







LLMs-入门四:基于LLaMA-Efficient-Tuning对LLMs做微调
- 前言
- 1、前提条件
- 2、【关键命令01】依赖安装LLaMA-Efficient-Tuning
- 3、【关键命令02】进入到LLaMA-Efficient-Tuning目录
- 4、【关键命令03】安装依赖套件
- 5、开始预训练/微调
- 1)介绍微调主要参数
- (1) 参数01【使用GPU】:CUDA_VISIBLE_DEVICES=0
- (2) 参数02【执行】:src/train_bash.py
- (3) 参数03【监督式微调】:--stage sft
- (4) 参数04【模型的名称或者路径】:--model_name_or_path path_to_llama_model
- (5) 参数05【使用的资料集】:--dataset alpaca_gpt4_en
- (6) 如何做自己资料集的训练?
- (7) 【关键命令04】添加资料集到LLaMA-Efficient-Tuning中
- (8) 参数05【修改使用的资料集参数值】:--dataset alpaca_gpt4_en
- (9) 参数06【微调类型】:--finetuning_type lora
- (10) 参数07【输出训练完的模型及相关文件的目录】:--output_dir path_to_sft_checkpoint
- (11) 参数08【运行前覆盖掉cache中的资料集】:--overwrite_cache
- (12) 参数09【每个设备的批次大小】:--per_device_train_batch_size 4
- (13) 参数10【执行优化更新前执行的反向传播的步骤数量】--gradient_accumulation_steps 4
- (14) 参数11【学习率调度器的类型】:--lr_scheduler_type cosine
- (15) 参数12【每多少步做记录】:--logging_steps 10
- (16) 参数13【每多少步保证模型1次】:--save_steps 1000
- (17) 参数14【设定学习率】:--learning_rate 5e-5
- (18) 参数15【训练的epoch次数,根据任务进行调整】:--num_train_epochs 3.0
- (19) 参数16【损失函数曲线】:--plot_loss
- (20) 参数17【半精度浮点数进行训练】:--fp16
- 2)【关键命令05】按需修改后的微调参数
- 3)开始微调训练
上篇地址: https://blog.csdn.net/Josong/article/details/133641423
前言
如何在Colab/JupyterLab等平台中运用自己的资料集微调(fine-tuning) Llama-2-7b 模型呢?
- 源码地址:https://github.com/hiyouga/LLaMA-Efficient-Tuning
1、前提条件
训练Llama 2-7b至少吃的VRAM大概需要24GB,因此低于这个配置将无法进行训练/微调。
1)使用Colab对 Llama 2做微调
Colab地址:https://colab.research.google.com/
当我们基于Colab做微调时,首先需要更该【运行时类型】,更改的位置如下图所示
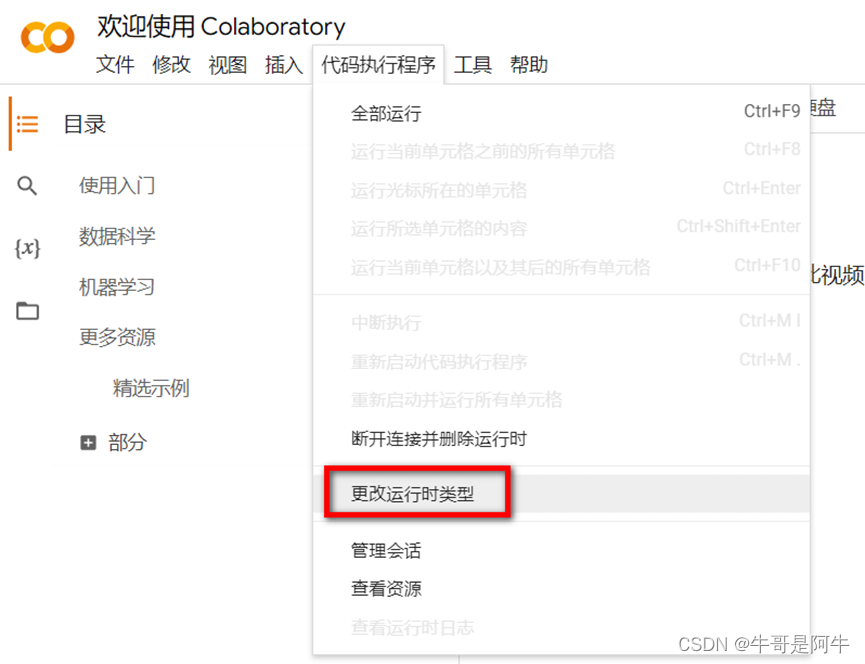
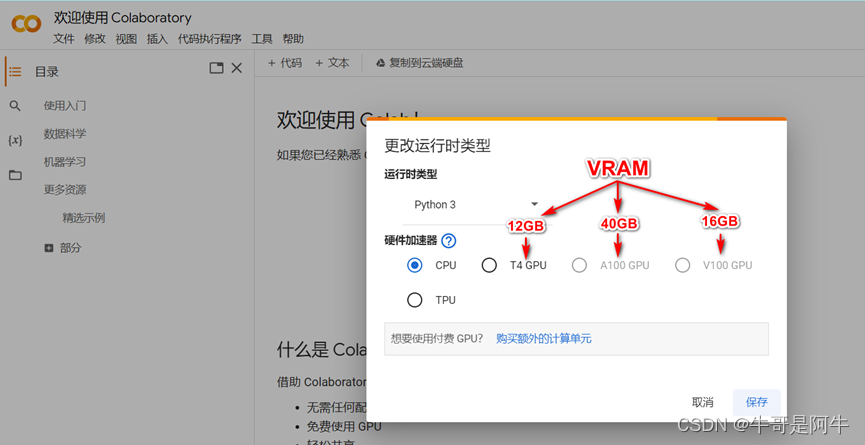
根据前提条件中的说明,要微调Llama-2-7b,需要VRAM > 24GB。因此,我们可以选择的GPU只能是“A100 GPU”。如果使用“A100 GPU”需要购买额外的计算单元,如下图所示
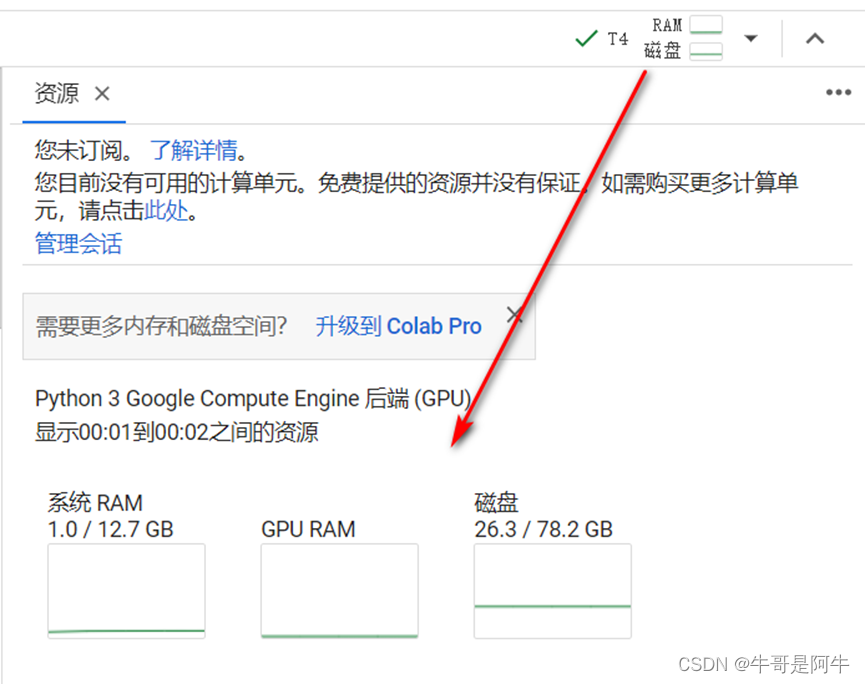
- 如T4 GPU,如下图所示
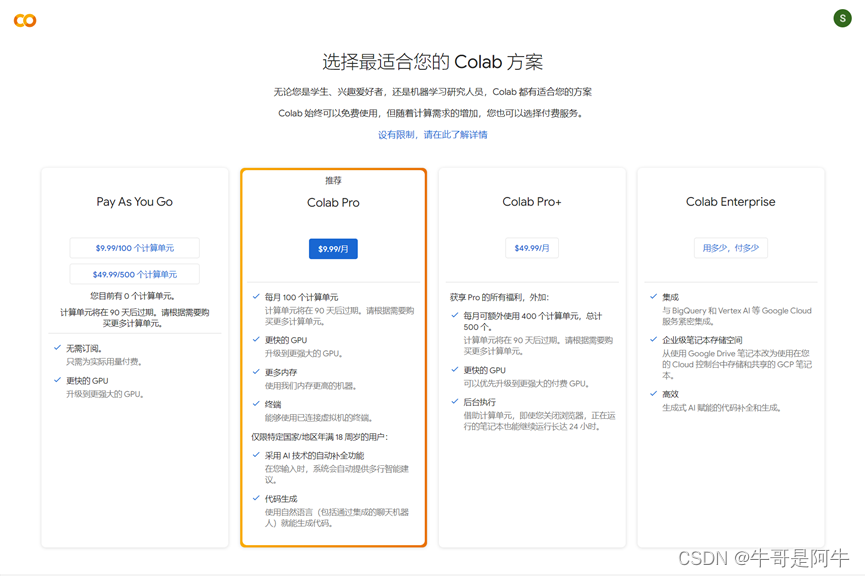
购买额外的计算单元如“Colab Pro”,如下图所示
2)使用JupyterLab对 Llama 2做微调
当我们基于JupyterLab做Llama-2-7b微调时,JupyterLab所部署的物理机GPU需要是RTX3090、RTX4090, A100 or H100 GPUs,并且VRAM > 24GB。
2、【关键命令01】依赖安装LLaMA-Efficient-Tuning
Colab与JupyterLab操作过程、命令基本相同,该文档后续都以Colab为例进行介绍。
! git clone https://github.com/hiyouga/LLaMA-Efficient-Tuning.git
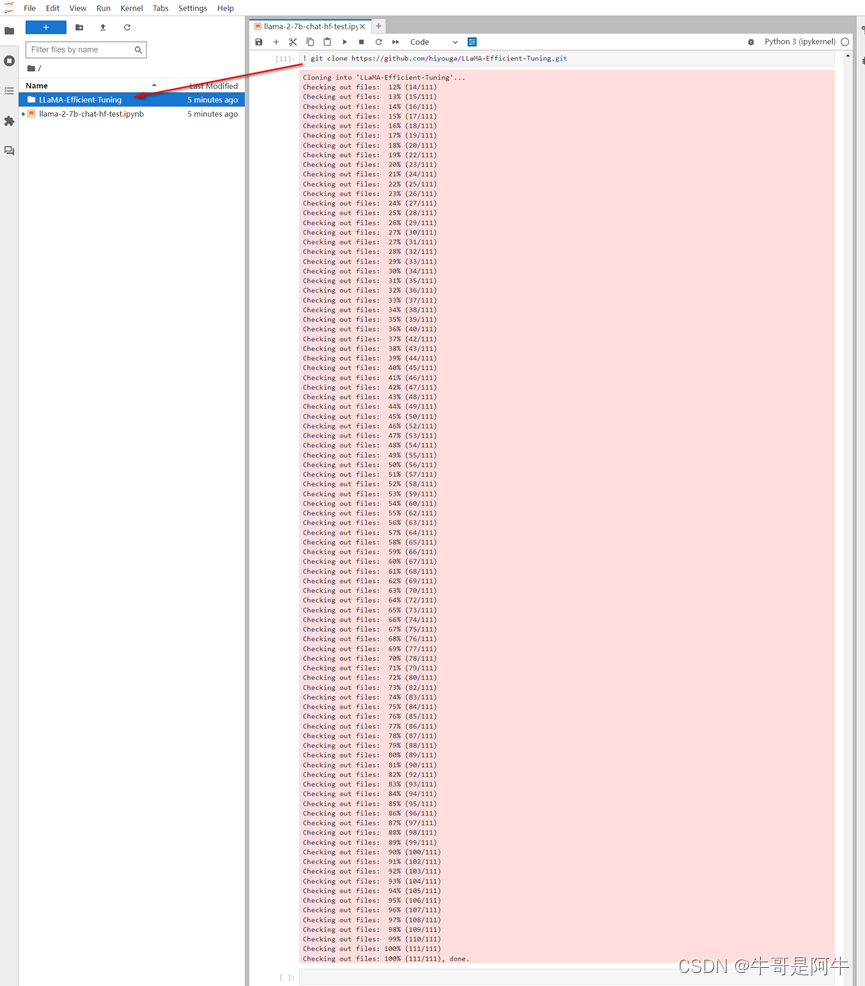
1)Colab安装如图所示
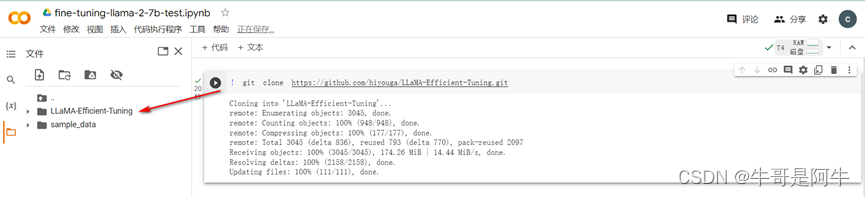
2)JupyterLab安装如图所示
3、【关键命令02】进入到LLaMA-Efficient-Tuning目录
%cd LLaMA-Efficient-Tuning/

4、【关键命令03】安装依赖套件
! pip install -r requirements.txt

5、开始预训练/微调
1)介绍微调主要参数
本文以微调为示例进行介绍。下面先介绍一下微调主要参数的含义
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path path_to_llama_model \
--do_train \
--dataset alpaca_gpt4_en \
--template default \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir path_to_sft_checkpoint \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--fp16
(1) 参数01【使用GPU】:CUDA_VISIBLE_DEVICES=0
(2) 参数02【执行】:src/train_bash.py
表示执行LLaMA-Efficient-Tuning/src目录下的train_bash.py
(3) 参数03【监督式微调】:–stage sft
表示监督式微调,“sft”为Supervised Fine-Tuning的简写
(4) 参数04【模型的名称或者路径】:–model_name_or_path path_to_llama_model
表示模型的名称或者路径,如修改成在部署时所使用的模型“daryl149/llama-2-7b-chat-hf”
(5) 参数05【使用的资料集】:–dataset alpaca_gpt4_en
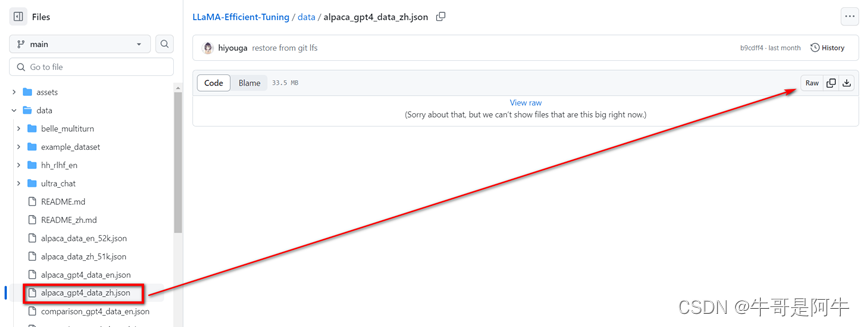
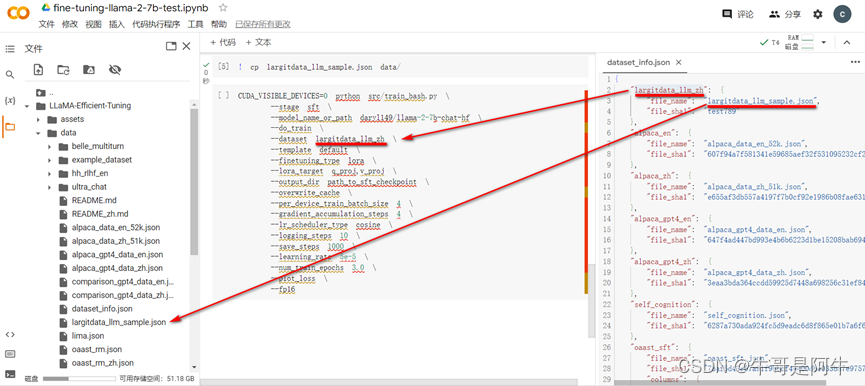
在介绍该参数前先介绍一下LLaMA-Efficient-Tuning/data目录下的“预训练会使用到的一些资料集”,如下图所示,同时如果要看“预训练会使用到的一些资料集”要知道有哪些模型的资料集可以打开“dataset_info.json”
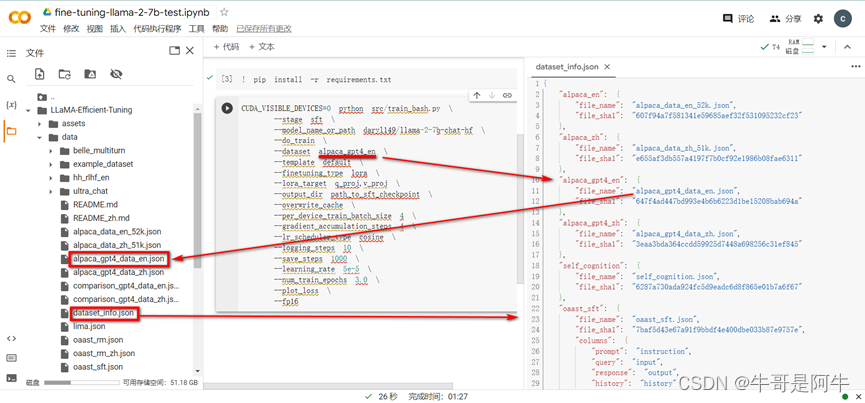
- 图中【alpaca_gpt4_en】对应到右侧“dataset_info.json”中的相同的名称中的“file_name”文件名所对应的左侧LLaMA-Efficient-Tuning/data目录下的“alpaca_gpt4_data_en.json”就是要使用的预训练/微调资料集
- 如果想看“alpaca_gpt4_data_en.json”资料集的内容我们该如何做呢?我们需要到LLaMA-Efficient-Tuning工程github中data目录下找到“alpaca_gpt4_data_en.json”
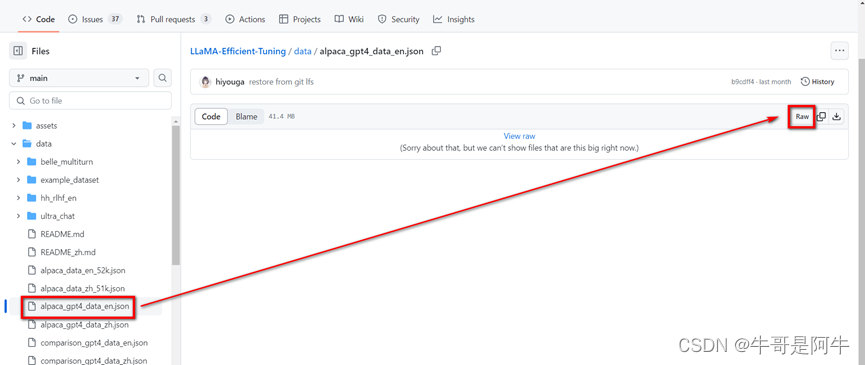
- 点击该json,然后再点击【Raw】查看该资料集的内容,如下图所示

- 在该页面中【instruction】为系统的指令,比如我们在呼叫chatGPT的时候,通常会有一个系统的指令;【input】为使用者的一个输入;【output】就是我们的输出(基于输入的正确答案),在做“sft监督式微调”时通常就是提供这几个参数值。其中,这个【output】可以通过“人工去做这个标记:只是人工去做的话,这个工作量非常的大”,目前比较主流的做法是把大量的问题丢给“chatGPT 3.5或chatGPT 4”,然后使用chatGPT 3.5或chatGPT 4”的答案来做后续【output】的一个标准/结果。
- 除了图中【alpaca_gpt4_en】英文版本的资料,在LLaMA-Efficient-Tuning/data目录下也可以找到对应“中文版本”的资料集【alpaca_gpt4_zh】“alpaca_gpt4_data_zh.json”。该资料集完全是使用对应英文版本的资料集翻译而来。如下图所示

(6) 如何做自己资料集的训练?
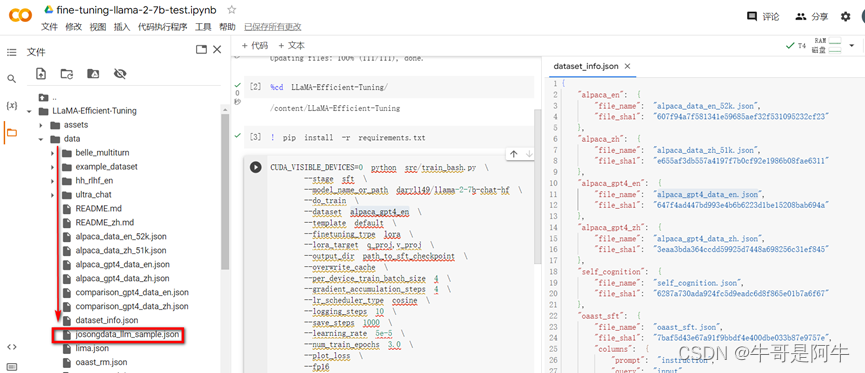
主要是要包含这几个参数【instruction】、【input】、【output】来根据需要打造自己的资料集。我们也可以通过现有的资料集进行改造。我们以通过改造现有的资料集来进行介绍,比如我们将“alpaca_gpt4_data_zh.json”复制出一个新的json,在新的json中选取一部分语料作为新的资料集(比如截取1000多条),然后将该json重新命名为“josongdata_llm_sample.json”。将该资料集放到LLaMA-Efficient-Tuning/data目录下可以通过如下两种方式:
- 本地上传,如下图所示
- github上下载
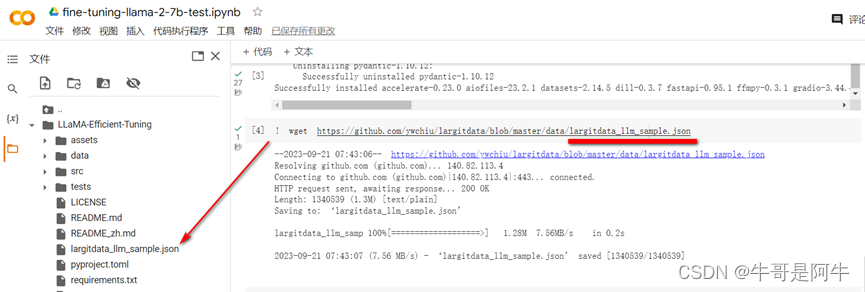
如果新修改的资料集是在github上,我们也可以直接下载到LLaMA-Efficient-Tuning目录中,命令如下所示
! wget https://github.com/ywchiu/largitdata/blob/master/data/largitdata_llm_sample.json
(7) 【关键命令04】添加资料集到LLaMA-Efficient-Tuning中
修改“dataset_info.json”,在该json中添加刚刚下载下来的的资料集相关信息,如下图所示

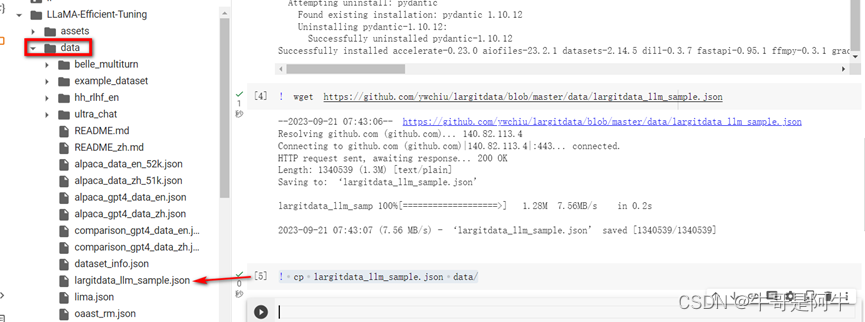
然后将“largitdata_llm_sample.json”从下载的目录复制到data目录下,命令如下:
! cp largitdata_llm_sample.json data/
- 下载的“largitdata_llm_sample.json”如上传的资源附件
(8) 参数05【修改使用的资料集参数值】:–dataset alpaca_gpt4_en
将“alpaca_gpt4_en”修改成刚刚添加到“dataset_info.json”中的信息“largitdata_llm_zh”,如下图所示
(9) 参数06【微调类型】:–finetuning_type lora
lora:可以节省记忆体的使用
(10) 参数07【输出训练完的模型及相关文件的目录】:–output_dir path_to_sft_checkpoint
–output_dir主要是输出训练完的模型及相关文件的目录,也可以储存训练过程中的结果。
可将“path_to_sft_checkpoint”修改成自己定义的名称,如“test_sft_ckpoint”
(11) 参数08【运行前覆盖掉cache中的资料集】:–overwrite_cache
–overwrite_cache我们也可以理解在运行前重写cache
(12) 参数09【每个设备的批次大小】:–per_device_train_batch_size 4
表示每个设备的批次大小设定为4
(13) 参数10【执行优化更新前执行的反向传播的步骤数量】–gradient_accumulation_steps 4
表示在执行优化更新前执行的反向传播的步骤数量为4
(14) 参数11【学习率调度器的类型】:–lr_scheduler_type cosine
表示我们把学习率调度器的类型设置为cosine类型,表示“余弦的一个衰减”
(15) 参数12【每多少步做记录】:–logging_steps 10
表示每10步做一个记录到日志中
(16) 参数13【每多少步保证模型1次】:–save_steps 1000
表示每1000步保存模型1次。因为本文档使用的资料集比较小,所以将1000修改为每10步保存模型1次。
(17) 参数14【设定学习率】:–learning_rate 5e-5
(18) 参数15【训练的epoch次数,根据任务进行调整】:–num_train_epochs 3.0
表示训练epoch(时期、时代)次数为3次。
(19) 参数16【损失函数曲线】:–plot_loss
(20) 参数17【半精度浮点数进行训练】:–fp16
fp16/fp32/fp64所代表的含义:
- 双精度浮点数fp64
- 单精度浮点数fp32
- 半精度浮点数fp16:比较节省计算资源
fp16/fp32/bf16比较: - fp32/fp16 绝大多数硬件都支持,所以可以用混合精度训练提高吞吐;但 bf16/tf32 只有新的硬件才支持,V100/昇腾910等不支持
- bf16 具有和 fp32 相同的 range,但精度(也就是两个最小单位之间的间隔)降低
– bf16/fp32 进行混合精度训练,可以减少溢出几率
– 对于大型 transformer,bf16 损失的精度被证明不怎么影响收敛 - tf32 是 A100 中引入的新格式,用于替代 fp32,也即可以全程 tf32 训练或 bf16/tf32 混合训练
2)【关键命令05】按需修改后的微调参数
! CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path daryl149/llama-2-7b-chat-hf \
--do_train \
--dataset largitdata_llm_zh \
--template default \
--finetuning_type lora \
--lora_target q_proj,v_proj \
--output_dir test_sft_ckpoint \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 10 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--fp16
3)开始微调训练
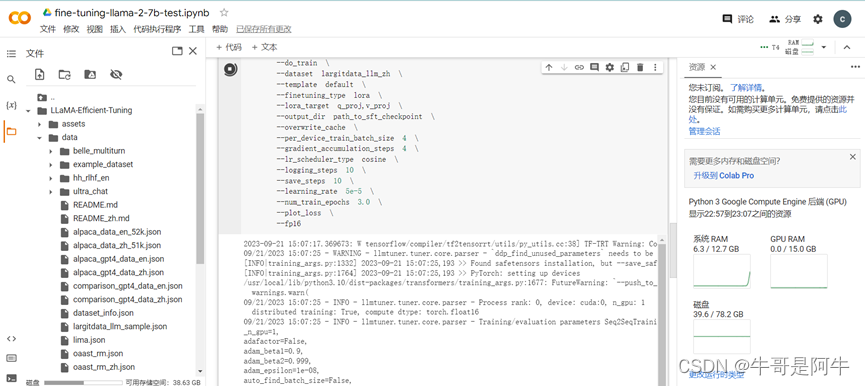
(1) 执行指令
执行步骤2)的指令,执行过程如下图所示
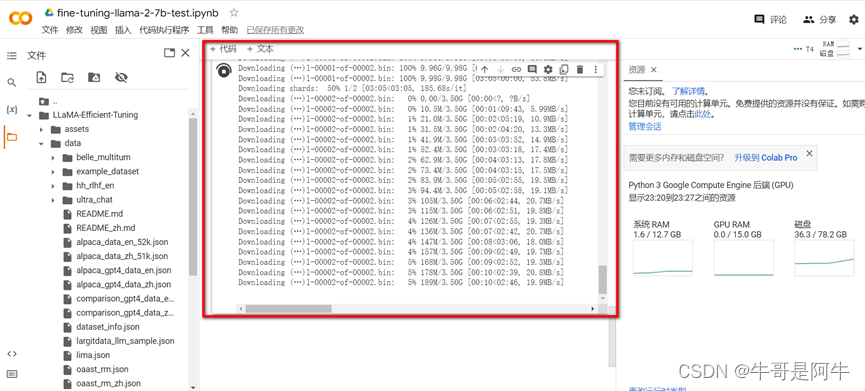
(2) 下载模型的过程
(3) 验证过程
如下是加载验证的过程,验证完成后就会基于自己上传的资料集进行训练/微调了
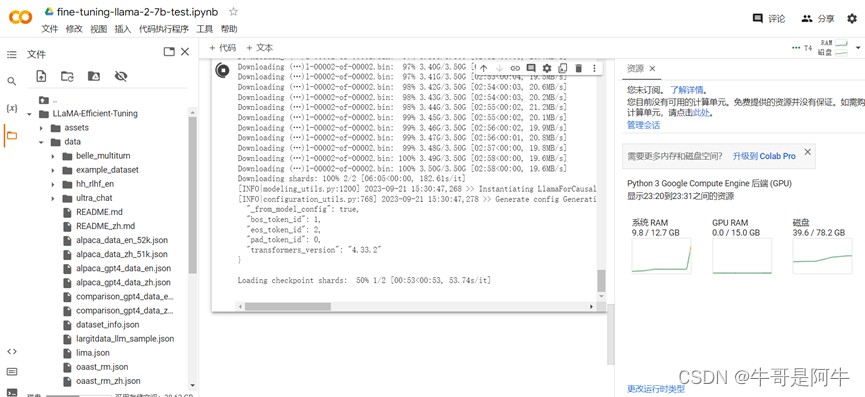
注:免费版本的系统RAM只有12.7GB,加载模型时可能会出现RAM资源不够,造成该步骤无法通过,需要升级到Colab Pro才可以。
(4) 微调训练过程

说明:
- Num examples = 1039,表示基于1039笔资料进行训练。如果用原始5万笔资料的话,GPU采用A100,训练需要大概8个小时左右。
- Num Epochs = 3,基于5万笔资料跑完成3个Epochs的话,需要大概1天的时间(基于A100)
- 5% 10/195,完成训练的5%,已经学习(Round)的数量为10,总共需要Round的数量为195
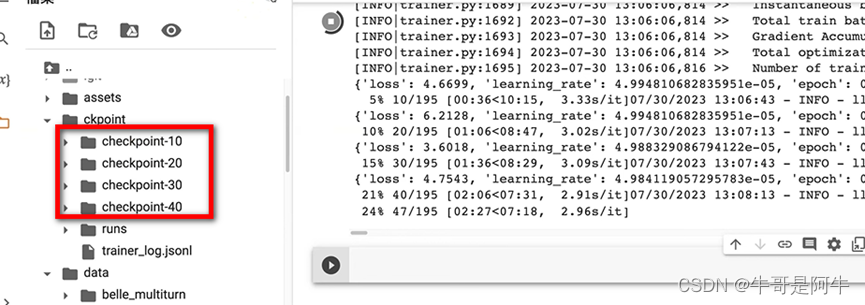
说明:上图中红框里表示每10步做一次保存。详情配置参见【1)介绍微调主要参数→(15)参数12【每多少步做记录】】
(5) 训练完成
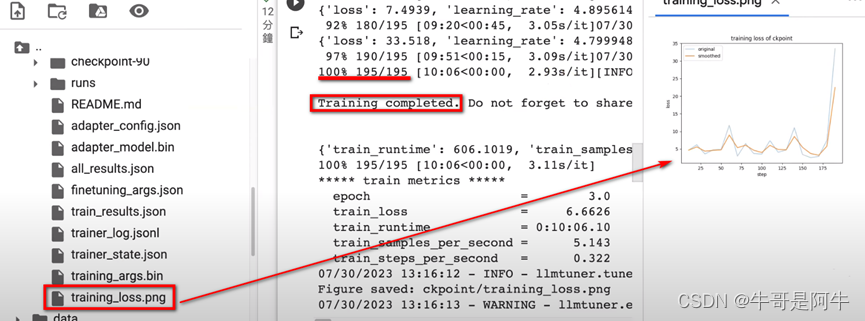
训练完成的结果会放到“training_loss.png”中。根据该结果,我们发现正常的loss结果应该是越来越低的,而该图中这个loss反而越来越高。主要的原因是我们使用的资料集比较少(1039)以及训练步骤没有那么多的原因所致。
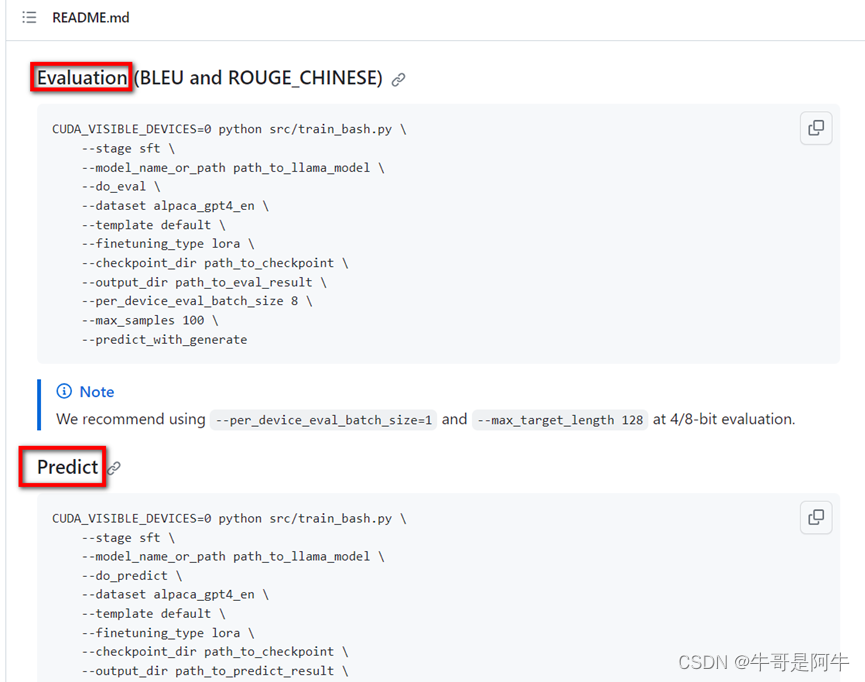
(6) 其他:训练完成后可以做评估/预测
训练完成后可以做评估/预测,看看是否精准















 542
542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









