








多模态向量通过统一的数据表示,实现了不同模态数据的搜索和理解,是神经检索和多模态生成式 AI 应用的基石。今天,我们推出了全新的通用多语言多模态向量模型 —— jina-clip-v2。该模型基于 jina-clip-v1 和 jina-embeddings-3 构建,并实现了多项关键改进:
性能提升:v2 在文本-图像和文本-文本检索任务中,性能较 v1 提升了 3%。此外,与 v1 类似,v2 的文本编码器也能高效地应用于多语言长文本密集检索索,其性能可与我们目前最先进的模型 —— 参数量低于 1B 的最佳多语言向量模型
jina-embeddings-v3(基于 MTEB 排行榜)—— 相媲美。多语言支持:以
jina-embeddings-v3作为文本塔,jina-clip-v2支持 89 种语言的多语言图像检索,并在该任务上的性能相比nllb-clip-large-siglip提升了 4%。更高图像分辨率:v2 支持 512x512 像素的输入图像分辨率,相比 v1 的 224x224 有了大幅提升。能够更好地捕捉图像细节,提升特征提取的精度,并更准确地识别细粒度视觉元素。
可变维度输出:
jina-clip-v2引入了俄罗斯套娃表示学习(Matryoshka Representation Learning,MRL)技术,只需设置dimensions参数,即可获取指定维度的向量输出,且在减少存储成本的同时,保持强大的性能。
模型开源链接: https://huggingface.co/jinaai/jina-clip-v2
API 快速上手: https://jina.ai/?sui=&model=jina-clip-v2
模型架构
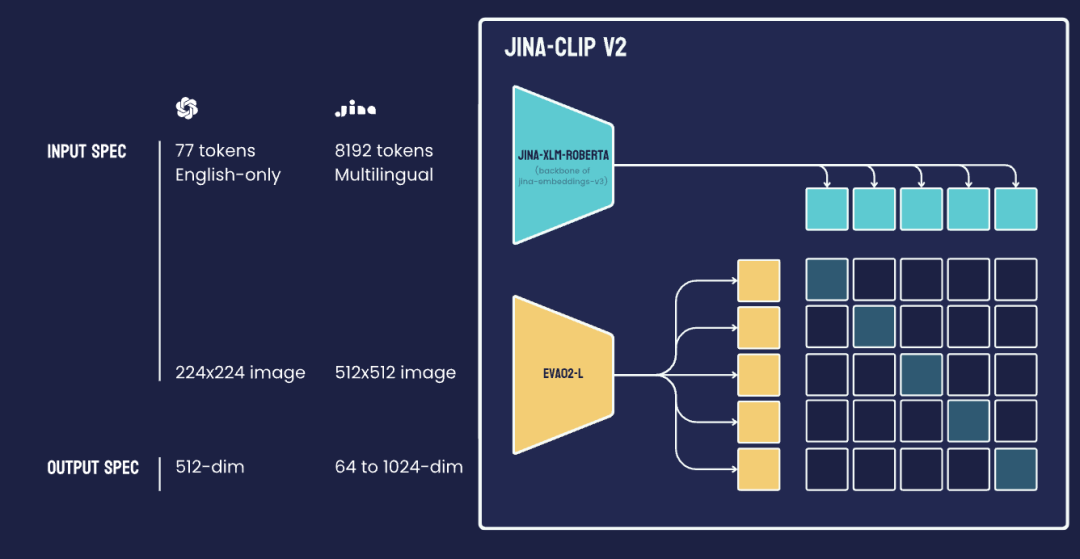
jina-clip-v2 是一个 9 亿参数的类 CLIP 模型,它结合了两个强大的编码器:文本编码器 Jina XLM-RoBERTa(jina-embeddings-v3 的骨干网络)和视觉编码器 EVA02-L14(由 BAAI 开发的高效视觉 Transformer)。这些编码器经过联合训练,生成图像和文本的对齐表示。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









