








这个专栏的解读的精选论文均围绕着行业实践和工程量产。若在阅读过程中有些知识点存在盲区,可以回到如何优雅的谈论大模型重新阅读。另外斯坦福2024人工智能报告解读为通识性读物。若对于如果构建生成级别的AI架构则可以关注AI架构设计。技术宅麻烦死磕LLM背后的基础模型。
前情回顾,组件A主要是基于模型StarCoder的预训练模型,通过各种语料训练处论文所采用的基座模型CodeS。组件B的作用是构建数据库提示词(Database prompt),围绕着用户提问,通过两个核心引擎完成对于提问相关的上下文补充以便提高生成的正确率。组件C的目的十分明显,“以小博大”,通过一些自动化的技巧扩充语料。C是利用GPT3.5来完成辅助的语料扩充。
当在实际场景应用CodeS时,给了两套适配方案,Supervised Fine-Tuning以及Few-shot In-Context Learning。大白话讲就是,微调CodeS的参数,以及将上下文放到提问中让模型回答。

模块D:模型微调
实验的主要数据集来自两个英文评估基准(Spider、BIRD)以及金融和学术两个领域数据库Bank-Financials和Aminer-Simplified。此外还额外采用Spider-DK,Spider-Syn,Spider-Realistic,Dr.Spider作为测试集来评估模型鲁棒性。
Spider-DK:文本到 SQL 模型对陌生领域SQL生成鲁棒性评估;
Spider-Syn:文本到 SQL 模型对同义词替换的鲁棒性;
Spider-Realistic:专门设计用来模仿真实世界场景中用户可能提出的问题来检验鲁棒性。
Dr.Spider:融入了横跨问题、数据库及SQL查询的17种不同扰动,以此来全面评估文本到SQL模型的鲁棒性。包括3个涉及数据库扰动的测试集,9个反映问题扰动的测试集,以及5个含有SQL扰动的测试集。
|
|
|
|
|
|




扰动有很多种,包括DB扰动,SQL扰动。扰动的简单理解在于因为SQL的自动化生成存在很多障碍,需要完整的理解,同时选择合适的SQL范式,最后还要应对有可能存在的同名或字面含义的干扰。因此扰动的评估指标十分重要,可以从另外一个维度来衡量一个模型的好坏。

语料准备好了之后,通过模块B进行查询增强,得到全新的训练语料。接下来就开始进行微调,微调的技术又很多种。大致的内在逻辑还是围绕着新的语料,局部或者全面的调整模型参数,进而获得更优的模型表现。
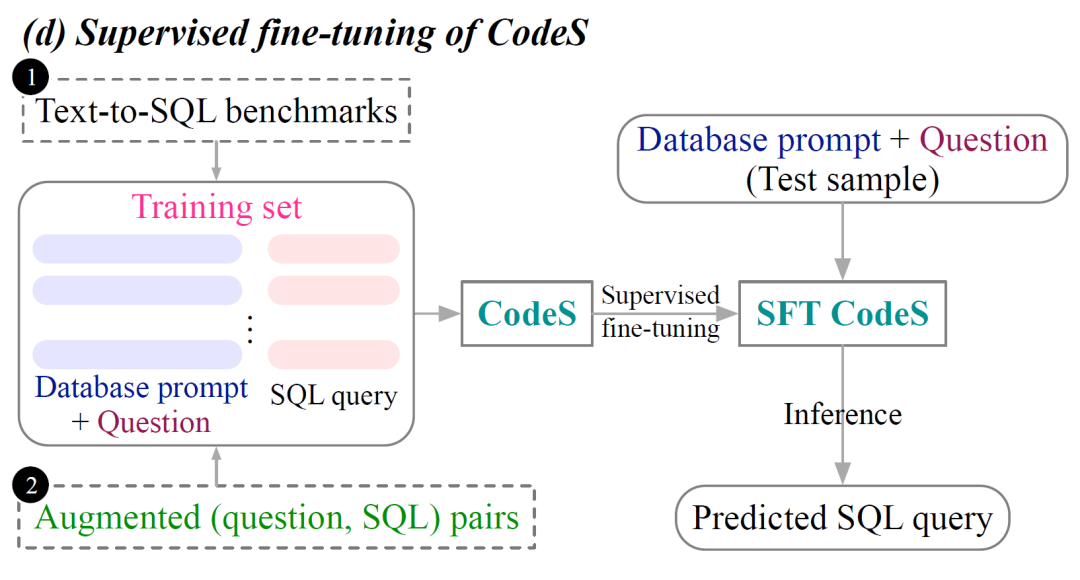
微调技术会放在其他的章节讲解。这里的有监督微调比较中规中矩,微调数据来至Text-to-SQL的评估基准以及模块C生成的增强语料,增强语料主要是基于金融和学术两个领域数据库
那么接下来就来看看微调的效果,研究者在两个英文到SQL基准测试上进行主要实验:Spider 和 BIRD。 同时还评估了四个更具挑战性的基准:Spider-DK、Spider-Syn、Spider-Realistic 和 Dr.Spider。研究者利用Spider为训练集,并根据这些鲁棒性诊断测试集评估模型。
对于Spider系列基准测试有两个流行的评估指标:执行准确性(EX)和测试套件准确性(TS)。EX指标评估预测的SQL 查询和真实的 SQL 查询是否产生结果。然而EX可能会给出误报,即错误的 SQL恰好产生与正确SQL相同的输出。TS则评估生成的SQL 查询能否一致地通过多个数据库实例的EX评估,减少“阴差阳错”的事件概率,进而证明预测的SQL是真实有效的。
|
|
|
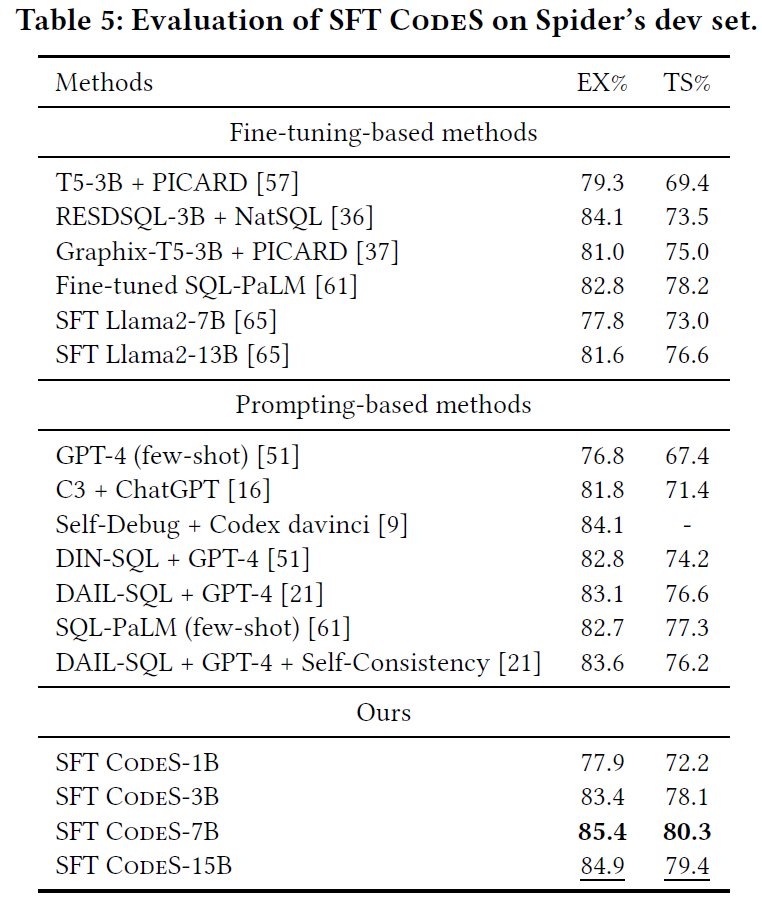

左图Spider基准上观察,SFT CodeS-7B和SFT CodeS-15B在Spider开发集上达到了新的SOTA(最新技术状态)性能。然而,SFT CodeS-7B相比SFT CodeS-15B表现出了轻微的优势,这表明CodeS-15B可能对Spider训练数据过拟合,这可能略微影响了其对开发集的泛化能力。
右图Spider 衍生基础上观察,SFT CodeS-7B与最佳基线相比,在Spider-Syn上提高了2.6%(从67.4%提高到70.0%),在Spider-Realistic上提高了4.0%(从73.2%提高到77.2%),在Spider-DK上提高了4.5%(从67.5%提高到72.0%)。

来到了最重要的鲁棒性测试,在Dr.Spider上测试模型的结果如上图。总体而言,即便在没有可以去设计稳健性,研究者的模型也具备文本到SQL的弹性。
-
对于数据库扰动,CodeS稍微落后于ChatGPT + ZeroNL2SQL,大概率还是受到数值的影响。ChatGPT + ZeroNL2SQL使用密集检索器来提高语义准确性,但是开销巨大。本文的CodeS采用的是稀疏检索器。
-
在自然语言问题扰动方面,SFT CodeS-7B和SFT CodeS-15B均优于之前最好的 Chat-GPT + ZeroNL2SQL。本文的解决方案可以更好地掌握问题语义,实现更准确的SQL查询。
-
对于SQL扰动,模型稍微落后于RESDSQL-3B + NatSQL。NatSQL的SQL表示形式更简单,但其语法仅限于Spider,适应性较差。
-
在全局平均性能方面,SFT CodeS-7B和SFT CodeS-15B略胜过之前的最佳产品 ChatGPT + ZeroNL2SQL,后者是为强大的文本到SQL定制。
而在BIRD的基准上也是妥妥的~


消融研究
E模块其实就是最简单的通过在查询过程中加入样例,在不调整模型参数的情况下得到结果,更多的是如何挖掘CodeS这个模型的潜力,这里就不展开讨论。让小编比较感兴趣的是这个方案中的组件是否真的有效,研究人员做了消融研究,也就是在去掉一些组件的情况看看微调的效果,证明这些组件的有效性。

-
选择问题相似性来检索样例会导致 Spider 上的性能下降。选择随机的检索器来替代本文的demonstration retriever时,在大多数情况下性能都会下降。
-
若去掉架构过滤器,由于输入序列较长,性能会下降,生成速度也会变慢。若去掉值检索器还会导致文本到SQL的性能显着下降,尤其是在BIRD 基准测试上,这凸显了它在生成 SQL 查询谓词方面的关键作用。
-
若在元数据增强支持方面,列数据类型增强对性能影响较小,因为模型从列名称和注释推断类型。注释增强会显着影响BIRD基准测试的性能。数据库值和主/外键的增强对于Spider和BIRD的性能至关重要,因为除了提供了对数据库数据值格式理解助力之外,还有助于准确生成JOIN ON子句。
综上,若需要构建定制化文本到SQL的大模型,可以参考这份论文。其中给出的一些范式还是具有实操的价值。















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









