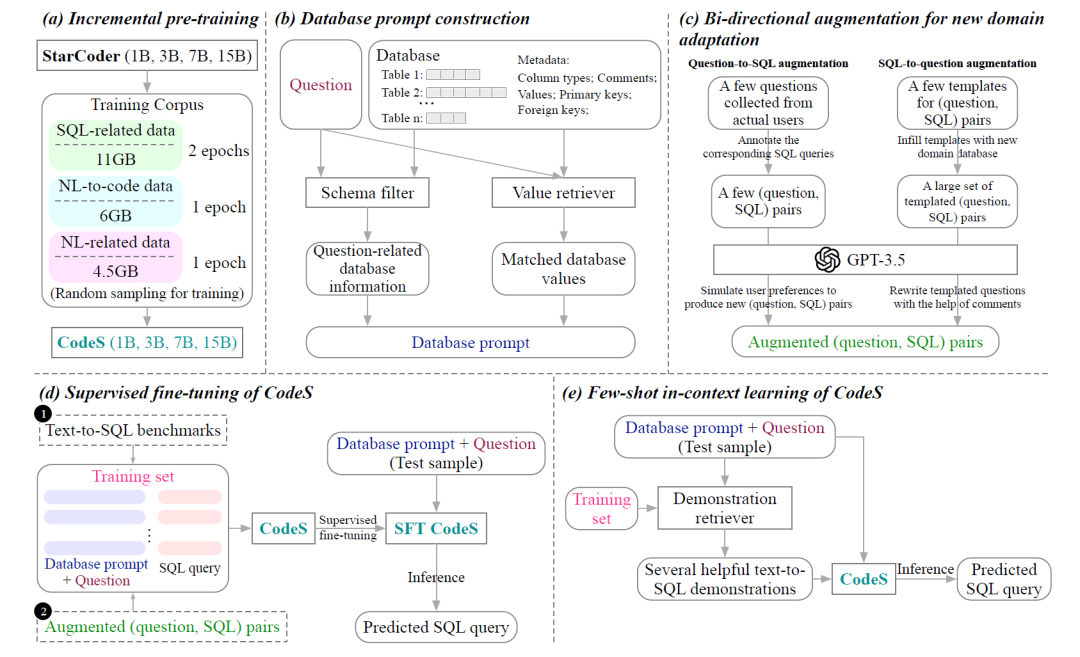
首先A阶段为了提高现有语言模型的SQL生成和自然语言理解能力,研究人员采集了新语料库,该语料库由来自不同来源的11GB SQL相关数据、6GB NL-to-code(自然语言转代码)数据和4.5 GB NL相关数据集组成。基于StarCoder,采用该语料库进行增量预训练,并获得预训练的语言模型CodeS(StarCoder按照上文而言拥有1B、3B、7B和15B 4种规模)。
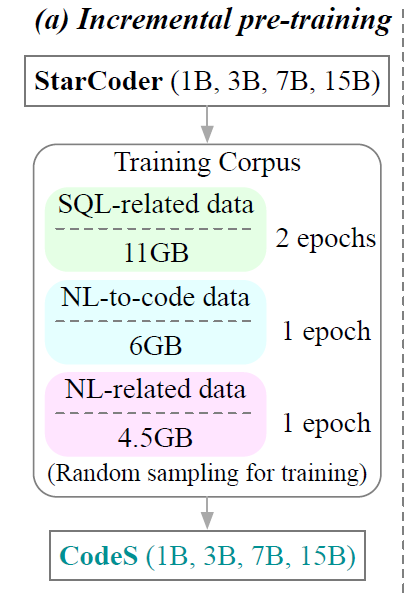
紧接着来到了B阶段,研究人员提出一种全面的数据库提示构建方法来生成高质量的数据库提示。该策略主要包含模式过滤器和值检索器。模式过滤器是根据给定的问题消除不相关的表和列。值检索器经过定制可以提取与问题相符的潜在有用的数据库值。 除了表名和列名之外,还合并了各种元数据,包括数据类型、注释、代表性列值以及主键和外键的信息。 如此为文本到SQL的转化提供更加真实而且丰富的上下文。

这个时候来到了C阶段,毕竟不同的客户拥有不同的业务数据库,但是又无法提供足够多的适配样本。因此研究人员提出了一种双向数据增强方法,为新应用场景自动化的生成大量新语料(提问和对应的SQL语句)。 那么如何操作呢?在文本-SQL方向的语料方面,从现实的业务场景入手需要人工标记一些数据项,再交由GPT-3.5模拟生成进行语料库扩展。而在SQL-文本方向的语料方面则需要研究人员从现有的文本-SQL的基准中提炼模板,然后用新的业务数据库填充模板,然后使用 GPT-3.5 来自动的精炼语料。 这种双向策略创建了最小人力标注投入,但是能够构建一个强大和好用的训练集。
|
|
|
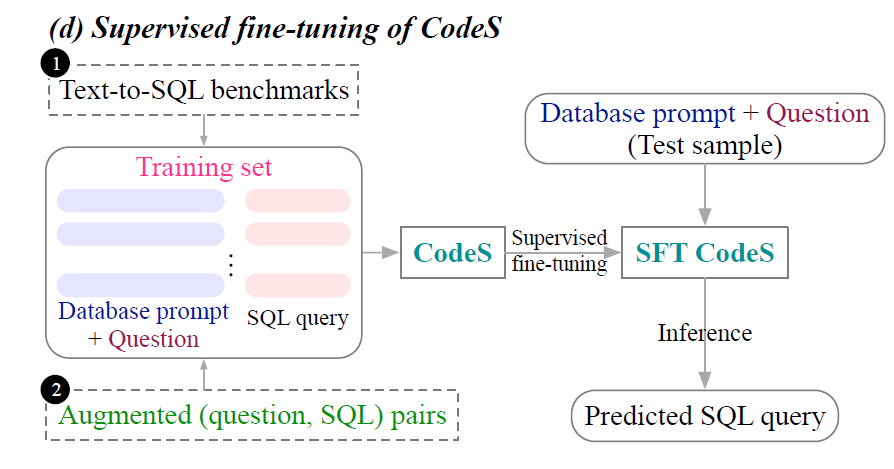
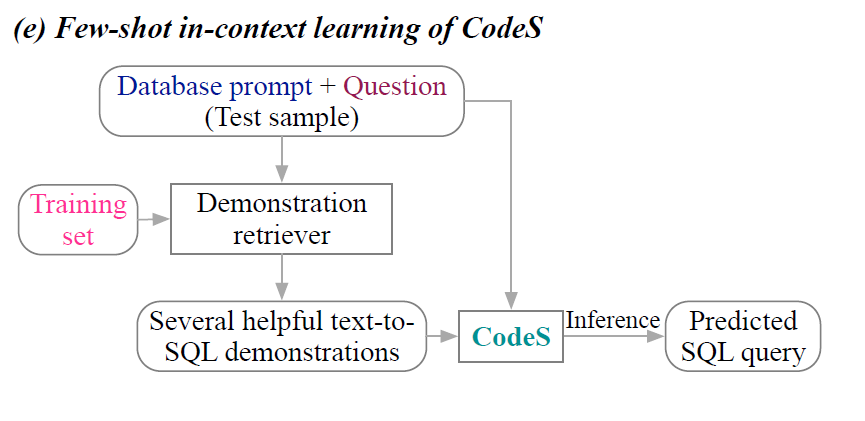
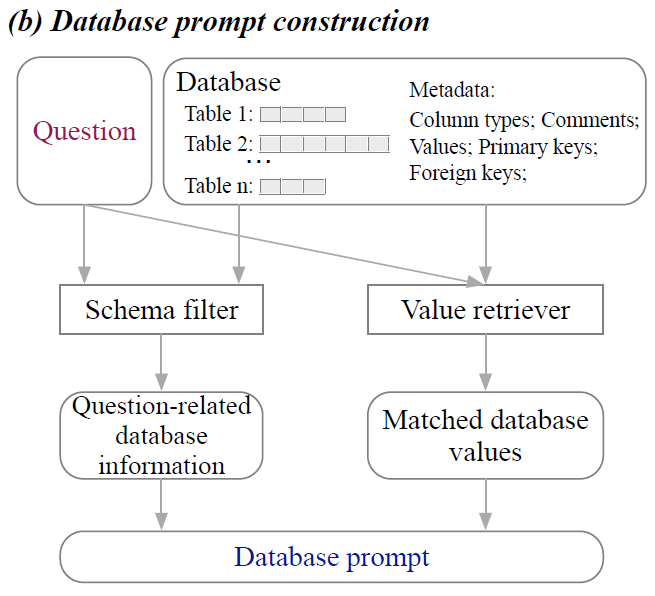
若有着丰富的训练数据,CodeS出现的D阶段就可以执行,利用SFT进行模型训练(后续会解释,这里可以理解为对于大模型的部分参数进行微调)。
相反,若训练数据有限,那么只能使用不改变模型参数的In-Context学习(阶段E),只能提供一些文本到sql的演示,在不微调模型的情况下利用大模型的学习和模仿能力快速给出答案。
在这两种模式种,Incremental pre-traning(阶段A)和Database prompt construction(阶段B)都是其基石,而在SFT策略模式中还需要Bi-directional augmentation for new domain adaptation(阶段C)的辅助。下篇文章将开启具体组件的详细解读。














 835
835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









