







大模型技术论文不断,每个月总会新增上千篇。这个专栏的解读的精选论文均围绕着行业实践和工程量产。若在阅读过程中有些知识点存在盲区,可以回到如何优雅的谈论大模型重新阅读。另外斯坦福2024人工智能报告解读为通识性读物。若对于如果构建生成级别的AI架构则可以关注AI架构设计。技术宅麻烦死磕LLM背后的基础模型。当然最重要的是订阅跟随“鲁班模锤”。
在人工智能与自然语言处理交汇点,有一种技术正悄然改变与数据交互的方式——将日常语言转化为精准SQL查询。这一“text-to-sql”转换任务,使非专业人士也能轻松驾驭复杂的数据库操作,极大地拓宽了数据应用的边界。
然而,现有前沿方法往往依赖于封闭源代码的大型语言模型,它们虽然功能强大,却伴随着模型透明度缺失、数据隐私风险增大以及高昂推理成本等难题。有没有既开放、高效又安全的替代方案呢?鲁班模锤今天带来的论文《CodeS: Towards Building Open-source Language Models for Text-to-SQL》正在尝试破局。本章节将承接上一篇,有兴趣的同学可以仔细推敲。

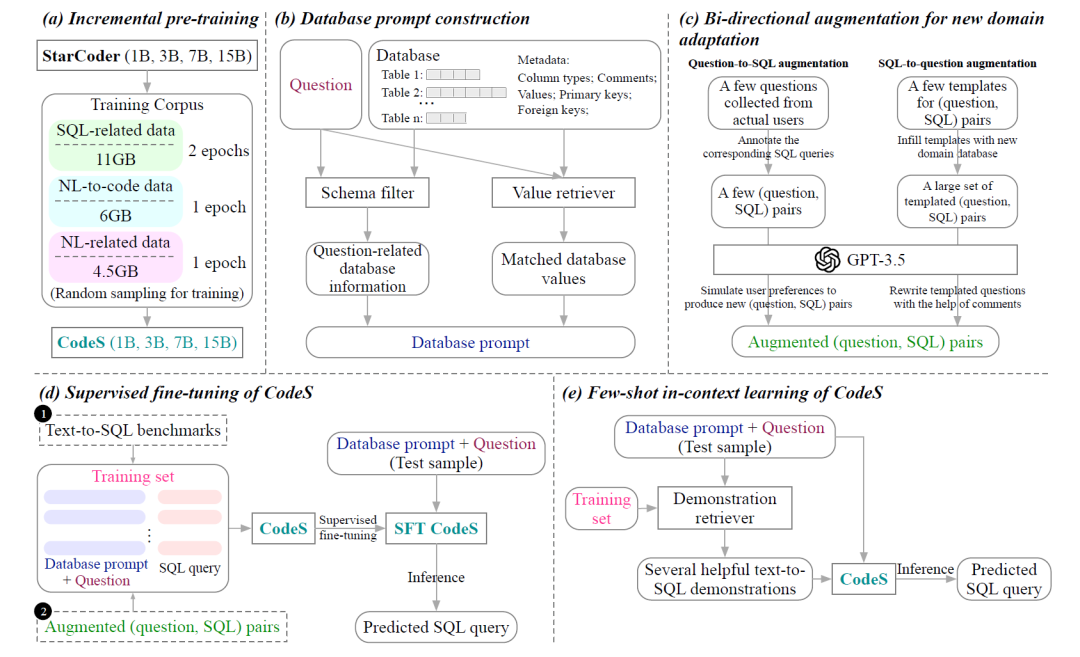
模块A:增强的预训练
要让模型能够从文本生成SQL,模型必须具备两种能力:SQL生成能力和自然语言理解能力。为了增强模型的生成能力,训练数据集从三个方向收集了语料:SQL相关数据(SQL-related data)、自然语言相关数据(natural language-related data)、自然语言转代码数据(natural language-to-code data)。
SQL相关数据一共11GB,采用了StarCoder的预训练语料库
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1341
1341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









