






AE
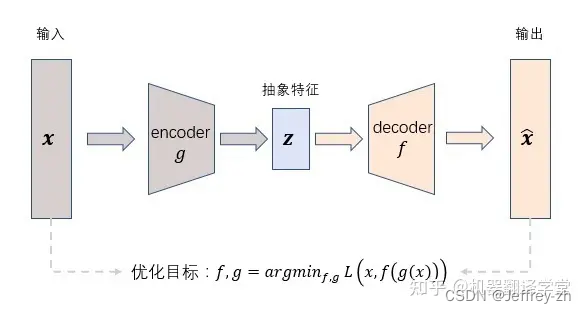
- 无监督训练的方式,对于输入的x经过一个Encoder层后得到一个特征向量z
- 再将该向量 z通过一个Decoder层得到最终输出 x’,通过最小化重构模型的输入x和模型的输出x’
的误差来训练一个好的低维特征向量z - 缺点:模型在训练的时候并没有显性对中间变量的z分布进行建模P(z),在模型训练时所采用的f(z)是有限的
- 在全月和半月中采样一个点,大概率得到不能够生成有效图片的点。因为模型没有很好的建模z空间外的点
VAE:Auto-Encoding Variational Bayes
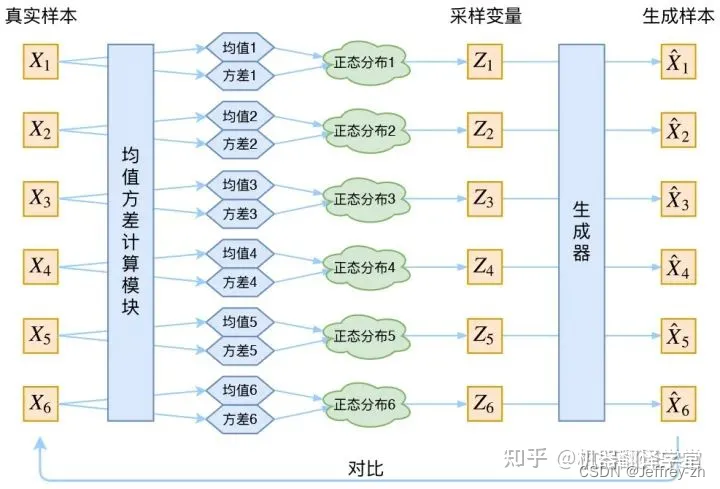
- Encoder模块获得对于该样本的均值和方差,即对于每一个xi而言,获取其对应的分布zi
- 给定Z一个简单的分布,从这个分布中采样得到zi送给生成器
VQ-VAE:Neural Discrete Representation Learning
- 样本的分布P(z)并不是很好学,VQ-VAE就使用了一个codebook去替代了VAE中学习样本分布的过程,我们假设codebook是KxD维的,其中K是指codebook的长度,一般设定为8192维,而D则是每一维向量的长度,一般设为512
- codebook的长度可以简单的理解为codebook对应于k个聚类中心
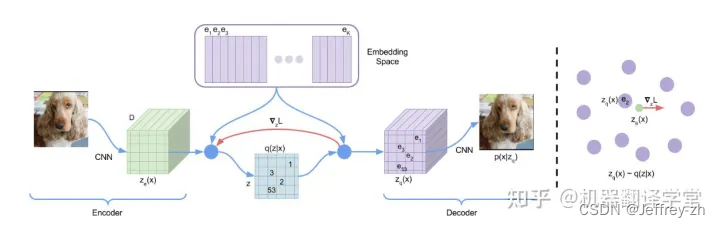
- 流程:
- 将图片送入encoder提取特征图HxWxD
- 将特征图每一个像素点的向量与codebook作比较将codebook中与之最相似的向量ei的索引i存入HxW的特征矩阵q(z|x)中
- 将特征矩阵中的每个index用ei来表示得到新的feature map—zq(x),维度为HxWxD
- 该特征图作为Decoder的输入,最终通过Decoder得到重构后的图片
- 损失函数:
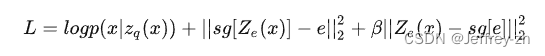
1.第一部分为重构损失,将原本能够正常计算出来的codebook身上的梯度dL/dzq直接作为Encoder的梯度;仅用这个reconstruction loss就实现了Encoder、Decoder一起进行训练
- 第二部分用来训练codebook,最小化ze(x)和embedding e之间的距离。公式中sg表示stopgradient operator,即在前向计算的时候保持相应的量不变,但在后向计算的时候使得梯度为0
- 第三部分训练模型的Encoder部分,目的是为了让Encoder的输出稳定在一个codebook聚类,而不是在codebook内乱跳

















 2313
2313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









