







--->更多内容,请移步“鲁班秘笈”!!<---
NVIDIA推出了Describe Anything 3B(DAM-3B),一款多模态大语言模型,旨在提供详细的图像和视频本地化描述。配备DAM-3B-Video,该系统接受通过点、边界框、涂鸦或掩码指定区域的输入,并生成具有上下文基础的描述性文本。它兼容静态图像和动态视频输入,且通过Hugging Face提供公开访问。
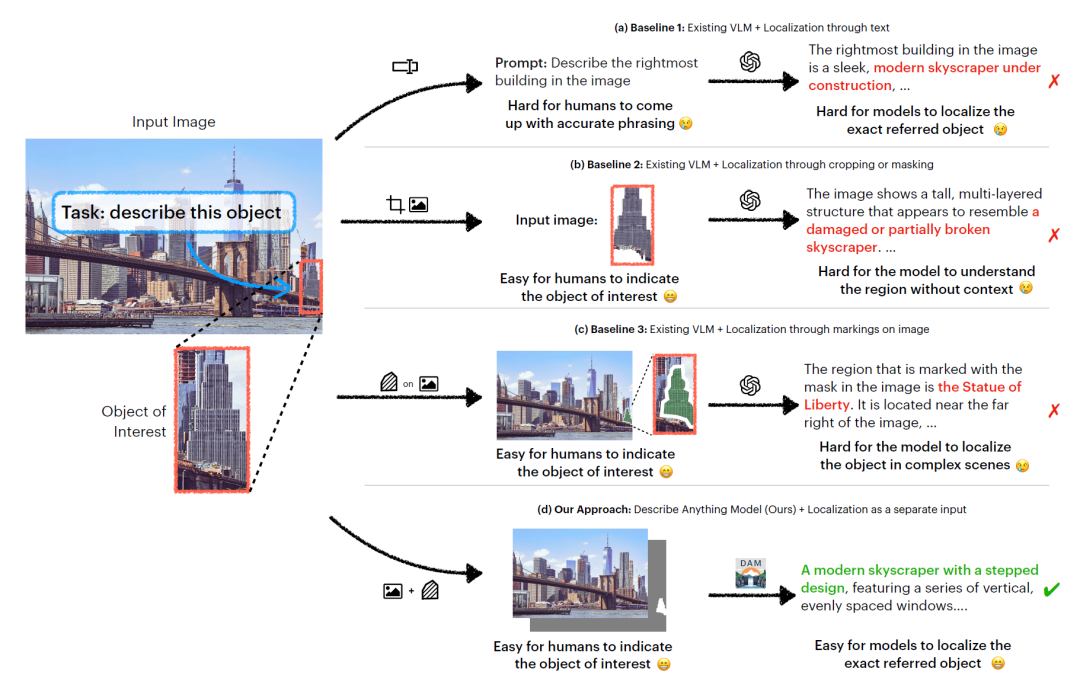
虽然现有的视觉-语言模型(VLMs)在整体图像描述方面取得了很好的成果,但对图像或视频中特定区域进行详细而准确的描述仍然是一个尚未解决的问题。
目前详细描述局部面临的三个主要挑战:
-
区域细节丢失:现有方法通常从全局图像表示中提取局部特征,导致细节丢失,特别是在复杂场景中的小物体。
-
高质量数据集的缺乏:现有数据集如RefCOCOs和Visual Genome通常只提供简短的短语,不足以训练模型生成丰富、详细的描述。
-
基准测试的局限性:现有的评估方法通常使用基于语言的图像描述指标或LLM评分,但这些技术无法很好地适用于详细局部描述任务。
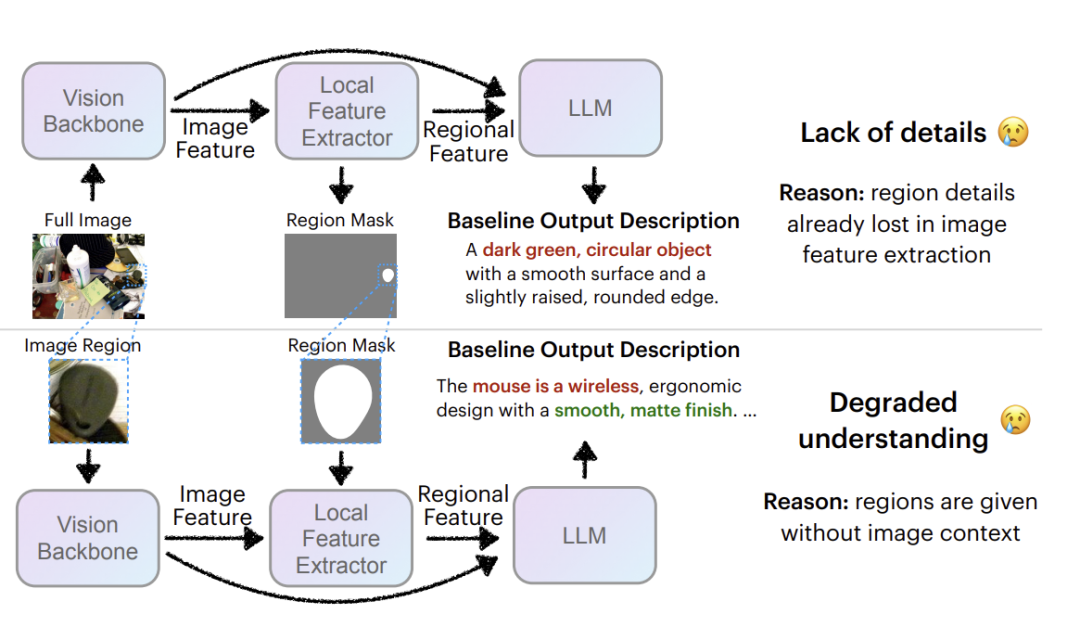
上方:先前的区域描述器从全局图像表示中提取区域特征,导致描述模糊。下方:通过放大(裁剪图像区域)可以增强细节,但会失去上下文线索,降低识别效果。这突显了需要一种设计,既能够编码富含细节的区域特征,同时保持上下文信息,从而提升DLC(区域描述生成)的效果。

整体架构
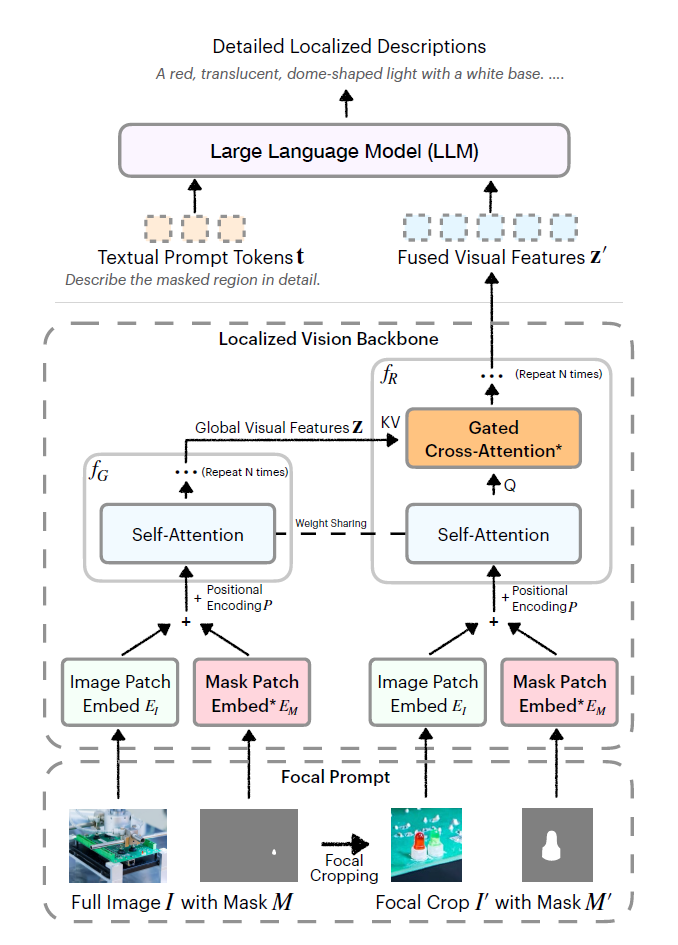
这张图展示了Describe Anything Model的架构设计,它主要用于生成详细的局部图像描述。架构可以从下到上分为几个关键部分:
-
焦点提示 (Focal Prompt)
底部显示输入包括完整图像 (I) 及其掩码 (M),以及经过焦点裁剪的局部图像 (I') 和相应掩码 (M')。焦点裁剪处理将注意力集中在感兴趣的区域,同时保留全局上下文。
-
局部化视觉骨干网络 (Localized Vision Backbone)
这一部分包含两条并行处理路径:
-
全局路径 (左侧):处理完整图像和掩码,将图像块嵌入 (E_I) 和掩码块嵌入 (E_M) 与位置编码 (P) 结合。通过自注意力层 (Self-Attention) 处理,重复N次。
-
生成全局视觉特征 (Z)局部路径 (右侧):处理焦点裁剪的图像和掩码。同样将图像块嵌入和掩码块嵌入与位置编码结合。通过自注意力层处理。
注意两条路径之间有权重共享 (Weight Sharing)融合机制:
通过门控交叉注意力 (Gated Cross-Attention) 将全局视觉特征 (Z) 作为键值 (KV),局部路径输出作为查询 (Q)生成融合的视觉特征 (Z')。
语言生成部分将文本提示标记 (t) 和融合的视觉特征 (Z') 输入大型语言模型 (LLM),LLM生成详细的局部描述,例如:"一个红色的、半透明的、圆顶形灯罩,配有白色底座。..."
这种设计的核心创新在于:
通过焦点提示保留了区域细节,通过局部化视觉骨干网络同时处理全局和局部信息。使用门控交叉注意力有效融合全局上下文和局部细节。最终使LLM能够生成既准确又详细的局部描述。这一架构有效解决了论文中提到的区域细节丢失问题,使模型能够生成高质量的局部描述,即使是针对复杂场景中的小物体。

模型效率
为了解决数据稀缺的问题,NVIDIA 开发DLC-SDP流水线 —— 一种半监督的数据生成策略。这个两阶段流程利用分割数据集和未标注的大规模网页图像,构建包含150万个定位样本的训练语料库。区域描述通过自训练方法进行优化,生成高质量的图像字幕。
在评估方面,团队引入了 DLC-Bench,它基于属性级别的正确性来评估描述质量,而不是与参考字幕的严格比较。

上图展示了DAM模型在各种基准测试中的表现:左表在LVIS和PACO开放类关键词级描述基准测试中,DAM-8B模型分别达到了89.0和84.2的最佳性能,尤其在区分物体和部件的PACO基准测试中表现突出。
中表在Flickr30k Entities零样本短语级数据集上的评估中,DAM模型相比之前的最佳方法平均提升了12.3%。
最后的表格则展示在Ref-L4详细描述数据集上,DAM方法在短描述和长描述语言基准上分别获得了33.4%和13.1%的平均相对提升。
这些结果表明,DAM模型在关键词级、短语级和详细描述级的多个任务中都实现了最先进的性能,证明了其在详细局部描述任务上的有效性。DLC-Bench作为一个新的评估框架,通过使用预定义的正面和负面属性而非仅依赖参考描述,提供了更灵活、更准确的评估方式。
DAM-3B-Video将这一架构扩展到时间序列,通过对每一帧的区域掩码进行编码,并在时间上进行整合。即使在存在遮挡或运动的情况下,也可以为视频生成区域特定的描述。

DLC-Bench
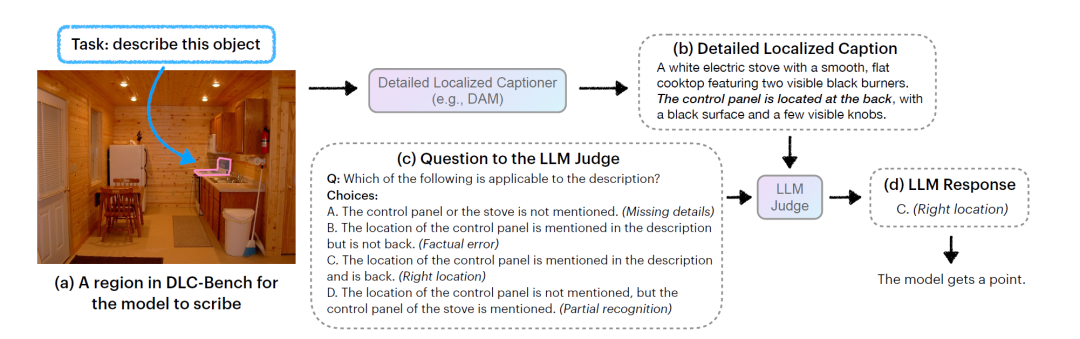
上图展示了DLC-Bench的一个细致定位图像描述任务的评估示例。评估流程首先从提示模型对图像中指定区域进行描述开始(如图 a 所示)。生成的描述不会直接与参考答案比对,而是交由一个文本大语言模型(LLM)担任评审角色,通过回答一系列正向和负向的问题对描述进行质量评分。

b展示了一个具体的模型描述实例。c中的正向问题旨在检测模型是否准确识别了该区域内的关键细节,若模型提供了正确的信息,则可以获得对应的得分;反之,如果描述中存在事实性错误,则会被扣分。图示中加粗的选项 C 表明,评审模型判断该项描述是正确的,因此为该问题加分。
d中则是负向问题的示例,主要用于判断模型是否避免提及图像中并不存在或与目标区域无关的内容。若模型出现了误定位或“幻觉”(即凭空想象的内容),则会被扣分,以减少错误正例的出现。图中加粗的选项B表明,评审模型认为该项描述是合理的,因此模型在该负向问题上也得分。
这种基于问答式的细粒度评分机制,避免了传统方式中对参考答案的刚性依赖,更能真实反映模型在细节理解与区域定位方面的能力。

















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









