







大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。当然最重要的是订阅“鲁班模锤”。

Embedding模型概览
Embeddings是自然语言处理技术中很重要的基石。它有很多种模型,从GloVe、word2vec、FastText、Bert、RoBERTa、XLNet、OpenAI ada、Google VertexAI Text Embeddings、Amazon SageMaker Text Embeddings和Cohere。每种模型都有优劣,如何去分析这些Embeddings技术,重点可以关注如下的参数信息:能否在编码中捕获上下文信息、能够处理非词表之外的单词、泛化的能力、预训练的效率、是否免费、最终效果质量。
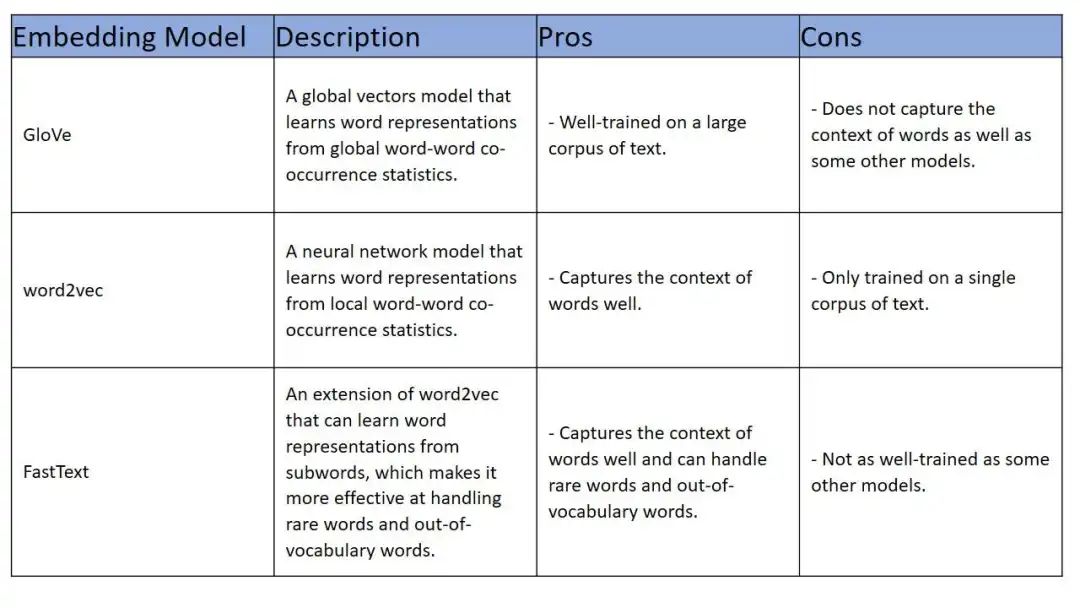
一般而言在大型文本语料库上经过良好训练并且能够很好地捕获单词上下文的模型,那么GloVe、word2vec 或 FastText都是不错的选择。
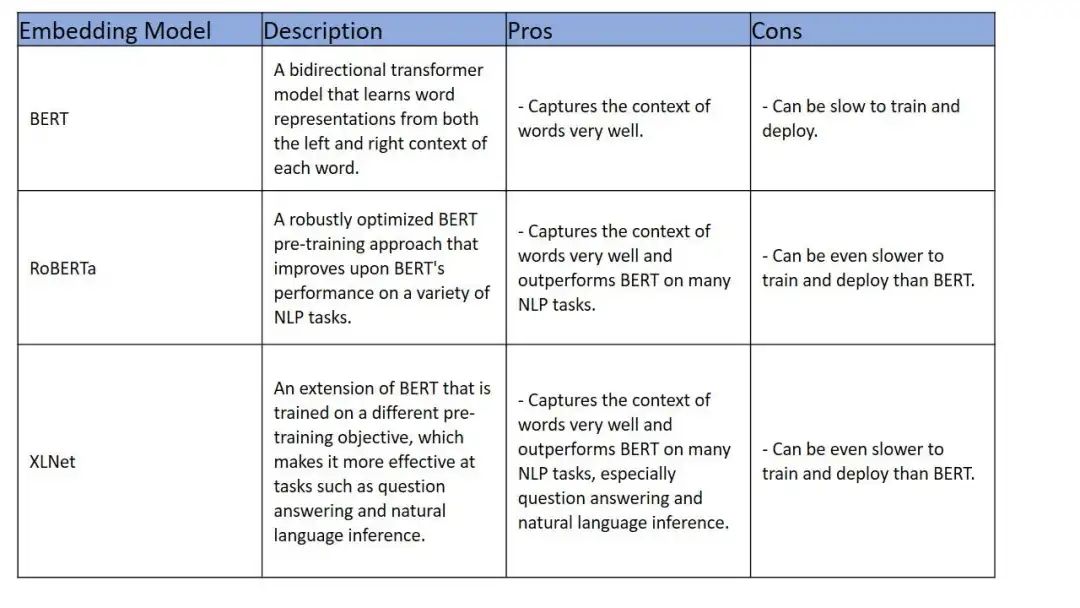
若某个业务场景急需更好的捕获单词上下文,而且变现需要优于Bert,那么RoBERTa或XLNet是不错的选择。
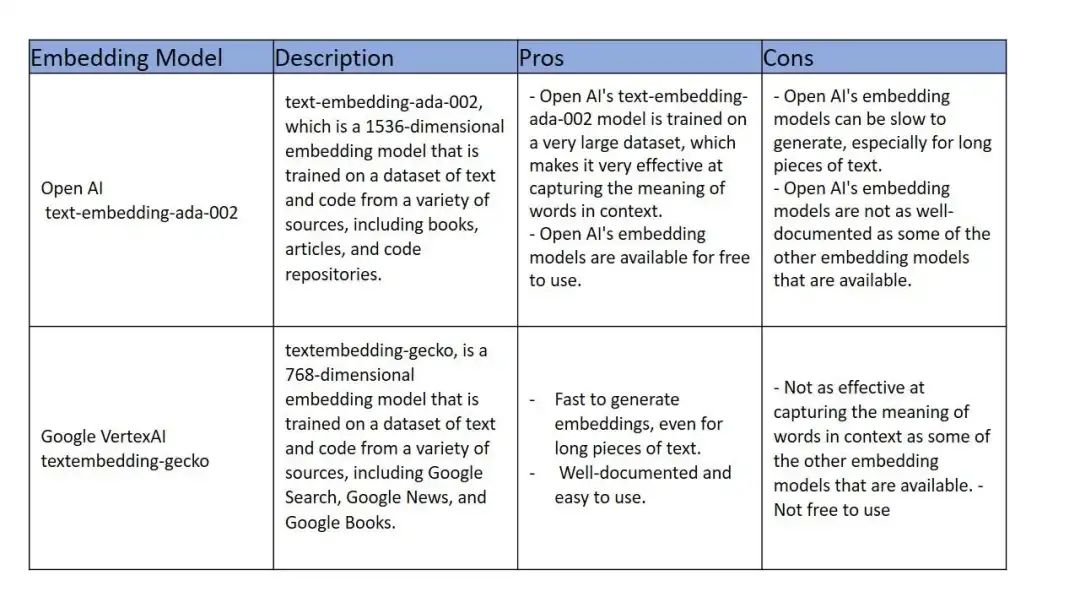
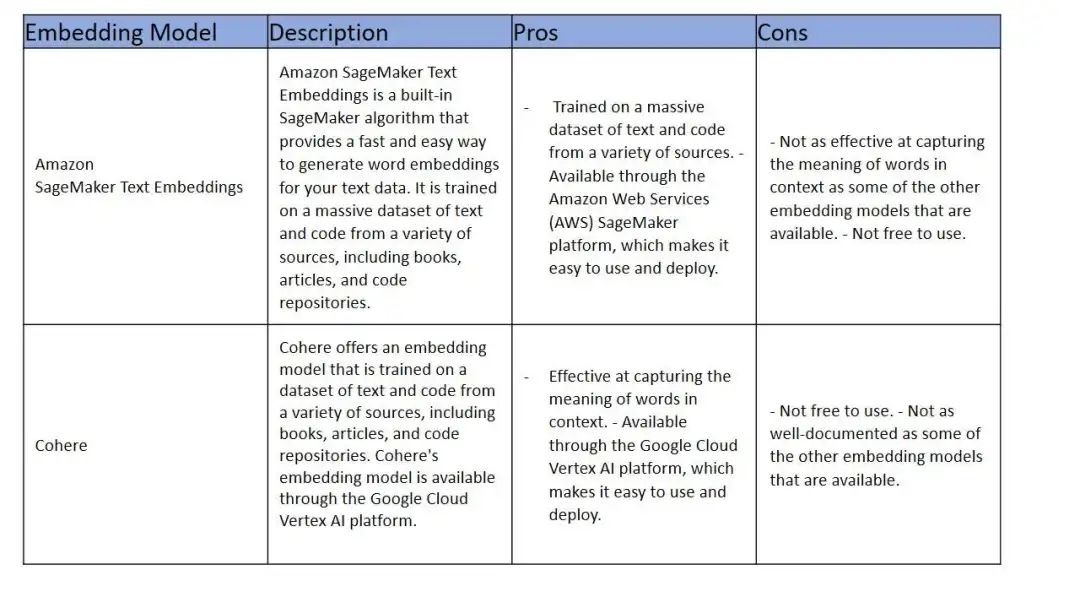
其他大公司的Embeddings模型,有免费也有收费的。OpenAI、Google、Amazon都可以按需选择。
Embedding模型和训练数据有关,用于训练模型的训练数据的大小和质量更大更高,则会产生更好的模型。还有一些选择的限制,例如XLNet是问答和自然语言推理的最佳选择,而RoBERTa是文本摘要和机器翻译的最佳选择。

Word2Vec
Word2Vec有两种,CBOW和Skip-Gram,很多资料都没有划对重点。那么接下跟随小鲁来正确打开。
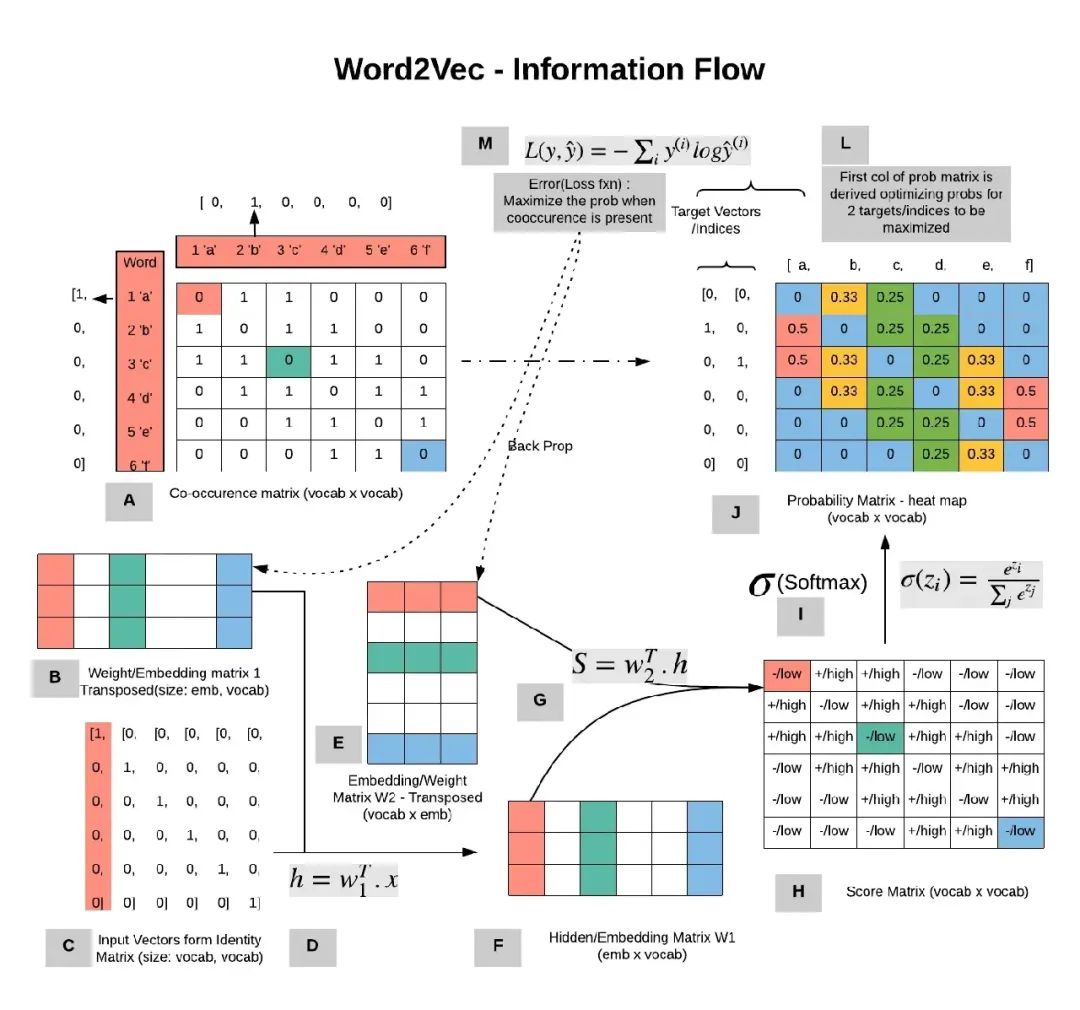
先铺垫下背景,假如已经拥有某个语料库,需要对语料库的词汇进行Embedding(下文统一称为编码)。那么可以将语料库的所有文本串起来。然后预设窗口的大小(下图的示例为5),每个窗口正中的橙色部分即为目标单词,而绿色部则为上下文单词。随着窗口的滑动,就可以获取很多的样本(目标单词,上下文单词)。然后利用这些样本进行编码器的训练。
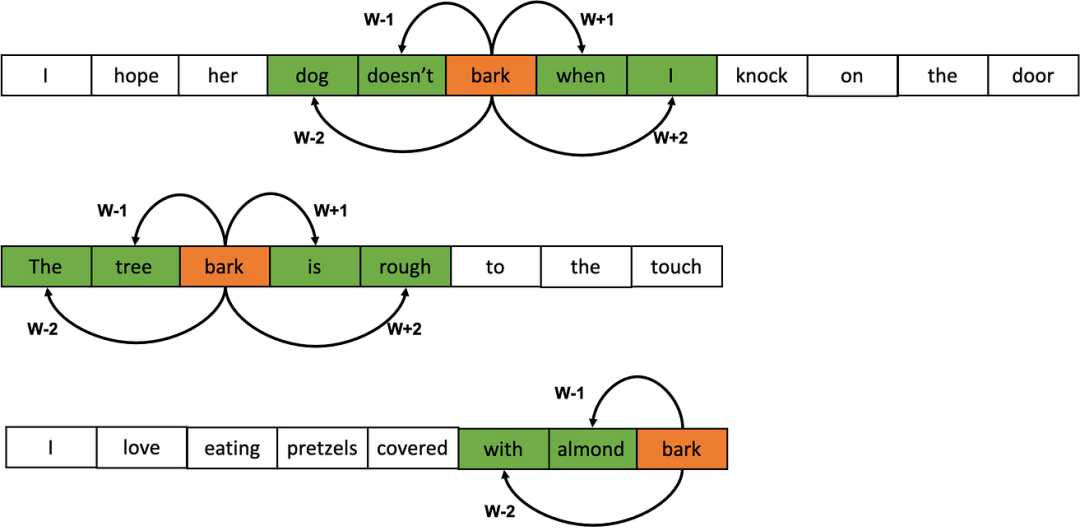
那么CBOW和Skip-gram的区别就在于CBOW是用上下文的字符去预测目标单词,而Skip-gram则是用目标单词去预测上下文单词。
|
|
|
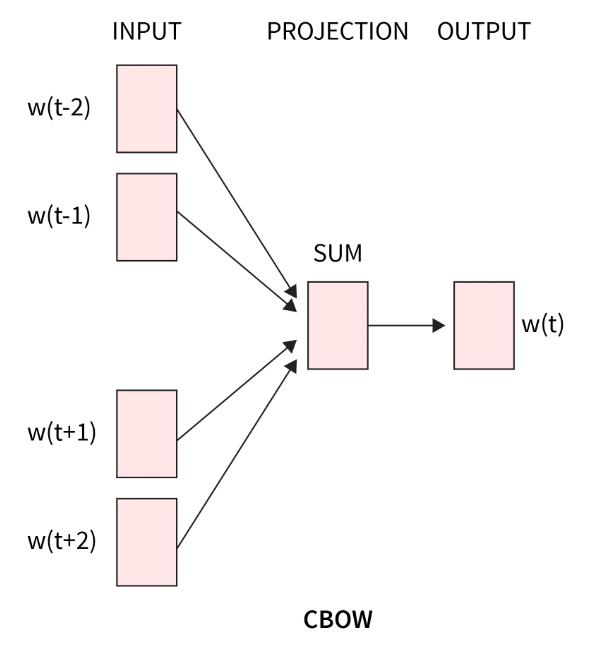
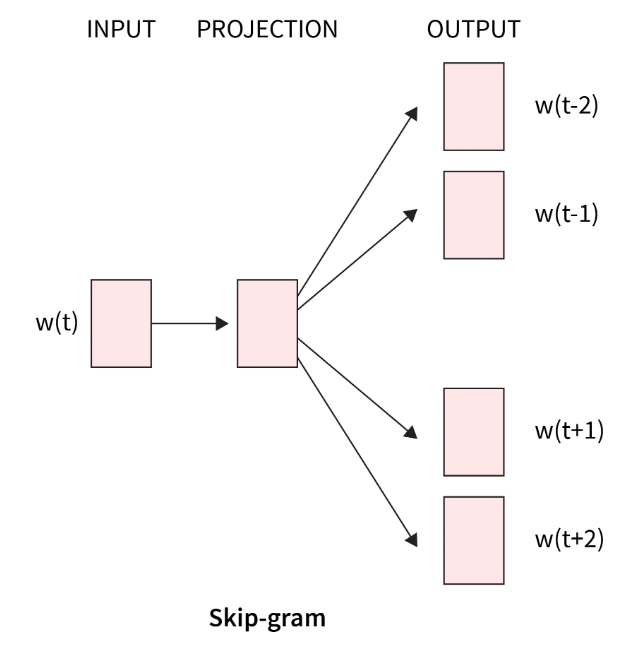
是不是到这里开始有点凌乱了,不是embedding model么,不是学习编码么,怎么变成预测了?其实就是通过刚才获取的样本进行训练编码,以CBOW为例,将这个过程放大如下图。
四个上下文单词输入经过一层的矩阵运算之后,得到了中间变量,然后在通过另外一个矩阵运算算出目标单词,然后将目标单词和预测的结果对比,反过来调整两个矩阵的权重。如此反复直到损失收敛。
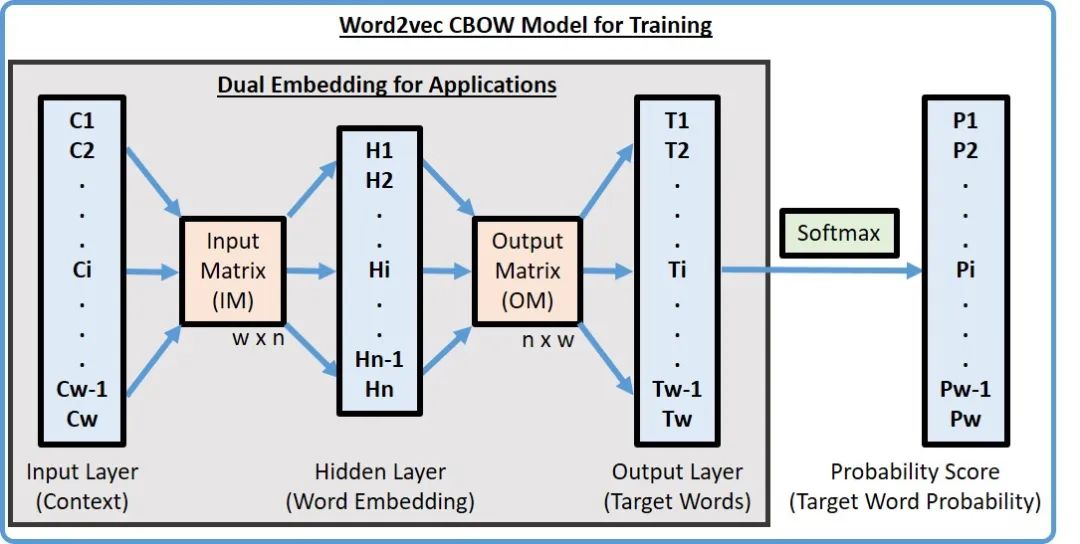
这个过程其实就是为了通过训练得到橙色的两个矩阵,前面的矩阵学名为查询矩阵,后面矩阵学名为上下文矩阵。任何的输入通过这两个矩阵就可以编码。回到刚才的两种算法,无论谁预测谁,目标都是为了校正这两个矩阵。
下面是数学版本的推理过程,数学小白可以跳过。输入V维(也就是词汇表为V),每个词汇用N维的向量表示,那么需要学习的矩阵就是一个V*N维,一个N*V维。


Co-occurrence Vector
上一篇文章发布之后,有好学的同学咨询若滑动窗口,按照统计学的方法其实也可以得到一个矩阵,那么是如何计算每个单词的编码。
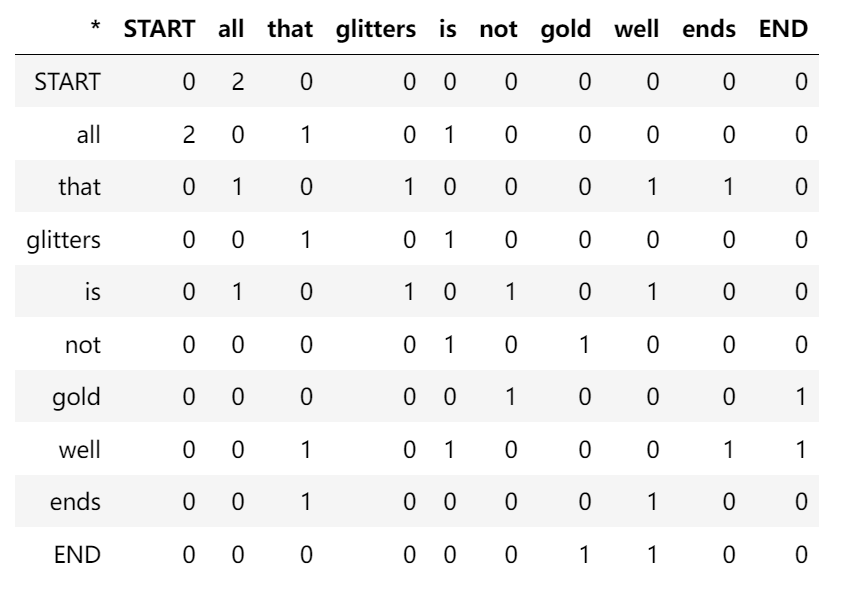
假如,所拥有的语料就两个文档:
文档1: "all that glitters is not gold"
文档2: "all is well that ends well"
|
| 所有的词汇一共10个,假定滑动窗口大小为1,那么就可以构造右侧的矩阵。 |
|
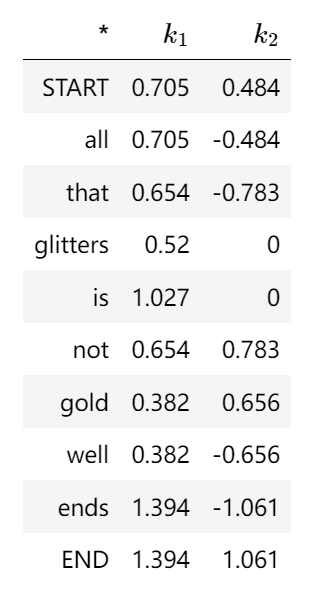
| 然后针对这个10*10(N*N,N为总词汇数)的矩阵进行PCA或者SVD算法进行降维分解,形成k-维的向量,进而最终完成编码。例如start的编码就是[0.705,0.484] |

本章小结
经过编码之后,所有单词对应的编码向量能够反应单词之间的关系。理解和搞清楚Embedding的原理是必须的,它是一切的基石,某种意义也是深度神经网络的灵魂,其实它就是人类所谓的抽象思维。大模型模拟人类解决了将海量的信息进行高效的压缩编码。
Embedding是一种很好的技术与思想,微软和Airbnb已经将它应用到推荐系统。主要参照了把Word Embedding应用到推荐场景的相似度计算中的方法,把每个商品项视为word,把用户行为序列视为一个集合。通过获取商品相似性作为自然语言中的上下文关系,构建神经网描绘商品在隐空间的向量表示。
Airbnb通过Embedding捕获用户的短期兴趣和长期兴趣,即利用用户点击会话和预定会话序列。这里默认浏览点击的房源之间存在强时序关系,即前面查看房源会对影响后面查看房源的印象。通过客户点击或预定方式生成租客类型、房租类型等的Embedding,来获取用户对短期租赁和长期租赁兴趣。
总而言之,Embedding对于时序的场景有着灵活的运用方式,本质上提取时序中前后的关系,进而在N-维的空间中获取内在的联系和逻辑。当然目前为止最出色的还是人脑,对于外界事件的分析、检索和反应几乎在一瞬间完成,而且处于低功耗。















 614
614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









