







目录
知识图谱(Knowledge Graph, KG)是人工智能重要分支,知识工程在大数据环境中的成功应用,知识图谱与大数据和深度学习一起,成为推动互联网和人工智能发展的核心驱动力之一。
今天周一,花了一整天查阅和了解了知识图谱(knowledge graph), 想到了运用知识图谱解决我的工程问题,但是从我的图片数据中抽取entity和relationship太难了, 信息抽取太难!
记录一下吧, 放点比较好的资源,大家都来学习知识图谱,下面链接是清华大学计算机科学与技术系教授唐杰率领团队建立的AMiner(有KG年度报告总结和KG最新研究)和北京大学建立的图数据库管理系统(有讲解工程部分,PPT可以下载)。
https://www.aminer.cn/research_report/articlelist?page=1&title=%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1
https://www.bilibili.com/video/BV1iT4y1E7we?from=search&seid=18201555114579424233
下面就贴几张图片,总结今天的学习
一 什么是知识图谱
2012年5月16日, Google发布“知识图谱”的新一代“智能”搜索功能,知识图谱研究热潮高涨
目的:构建知识图谱的目的,就是让机器具备认知能力,理解这个世界
本质:本质上是基于图的语义网络,表示实体和实体之间的关系!
(1)从文本中抽取实体和关系;(2)构建语义网络;(3)分析并从KG网络中获取信息

知识图谱:在数据库系统上利用图谱这种抽象载体表示知识这种认知内容
三元组的基本形式:实体1——关系——实体2
实体——属性——属性值

二 知识图谱的相关技术

知识图谱研究涉及到的技术有:知识工程构建、数据库操作和管理、自然语言处理和机器学习,下面简单介绍涉及到的技术
1 知识图谱与知识工程
- 领域本体的构建:面向特定领域的形式化地对于共享概念体系的明确而又详细的说明
- 知识抽取:从海量的数据中通过信息抽取的方式获取知识
- 知识融合:通过对多个相关知识图谱的对齐、关联和合并,使其称为一个有机的整体,以提供更全面知识
2 知识图谱数据类型
- RDF (Resource Description Framework)定义了一个简单的模型,用于描述资源,属性和值之间的关系。资源是可以用URI标识的所有事物,属性是资源的一个特定的方面或特征,值可以是另一个资源,也可以是字符串。总的来说,一个RDF描述就是一个三元组:<主语、谓词、宾语>。
- RDFs:在RDF数据层的基础上引入模式层,定义类、属性、关系、属性的定义域与值域来描述与约束资源,构建最基本的类层次体系和属性体系,支持简单的上下位推理。
- 本体语言OWL:进一步扩展RDFS词汇,可声明类间互斥关系、属性的传递性等复杂语义,支持基于本体的自动推理,提供了一组合适web传播的描述逻辑的语法,对机器友好,但认知复杂性限制了工程应用。
3 知识抽取

4 知识融合

5 知识图谱与自然语言处理
自然语言处理和知识图谱研究是双向互动的关系

6 知识图谱与数据管理
- 知识图谱本质上是多关系图,通常用“实体”来表达图里的结点、用“关系”来表达图里的边。
- 关系型数据库:实体与实体之间的关系通常都是利用外键来实现,对关系的查询需要大量join操作
- 图数据库:图模型建模实体(结点)和实体之间的关系(边),在对关系的操作上有更高的性能
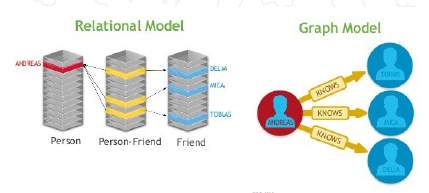
7 知识图谱与机器学习

三 知识图谱的应用行业
1 应用领域

2 医疗领域知识图谱

3 医疗知识图谱构建流程

4 医疗知识图谱Schema

四 金融知识图谱的技术框架和体系结构
1 应用
基于企业的基础信息、投资关系、诉讼、失信等多维度关联数据,利用图计算等方法构建科学、严谨的企业风险评估体系,有效规避潜在的经营风险与资金风险
应用:穿透式多层股权查询、资本系查询、风险评估、客户资源分类管理、信贷前期风险评估、采购企业风险审核、招投标企业资质评级等

2 技术框架

3 体系结构
















 1652
1652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









