








GPU的运算模型
上一章节已经介绍了显卡的基本结构,由内存和计算单元SM组成。那么显卡的运算模型是什么样子?它如何将机器学习的任务转化为合适的运算指令?当然这里不针对Cuda编程展开细节的讨论,但是还是需要对它的运算模型有一定的了解。
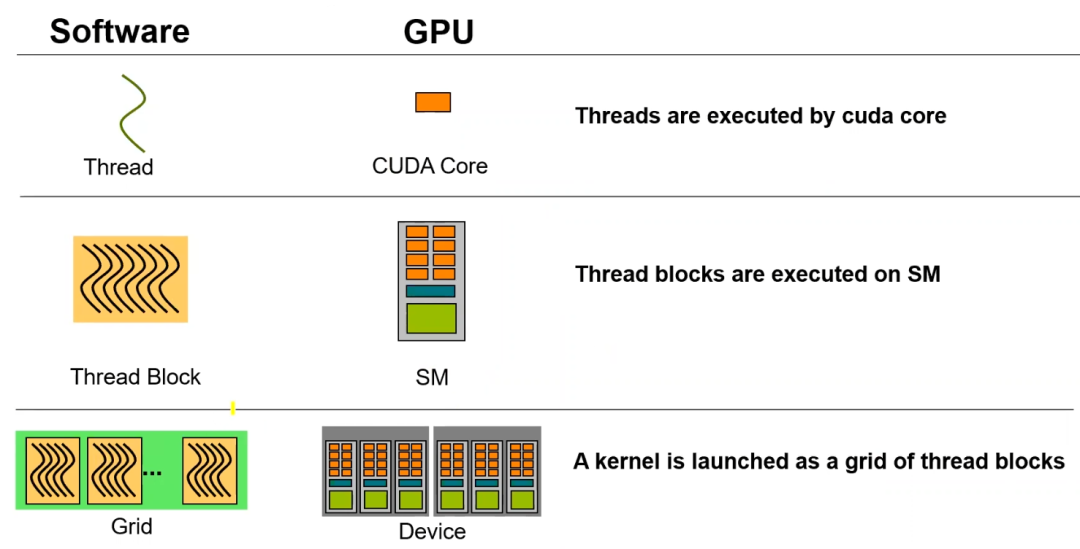
计算模型中的线程(Thread)、线程块(Block)和线程网格(Grid)三个概念,分别对应着Cuda Core、SM和kernel三种不同维度的计算单元。一个内核(kernel)会启动多个线程块,这些线程块会在SM之间进行调度。分到任务的SM则将线程块的内部线程分配给具体的Cuda Core执行。

在计算模型中,所有线程都是并行执行的。一个线程块只能分配到一个SM上执行,同一个SM中的线程可以互相通讯。一个线程网格生成多个Block会被调度到多个SM
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4170
4170

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









