







论文题目: Improving Language Understanding by Generative Pre-Training
论文地址: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
论文发表于: OpenAI 2018
论文所属单位: OpenAI
论文大体内容:
本文主要提出了GPT(Generative Pre-Training)模型,通过大模型pre-train + 子任务fine-tune的方式,在NLU系列任务中取得收益。
Motivation
相对Word2Vec通读全文的方式,本文的GPT模型另辟蹊径,采用通过上文预测下文的方式,更符合人的方式。
Contribution
①使用半监督学习的方法(大模型pre-train + 子任务fine-tune)进行NLU任务;
②在12个task中的9个,取得state-of-art的成绩;
GPT的参数量是1.17亿个参数;
1. GPT的主体思想是无监督学习NN大模型,然后监督学习对具体任务进行fine-tune;
2. 与Word2Vec不一样的点,这里大模型pre-train用的是前k个word预测当前word,不会使用后面的word;
3. 无监督学习pre-train大模型,这里使用了12层的transformer,优化Loss如下:

4. 监督学习fine-tune,优化Loss如下:

5. 整体Loss使用上面2部分Loss直接线性相加,其中λ=0.5;
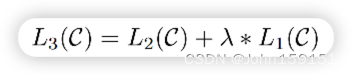
6. 本文发现使用pre-train大模型作为supervise learning的辅助,能够提升泛化性和加速收敛;
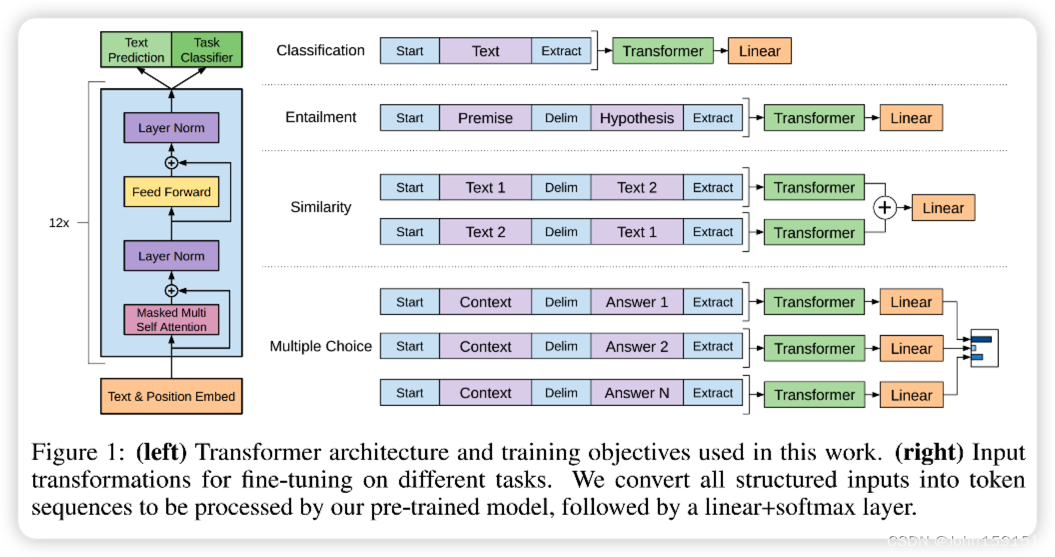
7. 整体的模型架构图如下,激活函数用了GELU[2]:
实验
8. Dataset

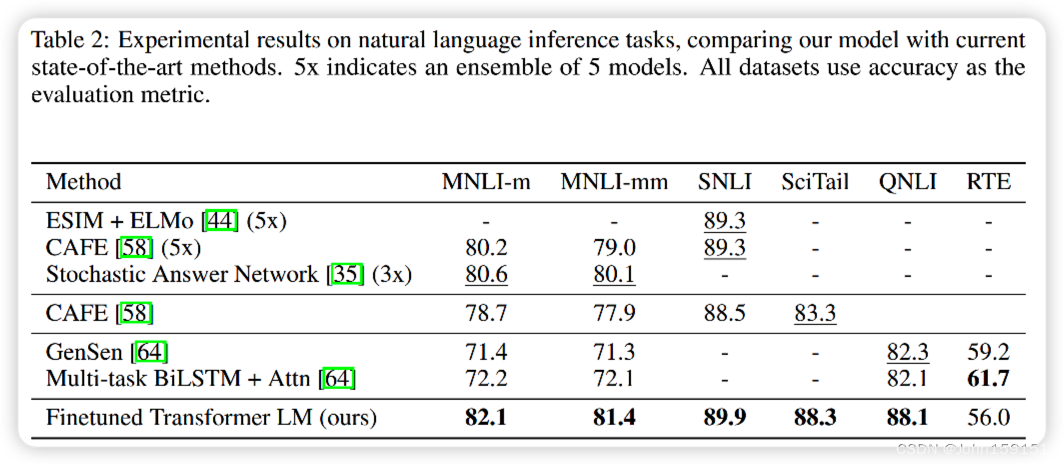
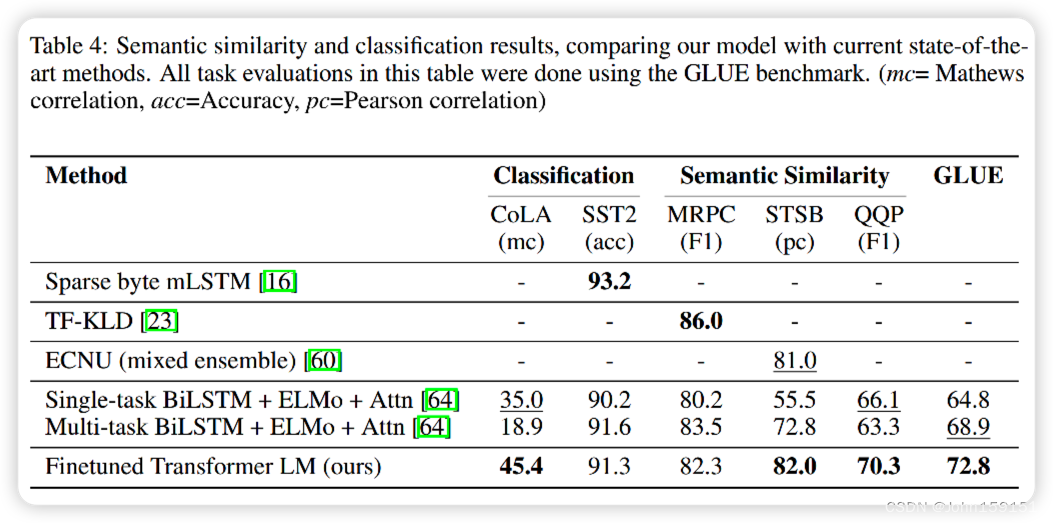
9. 实验结果

参考资料
[1] https://gluebenchmark.com/leaderboard
[2] GELU https://paperswithcode.com/method/gelu
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!















 5269
5269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









