






原文链接:https://arxiv.org/pdf/2405.04434
主要贡献(创新点)
在DeepSeek 67B的基础上做了如下改进
(1)提出了MLA(多头潜在注意力机制)
(2)压缩Key-Value对,节省了空间,同时使用解藕RoPE。
(3)提出了DeepSeekMoE架构
摘要
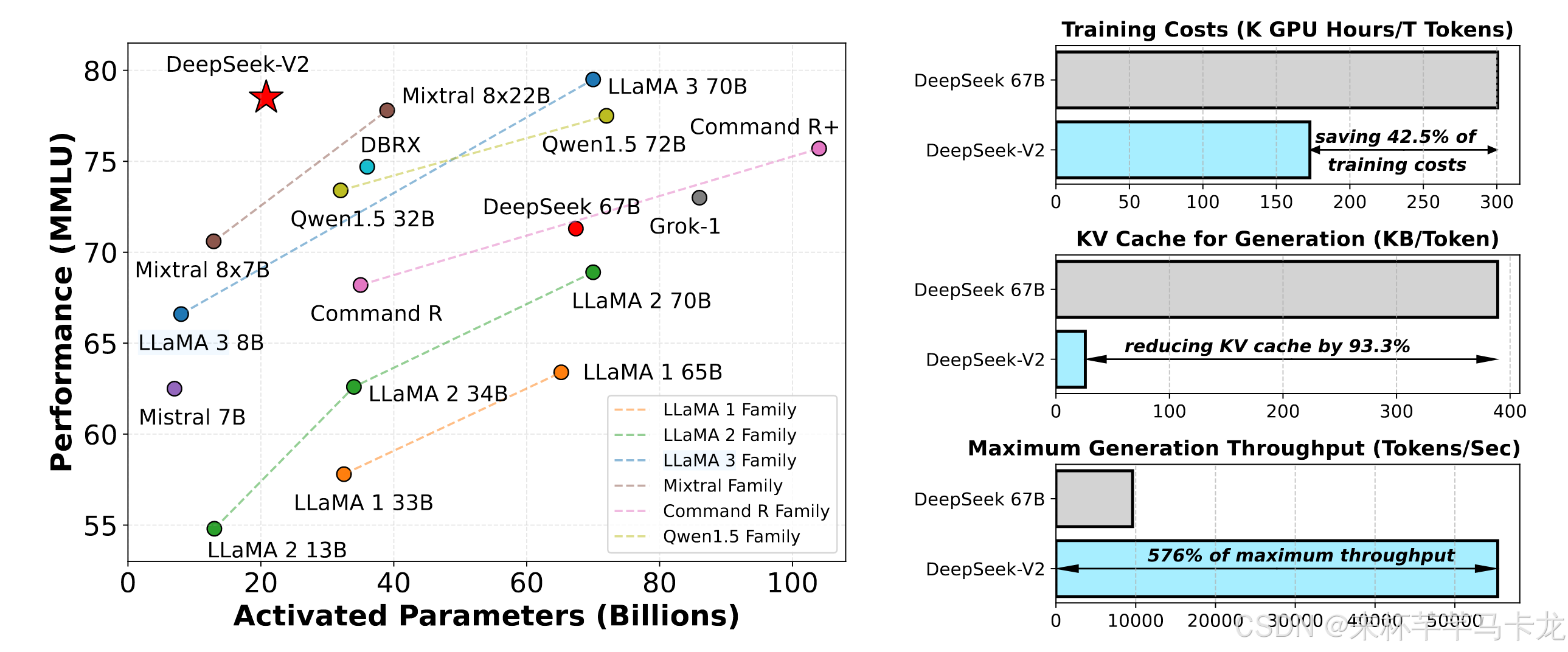
提出了DeepSeek-V2模型,一款高效、经济、强大的MOE语言模型,参数总量为236B,其中21B被任意token激活,上下文长度支持128K个tokens,该模型采用了多头潜在注意力机制Multi-head Latent Attention (MLA)(不同于DeepSeek第一版的GroupedQuery Attention(GQA)机制)以及DeepSeekMoE。MLA保证有效的推理明显地将键值(KV)缓存压缩到潜在的矢量中,而Depeeekmoe可以通过Sparses Computitation以经济的成本来实现强大的模型。相比于67B的DeepSeek,DeepSeek-V2效果更好,同时节省了42.5%的训练开销。即使只激活21B的参数,DeepSeek-V2依旧可以取得非常好的性能。
简介
在Transformer架构上提出了Multi-head Latent Attention (MLA) and DeepSeekMoE。
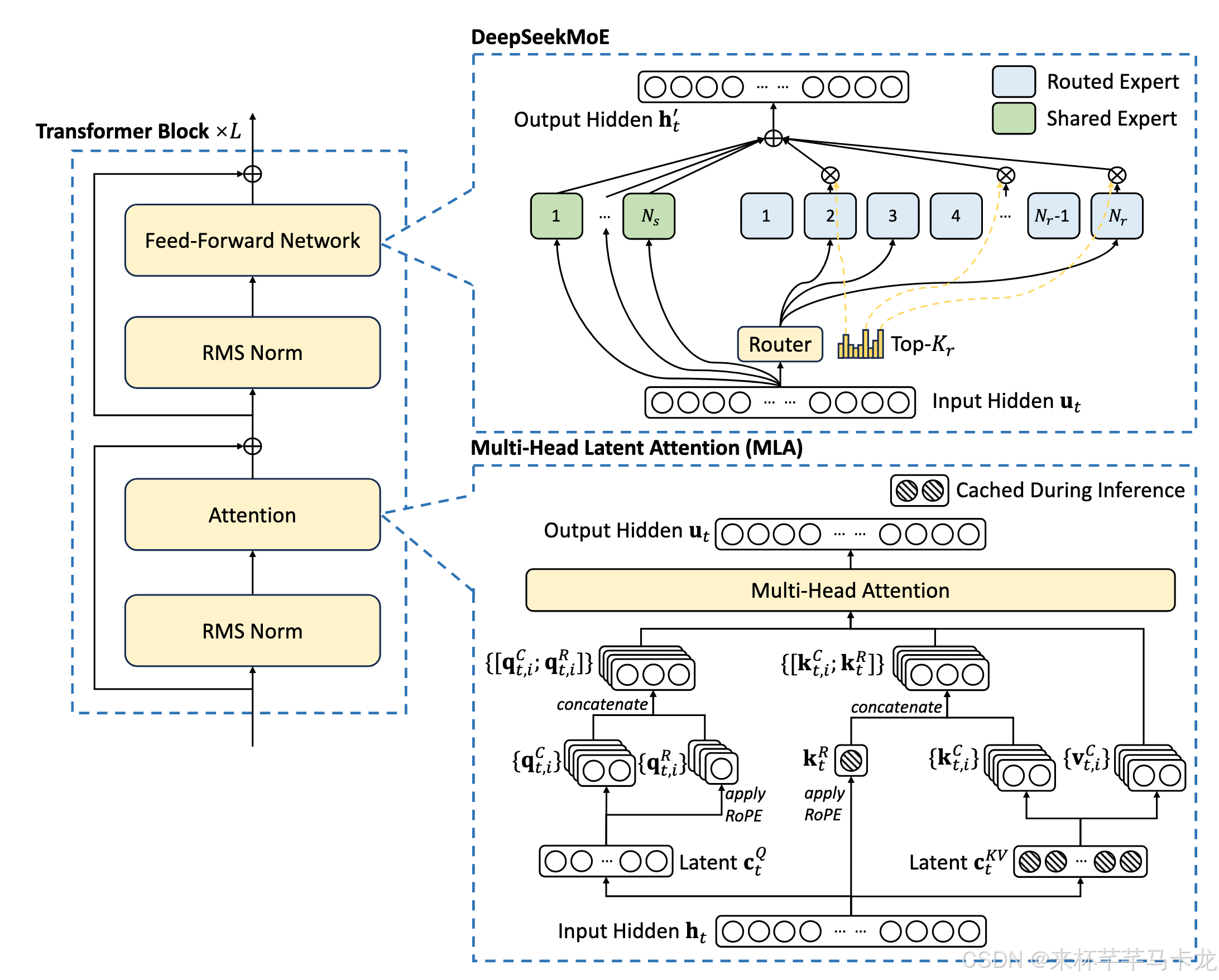
(1)Multi-head Latent Attention (MLA)相比MHA多头注意力,减少了key-value键值对的缓存,并且能捕捉潜在的依赖关系,比MHA、MQA、GQA有更强的表达能力。

(2)对于前馈网络,遵循DeepSeekMoE架构,进行细粒度的专家细分和共享专家隔离来获得专业化领域的更高潜力。通过在训练期间采用专家并行,使用补充机制来控制沟通消耗和负载平衡,DeepSeek-V2具有更强大的性能、更经济的训练成本以及有限的推理吞吐量?
(3)训练及数据。构建了8.1T tokens的来自多种来源的与训练语料库,与DeepSeek 67B预训练的语料库相比,该语料库有更多的数据,特别是中文数据和高质量数据。DeepSeek-V2首先在完整的语料库中进行预训练,之后在收集的150万个对话会话(包含数学、代码、写作、推理、安全等等)中进行监督微调,最后按照DeepSeekMath采用Group Relative Policy Optimization (GRPO)进一步对其模型与人类的行为并且产生了DeepSeek-V2 Chat。并且发布了DeepSeek-V2-Lite,这是一个配备了MLA和DeepSeekMoE的较小的模型,总共有15.7B参数,每个令牌激活2.4B参数。
模型结构
DeepSeek-V2 仍然采用Transformer架构,在注意力机制和FFN前馈网络做出了创新性的改进。
对于注意力机制,设计了MLA(多头潜在注意力机制),利用低秩键值联合压缩来消除推理时的键值缓存瓶颈,从而支持高效的推理。对于 FFN,我们采用了 DeepSeekMoE 架构(Dai 等人,2024年),这是一种高性能的 MoE 架构,可以在经济成本下训练强大的模型。文中没有提到的部分仍然沿用DeepSeek 67B的部分(例如DeepSeek 67B中的RMSNorm归一化以及SwiGLU激活函数)
模型Transformer层数60层,隐藏维度为 5120,注意力头数量为128,每个头维度为128,压缩Key-Value到512维潜在向量,查询query维度为1536,参数总量为236B,其中21B被任意token激活。目标最大上下文长度设置为160K。
多头潜在注意力(MLA)
传统transformer采用MHA多头注意力,但是在生成过程中,其大量的Key-Value cache成为了推理效率的瓶颈,文中提出了MLA多头潜在注意力,在效果不低于MHA的情况下大程度地减少了Key-Value cache的容量。
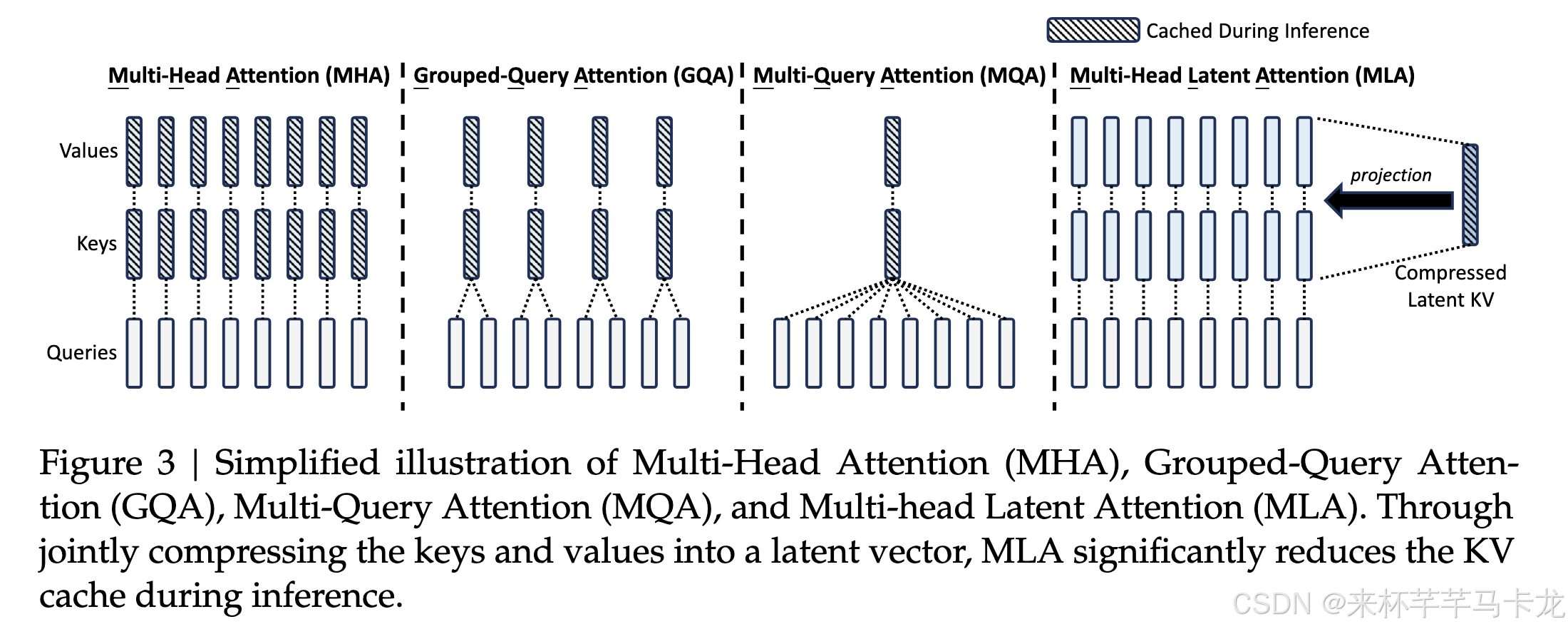
在MLA中,将所有的Key-Value利用其低秩的特性联合压缩到一个潜在的向量中(通过两个低秩矩阵乘积得到大规模高秩的矩阵,只需要存储低秩矩阵),这个潜在的向量纬度dc满足dc << nh*dh(nh代表多头注意力中注意力头的个数,dh代表每个注意力头的纬度)。在DeepSeek 67B 中使用到的Rotary Position Embedding (RoPE)并不适合于这种低秩的压缩Key-Value的方法,所以作者提出了decoupled RoPE策略,将RoPE和注意力机制解藕,使用额外的multi-head queries和共享的key来计算RoPE。

作者在文中提到DeepSeek-V2中MLA的KV消耗大约和GQA中分为2.25组的时候相同,压缩的潜在向量维度为每个注意力头维度的4倍,而用来表示解藕RoPE的queries和key维度为每个注意力头维度的0.5倍。
FFN
基本结构
FFN采用DeepSeekMoE架构,有两个关键思想:(1)将专家细分为更小的粒度以提高专家的专业化程度并且准确地获取知识。(2)隔离一些共享专家以减轻路由专家之间的知识冗余。在激活相同参数量的情况下,DeepSeekMoE相比传统的MoE架构,能过大幅度提高性能。
FNN的输出由输入、共享专家、激活的路由专家来决定,这里贴上论文原文可能更好理解:

设备限制路由
设计了一个受设备限制的路由机制来约束 MoE 相关的通信成本。当使用专家并行时,被路由的专家会被分布在多个设备上。对于每个token,其与 MoE 相关的通信频率与其目标专家所覆盖的设备数量成正比。由于 DeepSeekMoE 中对专家进行了精细划分,激活的专家数量可能很大,因此如果我们应用专家并行,则与 MoE 相关的通信会更加昂贵。对于 DeepSeek-V2,除了对路由专家进行朴素的前 K 选择之外,我们还确保每个token的目标专家将在最多 M 台设备上分布以减少MoE设备间的通信。具体来说,对于每个token,我们首先选择具有最高亲和力分数的 M 台设备中的专家。然后,在这些 M 台设备上的专家中进行前 K 选择。在实践中发现,当 M≥3 时,设备限制路由可以实现与无限制前 K 路由大致相当的性能。
负载均衡的损失辅助
首先,不均衡的负载会增加路由奔溃的风险,并且阻碍一些专家收到充分的训练和利用。其次,在采用专家并行的时候,不均衡的负载会降低计算效率。文中介绍了一种自动学习的路由策略来实现负载均衡,在DeepSeek-V2训练期间,设计了三种辅助损失,分别用来控制专家级负载均衡(LExpBal)、设备级负载均衡(LDevBal)、和通信负载均衡(LCommBal)。

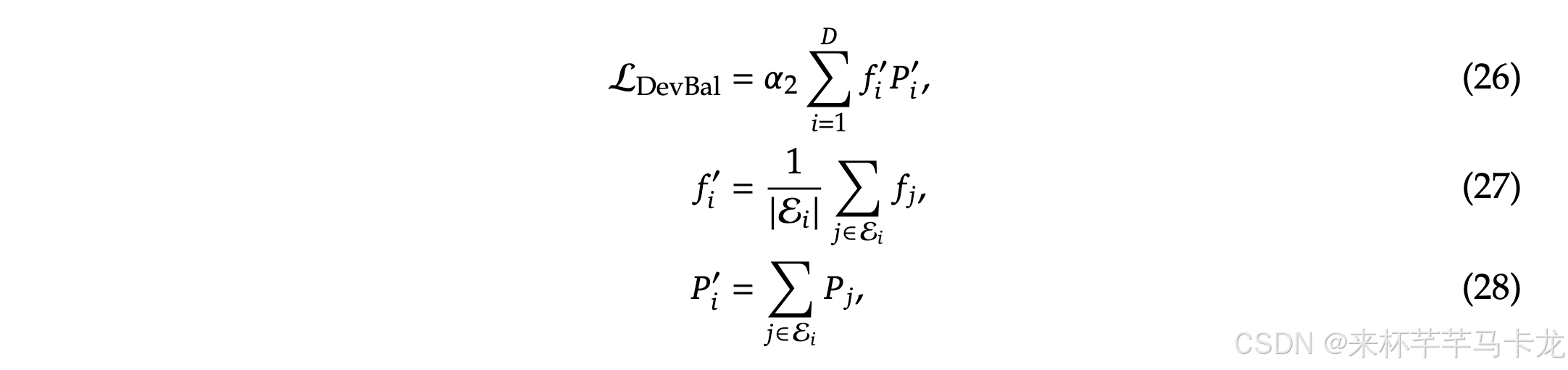

token丢弃策略
虽然平衡损失旨在鼓励负载均衡,但重要的是要认识到它们不能保证严格的负载均衡。为了进一步缓解由不平衡负载引起的计算浪费,在训练过程中引入了设备级别的标记丢弃策略。这种方法首先为每个设备计算平均计算预算,这意味着每个设备的容量因子等于1.0。在每个设备上丢弃具有最低亲和力分数的标记,直到达到计算预算。此外,我们确保属于大约10% 的训练序列的标记永远不会被丢弃。这样,可以根据效率要求灵活地决定在推理期间是否丢弃标记,并始终确保训练和推理之间的一致性。
训练及模型效果
训练数据在DeepSeek-67B的基础上进一步清理了重复数据,恢复了大量误删的数据,同时增加了数据量并提高了数据质量,tokenizer和DeepSeek-67B的相同。DeepSeek-V2为高效部署,参数转化为浮点8位,吞吐量达到了DeepSeek 67B的5.76倍,并且在各项测评任务中取得非常优秀的表现。测试数据较多,详见原文。

















 3038
3038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









