






简介
3月27日凌晨,阿里巴巴发布并开源首个端到端全模态大模型通义千问Qwen2.5-Omni-7B。Qwen2.5-Omni-7B 是一个端到端的多模态模型,旨在感知多种模态,包括文本、图像、音频和视频,同时以流式方式生成文本和自然语音响应。感知四种模态、流式生成文本和语音,太强大了。
核心架构与方法
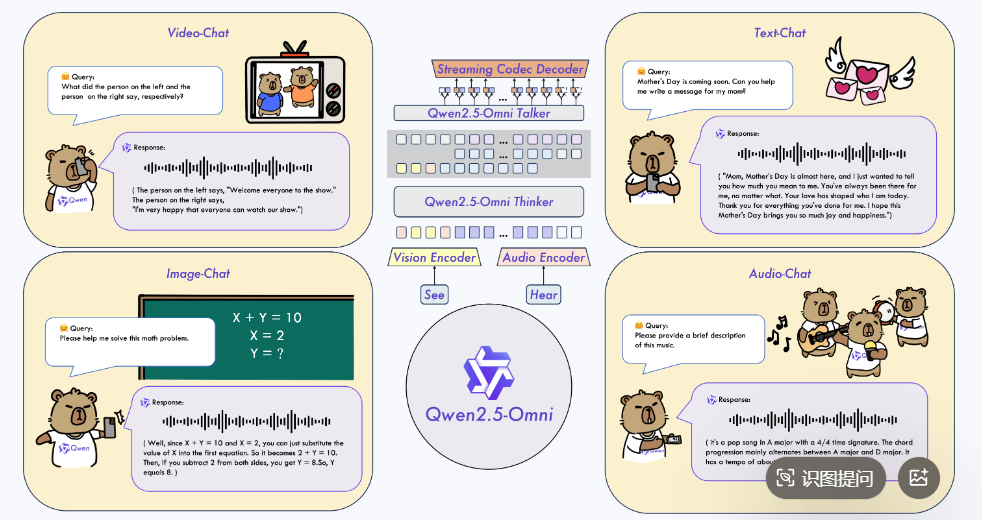
这张图片展示了 Qwen2.5-Omni 多模态模型的不同交互功能,具体如下:
- 中心部分:呈现了 Qwen2.5-Omni 的架构,包含视觉编码器(Vision Encoder)和音频编码器(Audio Encoder)用于感知信息,Qwen2.5-Omni Thinker 进行处理,Qwen2.5-Omni Talker 结合 Streaming Codec Decoder 生成回应,支持语音输出。
- 四种交互场景
- Video-Chat(视频聊天):用户询问视频中左右两人分别说了什么,模型以语音形式回复两人的话语内容。
- Text-Chat(文本聊天):用户请模型帮忙写母亲节留言,模型以文本形式输出一段对母亲表达感恩的话语。
- Image-Chat(图像聊天):用户请求解答黑板上的数学题,模型以语音形式给出解题思路和答案。
- Audio-Chat(音频聊天):用户请模型描述一段音乐,模型以语音形式描述了音乐的调式、节拍、和弦进行和节奏等信息 。
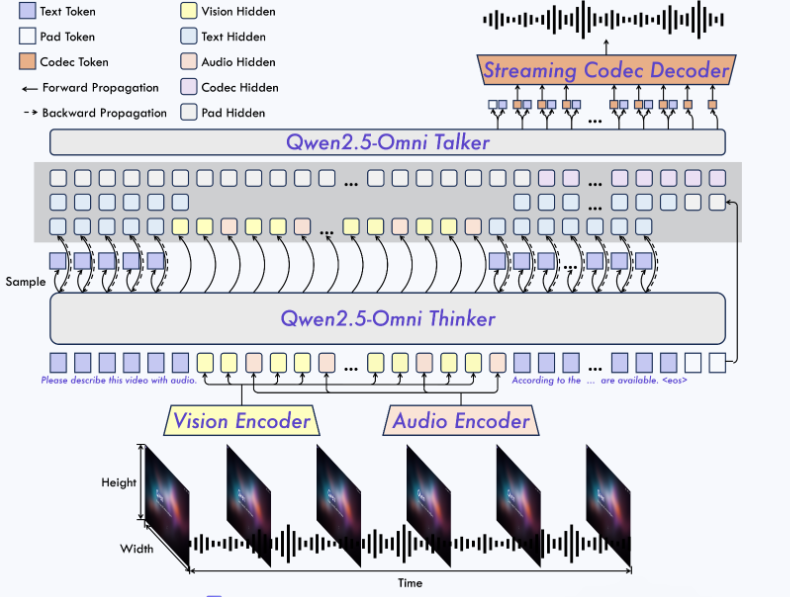
Qwen2.5-Omni 多模态模型的工作架构,具体如下:
- 底部输入层:视觉编码器(Vision Encoder)接收视频画面(以不同帧展示,有高度和宽度维度),音频编码器(Audio Encoder)接收音频信号(以波形展示,有时间维度),同时还可以输入文本(如 “Please describe this video with audio...”)。
- 中间处理层:Qwen2.5-Omni Thinker 处理来自视觉、音频编码器的隐藏状态(分别为 Vision Hidden、Audio Hidden)以及文本隐藏状态(Text Hidden)等信息,图中用不同颜色方块表示各类 token 和隐藏状态,箭头指示数据的前向传播(Forward Propagation)和反向传播(Backward Propagation)方向。
- 顶部输出层:Qwen2.5-Omni Talker 基于中间处理结果,通过 Streaming Codec Decoder 生成音频输出(以波形表示),Codec Token 和 Codec Hidden 也参与这一过程 。 图左上角还有不同颜色方块对应的 token 和隐藏状态的说明。
模型效果
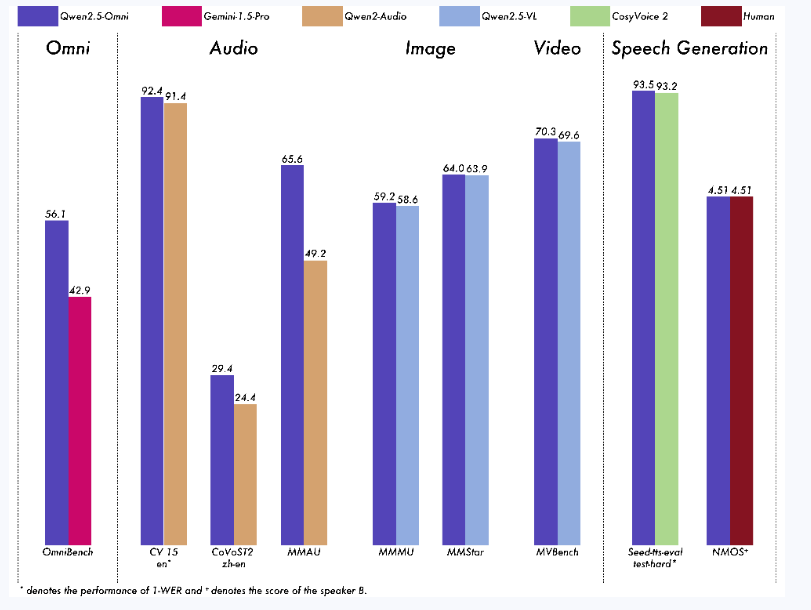
对比了不同模型在多模态各领域的性能表现,具体如下:
- 对比模型:包括 Qwen2.5-Omni、Gemini 1.5-Pro、Qwen2-Audio、Qwen2.5-VL、CosyVoice 2,以及 Human(人类表现)。
- 评估领域:从左到右分别是 Omni(综合多模态,用 OmniBench 评估)、Audio(音频,如 CoVoST2 zh-en 和 MMAU 评估)、Image(图像,如 MMMU 和 MMStar 评估)、Video(视频,用 MVBench 评估)、Speech Generation(语音生成,如 Seed-tts-eval test-hard 和 NMOS 评估)。
- 结果分析:在需要整合多个模态的任务中,如 OmniBench,Qwen2.5-Omni 达到了最先进的性能。在语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU, MMStar)、视频理解(MVBench)和语音生成(Seed-tts-eval 和主观自然度)等方面表现出色。
马上就可以想打电话一样和大模型对话了!!
先去部署到本地体验一下,后续补发效果。

















 96
96

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









