






本文学习资料与代码来源:datawhalechina
1. 线性回归
- 用sklearn 训练数据
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
%matplotlib inline
lr=LinearRegression(fit_intercept=True)
lr.fit(x,y)
print("估计的参数值为:",lr.coef_)
print('R2:',lr.score(x,y))
x_test = np.array([2,4,5]).reshape(1,-1)
y_hat=lr.predict(x_test)
print("预测值为:",y_hat)
#估计的参数值为: [ 4.2 5.7 10.8]
#R2: 1.0
#预测值为: [85.2]
- 最小二乘法矩阵求解
class LR_LS():
def __init__(self):
self.w=None
def fit(self,X,y):
self.w=np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)
def predict(self,X):
y_pred=X.dot(self.w)
return y_pred
#if __name__ == '__main__'的意思是:当.py文件被直接运行时,
#if __name__ == '__main__'之下的代码块将被运行;
#当.py文件以模块形式被导入时,if __name__ == '__main__'之下的代码块不被运行。"""
if __name__=="__main__":
lr_ls=LR_LS()
lr_ls.fit(x,y)
print("估计的参数值:", lr_ls.w)
x_test=np.array([2,4,5]).reshape(1,-1)
print("预测值为:",lr_ls.predict(x_test))
#估计的参数值: [ 4.2 5.7 10.8]
#预测值为: [85.2]
- 梯度下降法
class LR_GD():
def __init__(self):
self.w=None
def fit(self,X,y,alpha=0.02,loss=1e-10):
y=y.reshape(-1,1)
[m,d]=np.shape(X)
self.w=np.zeros((d))
tol=1e5
while tol>loss:
h_f=X.dot(self.w).reshape(-1,1)
theta=self.w+alpha*np.mean(X*(y-h_y),axis=0)
tol=np.sum(np.abs(theta-self.w))
self.w=theta
def predict(self,X):
y_pred=X.dot(self.w)
return y_pred
if __name__=="main":
lr.gd=LR_GD()
lr_gd.fit(x,y)
print("估计的参数值为:",lr_gd.w)
x_test=np.array([2,4,5]).reshape(1,-1)
print("预测值为:",lr_gd.predict(x_test))
2. 朴素贝叶斯分类器

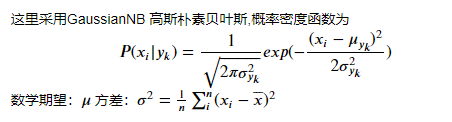
class sklearn.naive_bayes.GaussianNB(priors=None)
参数:
priors:先验概率大小,如果没有给定,模型则根据样本数据自己计算(利用极大似然法)。
var_smoothing:可选参数,所有特征的最大方差
属性:
class_prior_:每个样本的概率
class_count:每个类别的样本数量
classes_:分类器已知的标签类型
theta_:每个类别中每个特征的均值
sigma_:每个类别中每个特征的方差
epsilon_:方差的绝对加值方法
# 贝叶斯的方法和其他模型的方法一致。
fit(X,Y):在数据集(X,Y)上拟合模型。
get_params():获取模型参数。
predict(X):对数据集X进行预测。
predict_log_proba(X):对数据集X预测,得到每个类别的概率对数值。predict_proba(X):对数据集X预测,得到每个类别的概率。
score(X,Y):得到模型在数据集(X,Y)的得分情况。
import math
class NaiveBayes:
def __init__(self):
self.model=None
@staticmethod
def mean(X):
avg=0.0
avg=sum(X)/float(len(X))
return avg
def stdev(self,X):
res=0.0
avg=self.mean(X)
res=math.sqrt(sum([pow(x-avg,2) for x in X])/float(len(X)))
return res
def gaussian_probability(self,x,mean,stdev):
"""根据均值和标准差计算x符合该高斯分布的概率
Parameters:
-----------
x: 输入
mean: 均值
stdev:标准差
Return:
res: float, x符合的概率值
"""
res=0.0
exponent=math.exp(-(math.pow(x-mean,2)/
(2*math.pow(stdev,2))))
res=(1/(math.sqrt(2*math.pi)*stdev))*exponent
return res
def summarize(self,train_data):
summaries=[0.0,0.0]
summaries=[(self.mean(i),self.stdev(i)) for i in zip(*train_data)]
return summaries
def fit(self,X,y):
labels=list(set(y))
data={label:[] for label in labels}
for f,label in zip(X,y):
data[label].append(f)
self.model={
label: self.summarize(value) for label, value in data.items()
}
return 'gaussianNB train done!'
def calculate_probabilities(self, input_data):
"""计算数据在各个高斯分布下的概率
Paramter:
input_data : 输入数据
Return:
probabilities : {label : p}
"""
probabilities={}
for label, value in self.model.items():
probabilities[labels]=1
for i in range(len(value)):
mean, stdev=value[i]
probabilities[label]*=self.gaussian_probability(
input_data[i],mean,stdev)
return probabilities
def predict(self,X_test):
label=sorted(self.calculate_probabilities(X_test).items(),key=lambda x:x[-1])[-1][0]
return label
def score(self,X_test,y_test):
right=0
for X,y in zip(X_test,y_test):
label=self.predict(X)
if label ==y:
right+=1
return right/float(len(X_test))















 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









