






【论文阅读 TPAMI 2021】Topology-Aware Graph Pooling Networks
原文地址:https://arxiv.org/abs/2010.09834
文章目录
摘要
池操作已经被证明在计算机视觉和自然语言处理任务中是有效的。在图数据上执行池化操作的一个挑战是缺乏在图上定义良好的局部性。以往的研究采用全局排序方法对一些重要节点进行抽样,但大多数都不能结合图拓扑。在这项工作中,我们提出了明确考虑图拓扑的拓扑感知池(TAP)层。我们的TAP层是一个两阶段的投票过程,它在图中选择更重要的节点。它首先执行本地投票,通过将每个节点加入到它的邻近节点中来为每个节点生成分数。分数是在本地生成的,这样就可以显式地考虑拓扑信息。在全局投票中加入图拓扑,全局计算每个节点在整个图中的重要度得分。总的来说,每个节点的最终排名得分是通过结合其本地和全局投票得分来计算的。为了提高采样图的连通性,我们建议在排序分数的计算中添加一个图连通性项。在图分类任务上的结果表明,我们的方法取得了比以前的方法更好的性能。
1 引言
池化操作已广泛应用于[1]、[2]、[3]、[4]等各个领域。池化操作可以有效地减少维度大小[1]、[5]和扩大接受域[6]。然而,对图数据执行池化操作是一个挑战。特别是节点[7]、[8]、[9]之间不存在空间局部性信息和顺序信息。有些作品试图通过两种类型来克服这种局限性;它们是节点集群[7],[10]和节点抽样[11],[12]。节点集群方法创建具有超级节点的图。在节点聚类方法中,学习图的邻接矩阵是软连接的。这些方法存在过拟合问题,需要辅助的链路预测任务来稳定训练[7]。top-k pooling[11],[12]等节点抽样方法对图中的节点进行排序,对top-k节点进行抽样,形成抽样图。它使用少量额外的可训练参数,并被证明是更强大的[11]。但是,top-k池化层在计算排名分数时并没有显式地将拓扑信息合并到图中,这可能会导致性能损失。
在这项工作中,我们提出了一种新的拓扑感知池(TAP)层,在计算排名分数时显式编码拓扑信息。我们的TAP层执行两个阶段的投票过程来检查每个节点的本地和全局重要性。我们首先进行局部投票,并使用点积计算每个节点与其相邻节点之间的相似度得分。将节点的平均相似度作为其在局部邻域内的重要度。此外,我们执行全局投票来全局权衡每个节点在整个图中的重要性。每个节点的最终排名得分是其本地和全局投票得分的组合。为了避免TAP层中孤立节点的问题,我们进一步提出了一个图连通性术语来计算节点的排序分数。图连接项使用程度信息作为偏差项,鼓励层选择高连接节点形成采样图。在TAP层的基础上,我们开发了拓扑感知的网络嵌入学习池网络。在图分类任务上的实验结果表明,我们提出的具有TAP层的网络性能始终优于以前的模型。我们的TAP层与基于相同网络架构的其他池化层的比较结果表明,与其他池化方法相比,我们的方法是有效的。
2 背景及相关工作
对图数据的池化操作主要包括两类;它们是节点聚类和节点抽样。DIFFPOOL[7]通过将节点聚类成超级节点来实现图数据池操作。通过学习分配矩阵,DIFFPOOL以指定的概率将每个节点柔和地分配到新图中的不同簇中。这个类别下的池操作保留所有节点信息并将其编码到新图中。这类方法的一个挑战是,它们可能会通过训练另一个网络来学习分配矩阵,从而增加过拟合的风险。此外,新图多为连通图,每个边值代表两个节点之间的连通性强弱。新图的连通性模式可能与原始图有很大的不同。
节点抽样方法主要是选取固定数量的k个最重要的节点组成一个新的图。在SortPool[12]中,使用每个节点的相同特性进行排序,选取该特性中值最大的k个节点组成粗化图。Top-k pooling[11]通过使用一个可训练的投影向量来生成排序分数,该向量将节点的特征向量投影成标量值。选取标量值最大的K个节点组成粗化图。这些方法不包含或只包含少量的额外可训练参数,从而避免了过拟合的风险。但是,这些方法有一个限制,即它们在池过程中不显式地考虑拓扑信息。SortPool和top-k池都依赖于全局投票过程,但不考虑本地拓扑信息。在这项工作中,我们提出了一种池化操作,该操作显式地将拓扑信息编码到排序分数中,从而改进了操作。
3 拓扑感知池层和网络
在这项工作中,我们提出了拓扑感知池(TAP)层,该层将拓扑信息编码为节点选择的排序分数。我们还在排序分数的计算中提出了一个图连通性项,它鼓励粗化图中更好的图连通性。基于我们的TAP层,我们提出了拓扑感知的图表示学习池化网络。
3.1 拓扑感知池化层
3.1.1 通过节点采样的图池化
池化操作对于图像和自然语言处理任务的深度模型具有重要的意义,它可以扩大接收域,降低计算成本。它们是基于局部的操作,从局部区域提取高级特征。在将GNN和GCN推广到图结构数据时,图池化是一个重要而又具有挑战性的课题。最近,提出了两类图池化方法。一种将图池看作是节点聚类问题,另一种将图池看作是节点抽样问题。它们都是为了缩小节点表示的大小并学习新的表示而开发的。形式上,给定一个图G = (A, H),图池化产生一个新的图G’。新图G’可由其邻接矩阵A’和特征矩阵H’表示。在本文中,我们遵循[11],[12],将图池看作一个节点抽样问题,学习原始图G中不同节点的重要性,并对顶部k个重要节点进行抽样,形成新的图G’。现有方法[11],[12]基于全局共享的投影向量生成节点重要性分数,该向量将特征向量投影到标量。每个标量都是一个重要性分数,表示相应节点的重要性。但是,这些方法在执行图池时没有明确考虑图拓扑信息,从而导致网络能力受限。
在本节中,我们提出拓扑感知池化(TAP)层,该层通过考虑图拓扑来执行节点采样。具体来说,节点排序得分通过两个投票过程获得:局部投票和全局投票。对于任意节点,局部投票根据其与邻近节点的相似度计算其重要性,而全局投票则评估其在整个图中的全局重要性。将这两个过程联合学习,对原始图中的所有节点进行排序,然后选取最上面的k个节点组成新的图。
3.1.2 本地池化
对网格类数据的最大池化操作是在本地区域中执行的。受此启发,我们提出了局部投票来度量局部区域内节点的重要性,它明确地结合了图拓扑和局部信息。具体来说,我们计算每个节点与其相邻节点之间的相似度得分。节点i的得分为与其相邻节点相似度得分的平均值。一个节点的结果分数表示该节点与其邻近节点之间的相似性。如果一个节点具有较高的局部投票分数,它就可以高度表示由它和它的邻近节点组成的局部图。形式上,给定邻接矩阵A∈Rn×n,特征矩阵H∈Rn×d的图G = (A, H),其局部投票表示为
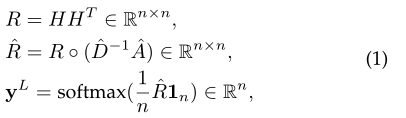
其中ˆA = A + I用于添加自循环,ˆD为对角度矩阵ˆDii = E j(ˆAij),◦表示元素感知矩阵乘法运算,1n∈Rn表示全为1的n维向量,softmax(·)表示元素感知的softmax运算。
设H是一个具有节点特征的矩阵,记为H={h1, h2,···,hn}T。对于节点i,其特征表示为hi∈Rd。我们首先根据节点特征计算相似矩阵R。具体来说,对于任意节点i和节点j,其相似度评分rij由hi和hj的点积得到。由于R包含图中所有节点对的相似度分数,我们在相似度矩阵R和归一化邻接矩阵ˆD−1ˆA之间执行一个元素级矩阵乘法,得到一个矩阵ˆR,其中非连接节点的相似度分数都为零。为此,ˆR中的每个行向量ˆri表示节点i与其邻域之间的相似度得分。接下来,对于节点i,我们平均其所有相似度得分,以表明其在其本地邻居中的重要性。最后应用softmax函数得到最终得分向量,记为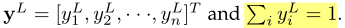
我们提出的局部投票实质上是对来自邻域的局部信息进行编码,并显式地融合了图的拓扑信息。得分较高的节点表明它与相邻节点有更高的相似性,因此往往更重要。通常,通过根据本地信息对每个节点打分,本地投票实现了与对图像进行最大池化操作类似的目标。对类似网格的数据进行最大池化可以保持局部区域内最显著的特性。同样,我们的本地投票规范了本地信息,鼓励在形成新图时选择一个本地区域内最重要的节点。值得注意的是,我们提出的本地投票同时考虑了图拓扑信息和节点特征。利用节点特征计算不同节点之间的紧密度。此外,我们还用内积、级联和高斯函数等方法计算两个向量之间的接近度。在这项工作中,我们选择使用内积,因为它已经被证明是一个简单而有效的解决方案[13]。在实践中,我们可以使用可学习的权重使模型更强大。具体来说,我们可以在计算相互作用矩阵R时加入一个可学习的权值矩阵Wr,使其为
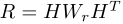
图1展示了我们提议的本地投票操作。

图1所示。对提议的地方选举的说明。这个图包含4个节点,每个节点有2个特性。给定输入图,我们首先计算每对连接节点之间的相似度得分。在图(b)中,我们用两端节点的相似度评分来标记每条边。然后将每个节点与相邻节点的相似度均值化,计算出每个节点的局部投票得分。在图©中,我们用节点的本地投票分数来标记每个节点,节点越大,得分越高。
3.1.3 全局投票
对于每个节点,本地投票实质上显示了它在本地区域中的“本地”角色。然而,与图像等网格数据不同的是,图内的局部邻域是“重叠的”。我们不能仅仅依靠局部显著特征来进行图池化。在本节中,我们将介绍我们提议的全局投票,以评估每个节点的“全局”角色。直观地说,局部投票显示其邻域内节点的重要性,而全局投票显示其邻域(包括自身)在整个图中的重要性。通常,节点的邻居区域可以被视为子图,子图的中心就是节点本身。这样的子图也可以携带重要信息。例如,在一个表示蛋白质的图中,原子是节点,键是边。然后子图包含一个原子和它的邻近原子。某些子图可以表示整个蛋白质的重要单位和功能。因此,这些信息应该在图池中捕获。我们建议全球投票来衡量不同子图在整个图中的重要性。在形式上,全球投票表示为
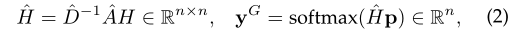
其中p∈Rd是可训练的投影向量,softmax(·)表示元素感知的softmax操作。我们首先聚合每个节点的邻居信息,通过邻居信息,节点的新特征表示子图的信息。然后,我们对结构聚合特征矩阵ˆH进行标量投影p,得到分数向量yG。投影向量p是可学习的,并被图中的所有节点共享。这样,yG中的元素yGi基于全局共享向量表示节点i及其子图的重要性。
注意全局投票的计算类似于最近提出的SortPool[12]和top-k pooling[11]。但是,我们显式地考虑拓扑信息来生成ˆH,而SortPool和top-k pooling可能会忽略这些信息。如果没有拓扑信息,网络的容量会受到限制,子图的功能可能会被忽略。我们提出的全局投票以全局的方式衡量节点的重要性,同时考虑了节点的特征和图的拓扑信息。
3.1.4 图池化层
局部投票衡量每个节点及其邻域之间的局部相似性,而全局投票则捕捉整个图中不同邻域的重要性。总之,我们将这两种方法结合起来测量不同节点的重要性,以便明确地考虑拓扑信息。其中,最终的排序向量y是yL和yG的和。然后基于排序向量y,对原始图中的所有节点进行排序,并对最上面的k个重要节点进行抽样,形成一个新的图。在形式上,我们提出的TAP层可以表示为
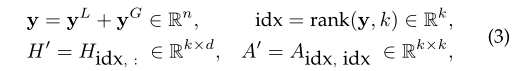
其中k是预定义的数字,表示输出图中节点的个数,rank(y, k)是对节点采样的操作,返回y中top-k值的索引。idx是表示所选节点的索引列表。Hidx,:是特征矩阵上的行感知提取器,用于获取新图的特征矩阵H0。idx根据原始图的节点连接产生新的邻接矩阵。通过排序过程,根据y中的值,只选取top-k的重要节点。然后按照提取过程,得到新的特征矩阵H‘和邻接矩阵A’。值得注意的是,我们的TAP层引入了可忽略的附加参数,因为唯一使用的参数包括线性变换矩阵Wr和投影向量p。
3.2 图联通项
我们提出的TAP层通过图中节点之间的相似度分数来计算排序分数,从而考虑图中的拓扑信息。但是,由TAP层生成的粗化图可能存在节点孤立的问题。在稀疏连通图中,一些节点的相邻节点数量非常少,甚至只有它们自己。假设节点i只连接到自己。节点i的本地投票得分是节点与自身的相似度得分,这可能导致节点i的本地投票得分较高,从而在图中产生较高的排名得分。由此产生的图可以是非常疏连的,这完全失去了原来的图结构。在极端情况下,粗化图可能只包含孤立的节点,没有任何连通性。这不可避免地会损害模型的性能。
为了克服TAP层的局限性,并鼓励所选图具有更好的连通性,我们建议在排名分数的计算中添加一个图连通性项。为此,我们将节点的度作为图的连通性指标,并将度值加到图的排序分数中,从而在节点选择时优先选择连接密集的节点。以节点度作为图连通性项,计算节点i的排序得分为
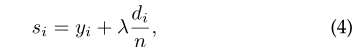
其中yi是节点i在式(3)中获得的排序分数,di是节点i的度,λ是一个超参数,它将图连通项的重要性设置为排序分数的计算。图连接项可以克服TAP层的限制。排序分数的计算现在考虑了节点的度,从而提高了结果图的连通性。一个更好的连通粗化图有望保留更多的图结构信息,从而导致更好的模型性能。
3.3 拓扑感知池化网络
基于我们提出的TAP层,我们构建了一系列网络,称为拓扑感知池化网络(TAPNets),用于图分类任务。在TAPNets中,我们首先应用一个图的嵌入层来产生图中节点的低维表示,这有助于处理一些输入特征向量很高的数据集。这里,我们使用GCN层[14]来嵌入节点。在嵌入层之后,我们将几个块进行堆叠,每个块由GCN层进行高级特征提取,TAP层进行图的粗化。在第i层TAP中,我们使用超参数k(i)来控制采样图中的节点数量。我们将图嵌入层和TAP层的输出特征矩阵输入分类器。
在TAPNets中,我们使用多层感知器作为分类器。我们首先将网络输出转换为一维向量。全局最大和平均池化操作是两种常用的转换方式,可以将特征矩阵的空间大小减小到1。最近,[15]提出使用求和函数来实现很好的性能。在TAPNets中,我们分别使用max、average和sum来连接由全局池化操作产生的转换输出向量。得到的特征向量被送入分类器。图2演示了一个带有两个块的示例TAPNet。

图2所示。拓扑感知池网络的说明。⊕表示特征向量的拼接运算。输入图中的每个节点都包含三个特征。我们使用GCN层将特征向量转换为低维表示。我们堆叠两个块,每个块由一个GCN层和一个TAP层组成。对第一GCN层和T AP层的输出应用全局减少操作(如max-pooling)。得到的特征向量被串联并输入到最终的多层感知器进行预测。
3.4 辅助链路预测目标
多任务学习已经证明在各种机器学习任务中是有效的[7],[16]。它可以在多个相关任务中利用有用的信息,从而导致更好的泛化和性能。在本节中,我们建议使用TAP层的副产品在训练过程中添加一个辅助链接预测目标。在式(1)中,我们计算图中每对节点之间的相似度得分R。通过在R上应用一个元素wise softmax(·),我们可以获得一个链接概率矩阵˜R∈Rn×n,其中每个元素˜rij测量图中节点i和节点j之间链接的可能性。利用邻接矩阵A,计算辅助链路预测损耗为
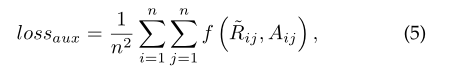
其中f(·,·)是一个损失函数,计算连接概率矩阵˜R和邻接矩阵a之间的距离。
注意,作为链路预测目标的邻接矩阵是直接从原始图导出的。由于TAP层从原始图中提取出一个子图,因此采样图中两个节点之间的连通性与原始图相同。这意味着在更深层次的网络中,邻接矩阵仍然使用原始的图结构。相对于DiffPool[7]中以学习到的邻接矩阵为目标的辅助链路预测,我们的方法使用了原始链路,从而提供了更准确的信息。在4.2节和4.3节的实验研究中也可以清楚地看到这一点。
4 实验研究
在本节中,我们将使用生物信息学和社会网络数据集评估我们在图分类任务中的方法和网络。我们进行消融实验来评估TAP层及其每一项对整体网络性能的贡献。
4.1 实验设置
我们使用社交网络数据集和生物信息学数据集评估我们的方法。除了一些细微的差异外,他们的实验设置是相同的。社交网络中的节点特征是利用节点度的一热编码来创建的。生物信息学中的节点具有分类特征。我们使用3.3节中提出的TAPNet,它由一个GCN层和三个块组成。第一层GCN用于学习图中节点的低维表示。每个块由一个GCN层和一个TAP层组成。所有GCN和TAP层输出48个特征图。我们使用slop为0.01的Leaky ReLU[19]来激活GCN层的输出。网络中的三个TAP层选择的节点数量与图中的节点数量成比例。我们在三个TAP层中分别使用0.8、0.6和0.4的速率。我们使用λ = 0.1来控制图连通性项在排序分数计算中的重要性。将Dropout[20]应用于GCN和TAP层的输入特征矩阵,保持率为0.7。我们使用一个两层前馈网络作为网络分类器。两层输入特征采用保持率为0.8的Dropout。我们在DD, PTC, MUTAG, COLLAB, REDDIT-MULTI5K,和REDDIT-MULTI12K数据集的第一层的输出上使用ReLU激活函数。对于其他数据集,我们使用ELU[21]。我们使用Adam优化器[22]训练我们的网络,学习率为0.001。为了避免过拟合,我们使用L2正则化,λ = 0.0008。所有模型都使用一个NVIDIA GeForce RTX 2080 Ti GPU进行训练。
我们将我们的方法与几个最先进的基线进行比较。Weisfeiler-Lehman子树核(WL)[17]是图表示学习中最有效的核方法。PSCN[18]从邻域学习节点表示,并对图表示使用规范的节点排序。DGCNN[12]应用了多个GCN层,并提出了SortPool,通过对节点进行排序和选择来执行图池。DiffPool[7]是在GraphSage[23]的基础上开发的,提出了一种层次池技术,通过学习执行节点聚类来构建新的图。g-U-Net[11]提出了top-k池,使用一个投影向量计算每个节点的rank得分。计算等级分数时不考虑图拓扑。SAGPool[24]类似于topk池,对拓扑信息进行编码。在SAGPool中没有解决图形连接问题。GIN[15]为图同构网络,其表征能力与WL测试的表征能力相似。特征池[25]是另一种基于图傅里叶变换的节点聚类方法,在进行节点聚类时利用了局部结构。HaarPool[26]利用Haar基和压缩Haar变换生成输入图的稀疏表征,同时保留结构信息。
4.2 社交网络数据集的图分类结果
我们在图分类任务上进行实验,以评估我们提出的方法和TAPNets。我们使用了6个社交网络数据集;这些是COLLAB, IMDB-BINARY, IMDB-MULTI, REDDIT-BINARY, REDDIT-MULTI5K和REDDIT-MULTI12K[27]数据集。注意,从图的大小和图的数量[7]、[15]来看,REDDIT数据集是用于网络嵌入学习的流行的大型数据集。由于社交网络中的节点没有特性,我们通过遵循[15]中的实践来创建节点特性。特别地,我们使用节点度的一热编码作为社交网络数据集中节点的特征向量。在这些数据集上,我们执行10次交叉验证,就像在[12]中一样,其中9次用于训练,1次用于测试。为了保证比较的公平性,我们在这些实验中没有使用辅助链接预测目标。我们将我们的TAPNets与其他最先进的模型在图分类精度方面进行了比较。对比结果见表1。我们可以从结果中观察到,我们的TAPNets在大多数社交网络数据集上的表现显著优于以前的最佳模型,在COLLAB、IMDB-BINARY、IMDBMULTI、REDDIT-BINARY和REDDIT-MULTI12K数据集上的表现分别为4.3%、4.8%、3.9%、2.2%和2.3%。特别是在像REDDIT这样的大型数据集上,这证明了我们方法的有效性。请注意,在gU-Net[11]上的卓越性能表明,与使用top-k池化层相比,我们的TAP层可以生成更好的粗化图。

4.3 生物信息学数据集的图分类结果
为了充分评价我们的方法,我们在4个生物信息学数据集上进行了图分类任务实验;包括DD[28]、PTC[29]、MUTAG[30]和PROTEINS[31][15]数据集。值得注意的是,生物信息学数据集中的节点具有分类特征。在这些实验中,我们没有使用辅助链路预测目标。在不使用损失函数中的辅助链接预测项的情况下,我们比较了我们的TAPNets与其他最先进的模型在图分类精度方面的差异。对比结果汇总于表2。从结果可以看出,我们的TAPNets在DD、PTC、MUTAG和PROTEINS数据集上分别取得了2.2%、8.7%、3.8%和0.4%的显著优于其他模型的结果。值得注意的是,一些生物信息学数据集,如PTC和MUTAG,在图的数量和图中节点的数量上远远小于社交网络数据集。在这些小数据集上的实验结果表明,我们的方法可以在不存在过拟合风险的情况下取得良好的泛化效果。此外,在DD和蛋白质数据集上优于SAGPool的性能表明,我们的方法可以更好地捕获拓扑信息。

4.4 与其他图池层的比较
有人可能会说,我们的TAPNets通过使用更好的网络实现了有前途的结果。在本节中,我们在相同的TAPNet架构上进行实验,以比较我们的TAP层与其他图池层;这些是DIFFPOOL, SortPool和top-k池层。我们使用TAPNet架构来表示网络,同时分别将这些池层用作Netdiff、Netsort和Nettop-k。我们在PTC、IMDB-MULTI和REDDITBINARY数据集上对它们进行评估,并将结果汇总在表3中。请注意,这些模型使用相同的实验设置,以确保公平的比较。结果表明,与使用相同网络架构的其他池化层相比,我们提出的TAP层具有更优越的性能。

4.5 消融实验
在本节中,我们研究了TAP层及其各组成部分在排名分数计算中的贡献;它们是本地投票项(LV)、全球投票项(GV)和图连接项(GCT)。我们从TAPNet中删除TAP层,我们称其为带TAP的TAPNet。为了探究术语在排名分数计算中的作用,我们分别从TAPNets的所有TAP层中移除lv、GVs和GCTs。我们将结果模型分别表示为TAPNet w/o LV、TAPNet w/o GV和TAPNet w/o GCT。此外,我们在训练中增加了3.4节所述的辅助环节预测目标。我们将使用辅助培训目标的TAPNet表示为TAPNet w AUX。我们在三个数据集上评估这些模型;这些是PTC, IMDB-MULTI和REDDIT-BINARY数据集。
这些数据集的比较结果汇总于表4。结果显示,TAPNets在PTC、IMDB-MULTI和REDDIT-BINARY数据集上的表现分别比不使用TAP的TAPNets高出2.8%、4.1%和3.5%。TAPNet比带SST的TAPNet和带GCT的TAPNet更好的结果显示了lv、GVs和GCT对性能的贡献。可以看出,TAPNet w AUX比TAPNet取得了更好的性能,这表明了辅助链路预测目标的有效性。为了充分研究GCT对TAP层的影响,我们将不使用GCT的TAP和TAP生成的粗化图可视化(记为带GCT的TAP)。我们从PTC数据集中选择一个图,并在图3中说明结果图。从图中我们可以看出,TAP比带GCT的TAP有更好的连通图。

4.6 TAP参数研究
由于TAP层采用线性变换来计算排名分数,它涉及到整个网络额外的可训练参数。在这里,我们通过实验研究TAPNet中的参数数量。我们以两种方式从TAP层中移除额外的可训练参数;即从TAPNet中删除TAP层,并从TAP层中删除LV和GV相似性得分项。我们分别将产生的两个网络表示为TAPNet w/o TAP和TAPNet w/o LV&GV。表5总结了在REDDIT-BINARY数据集上的比较结果。从结果可以看出,TAP层只需要额外的2.29%的可训练参数。我们认为,额外参数的微不足道的使用不会增加过拟合的风险,但可以带来3.6%和3.1%的性能提高TAPNet无TAP和TAPNet无LV&GV在REDDIT-BINARY数据集。此外,表2中TAPNets在PTC和MUTAG等小数据集上的良好性能表明,TAP层不会显著增加可训练参数的数量,也不会导致过拟合问题。

4.7 λ的性能研究
在3.2节中,我们提出将图连通性项加入到排序分数的计算中,以提高粗化图的图连通性。可以看出,λ是TAP层中一个有影响的超参数。在这一部分,我们研究了不同的λ值对网络性能的影响。我们从0.01、0.1、1.0、10.0和100.0的范围内选择不同的λ值,以覆盖一个合理的取值范围。我们在PTC、IMDB-MULTI和REDDIT-BINARY数据集上使用不同的λ值来评估TAPNets。
结果如图4所示。我们可以观察到,在三种数据集上,λ = 0.1的性能都是最好的。当λ变大时,TAPNet模型的性能下降。这表明,图连通性项是生成合理排名分数的一个加号项,但它不应压倒对排名分数中的拓扑信息进行编码的相似性得分项。

5 总结
在这项工作中,我们提出了一种新的拓扑感知池(TAP)层,它显式编码拓扑信息排序分数。TAP层执行两个阶段的投票过程,包括本地投票和全球投票。局部投票将每个节点分配给相邻节点,并将其与相邻节点的平均相似度作为局部重要度。全局投票采用投影向量计算每个节点的相似度得分作为全局重要度得分。然后,一个节点的最终排名得分是其本地和全局投票得分的组合。基于这些排名分数的节点抽样显式地包含了拓扑信息,从而得到一个更粗化的图。此外,我们建议在排序分数的计算中加入图连通性项,以克服TAP层可能存在的孤立问题。在TAP层的基础上,我们开发了拓扑感知池化网络(TAPNets)用于网络表示学习。我们加入一个辅助的链路预测目标,利用TAP层中生成的相似度分数矩阵来训练我们的网络。利用生物信息学和社交网络数据集对图分类任务进行的实验结果表明,我们的TAPNets与以前的模型相比实现了性能改进。消融研究表明我们的TAP层对网络性能的贡献。















 1086
1086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









