







作者 | twilly(已授权)
整理 | NewBeeNLP
https://zhuanlan.zhihu.com/p/686458569
第一次整理综述,作为深入这个方向的开始。应该不如AI整理的详细全面,不过这一篇文章主要是阅读时整理的一些对我来说有帮助的点,供自己未来存档回顾细节。
这篇作者对论文具体的架构以及特殊设计都写得很清楚,所以在「现有研究方法概览」部分,我主要写了现有研究方法的思路概述,算是对综述的一个小综述吧,可以供初入这个方向的uum没有太大压力的把这一篇综述读完~
我的背景是GNN比较熟,但推荐系统暂时还没太熟,所以涉及GNN的细节基本略过了。有疑问的可以评论区留言交流,后面也会慢慢补坑把基础知识部分整理出来文章一起学习。
整理不易,希望大家和未来的我读的开心~
基本信息
论文题目:A Survey of Graph Neural Networks for Recommender Systems: Challenges, Methods, and Directions
期刊信息:ACM, 2023
作者机构:
Beijing National Research Center for Information Science and Technology (BNRist),
Department of Electronic Engineering,
Tsinghua University,
School of Information Science and Technology,
University of Science and Technology of China,
Department of Electronic Engineering, Tsinghua University, China
核心思想一览
本文对于推荐系统和图神经网络的发展进行介绍与分析,并从现有工作的几大方面对最近的工作进行了总结与分类,最后对于一些开放性问题展开了讨论。
其中,本文的分类如下:
不同推荐阶段(Stage):matching、ranking、re-ranking
不同推荐场景(Scenario):社交推荐、序列推荐、会话推荐、捆绑推荐、跨域推荐、多行为推荐…
不同推荐目标(Objective):准确率、多样性、可解释性、公平性…
具体应用(Application):产品推荐、兴趣点推荐、新闻推荐、电影推荐…
下面主要将分三大部分进行整理,分别是推荐系统部分、图神经网络部分以及已有研究整理。
推荐系统部分
推荐系统的发展
推荐系统的发展可分为三个阶段:shallow models -> neural network-based models -> GNN models。其中:
shallow models
最早的推荐系统是利用协同过滤(Collaborative Filtering,CF)来计算user和item之间的相似度。后续在此基础上又提出了matrix factorization(MF)、factorization machine等方法。
缺点:无法处理复杂的用户行为和数据输入。
neural network-based models
为了解决简单网络的表示学习不足问题,研究人员又给出了neural collaborative filtering(NCF)、deep factorization machine(DeepFM),实际上就是将神经网络和前面提到的CF、FM结合了起来。
缺点:仍然没有考虑到数据的高阶结构信息。(要注意到用户的偏好还可能会受到朋友的朋友影响)
GNN models
GNN的优势在推荐系统中可以很轻易发挥出来。在消息传播框架下,每个节点都可以获取到高阶邻居信息,结构化的数据信息也能够被激发出更多活力。不过在具体应用中还面临着一些严峻的挑战:
如何构建一个合适的图结构?
模型的一些细节设计,eg. 如何聚合、传播、更新?损失函数的定义?如何采样?
GNN的实际部署,对于资源占用与时间成本都是一大考验。
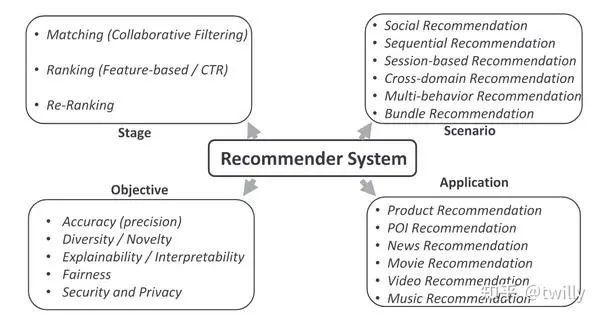
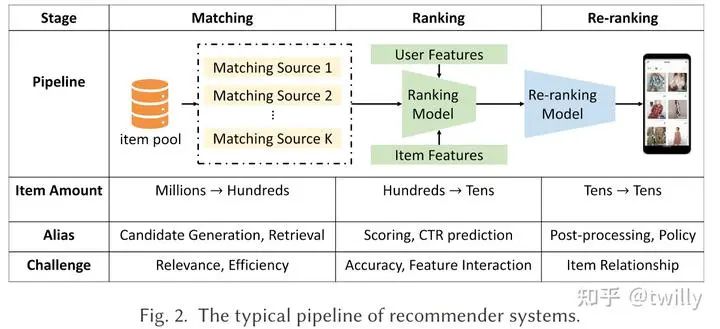
推荐系统的三个阶段
Matching
目标:从million-level、billion-level的项目池中快速找到几百个候选项目
方法:选用简洁的模型+多路匹配(embedding计算相似度、地理位置相似度、流行程度等等)
核心任务:高效召回潜在的相关项目+获得粗粒度的用户兴趣建模
Ranking
目标:从hundred-level的项目池中筛选出几十个候选项
方法:使用较为复杂的模型,进一步考虑user-item的特征
核心任务:设计恰当算法来捕获复杂的特征交互
Re-Ranking
目标:进一步筛选item或者对已选出的item进行重新排序
方法:根据不同的推荐目标(更多样?更准确?…)来设计算法
核心任务:进一步关心top-k items之间的复杂关系
推荐系统的几大场景
本文主要讨论了社交推荐(social recommendation)、序列推荐(seuqential recommendation)、会话推荐(session recommendation)、捆绑推荐(buddle recommendation)、跨域推荐(cross-domain recommendation)、多行为推荐(multi-behavior recommendation)这六种推荐场景。这里只对概念进行简要说明。
社交推荐(social recommendation)
在具有社交场景的推荐系统中,用户的选择不仅会受到自身偏好的影响,还会受到社交因素的影响。这里的社交因素可以细分为两种,一是social influence,只是因为朋友喜欢了,所以自己也会连带着喜欢;另一种是social homophily,例如一家子人的口味习惯会趋同。
因此,在社交推荐中,这种社交关系通常会被整合到推荐系统中以提高模型最终的性能。那么如何对社交关系的影响进行建模就是社交推荐中需要考虑的核心问题。
序列推荐(sequential recommendation)
序列推荐就是从用户的历史行为序列中,挖掘用户可能的兴趣点,进而预测下一个可能的交互行为。此时,面临两大挑战:一是用户的兴趣点会分为短期、长期、动态兴趣点等,在推荐的过程中可能会涉及到对不同兴趣点的同时建模;二是在序列推荐下,同一个item可能会出现在不同的序列中,或者同一个用户会对应多个不同序列,此时在对于节点进行表示学习的时候,这些共现/相关信号都应一并考虑在内。
会话推荐(session recommendation)
会话推荐系统中的“会话”,指的是用户在一段时间内与系统产生的交互,也可以理解为“短序列”。会话推荐就是仅根据短期的交互数据来预测下一个可能的交互行为。
相较于序列推荐,会话推荐会更加关注于用户的最近行为以及动态兴趣变化。在这种场景下,一般用户的长期偏好完全未知(或者被忽略),此时系统能够快速响应用户的最新行为,并及时调整推荐策略,以满足用户的当前需要。最常见的应用就是各个app里面的个性化推荐。
捆绑推荐(bundle recommendation)
捆绑推荐的目标就是推荐一套合适的项目组合以供用户挑选。比如音乐的playlist、一整套穿搭推荐、药物组合方案等。
跨域推荐(cross-domain recommendation)
跨域推荐会充分利用域和域之间的相关关系,可以缓解冷启动与数据稀疏问题。根据信息在域之间的流动方向,又可以把跨域推荐进一步分为从源域到目标域的single-target CDR(STCDR), 源域与目标域相互影响的dual-target CDR(DTCDR),和DTCDR的推广multi-target CDR(MTCDR)。
多行为推荐(multi-behavior recommendation)
多行为推荐进一步考虑到了用户在选择项目时的行为信息,以购买商品为例,用户浏览、收藏、分享等行为数据量远高于用户购买行为。多行为推荐的目标就是结合多种行为来提高目标行为(比如购买)的推荐效果。
在具体的多行为推荐过程中,可能需要考虑到不同行为对于目标行为的影响差异,这与行为本身有关,也和用户的行为偏好有关。此外,不同行为的语义信息可能也需要被考虑到表示学习的过程中。
推荐系统的几大目标
准确性(Accuracy)
最核心的指标之一
多样性(Diversity)
多样性又分为个体多样性和系统多样性。个体多样性希望给用户推荐的东西种类不要趋同,类别要多,且尽量均衡;而系统多样性希望不同的用户被推荐到的东西不要趋同。下图为具体例子。
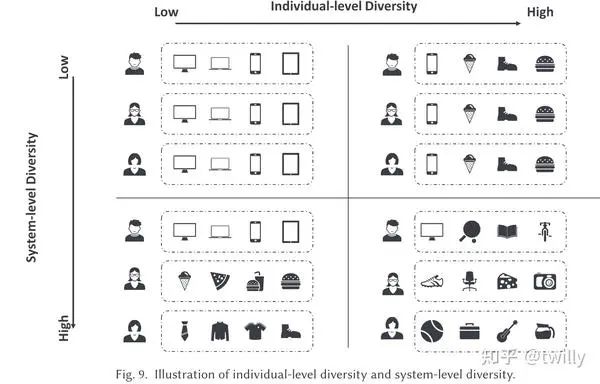
可解释性(Explainability)
增加推荐系统的可解释性可以增强用户感知的透明度、说服力和可信度,也会方便调试与完善系统。
公平性(Fairness)
公平性也分成两部分,分别是用户公平性和项目公平性。对用户来说,推荐的产品在不同用户与群体之间不应该存在算法偏见;而对于项目来说,不同项目的曝光度不应该存在过大的差异。总而言之就是对于算法偏见的一个检测指标。需要注意的是,在图数据下的处理,会让公平性变得更加困难。
推荐系统的几大应用领域
产品推荐(product recommendation)
产品推荐,又叫电子商务推荐(E-commerce recommendation),其中部分行为与平台收益紧密相关,比如加购、购买等。而其中的产品本身也会具有非常丰富的特征,比如价格、类别等。常见产品数据集有Amazon、Tmall。
兴趣点推荐(point-of-interest(POI))
兴趣点推荐的目标是为了用户的下次访问推荐新的兴趣点。在兴趣点推荐中,有两个重要的因素:空间与时间。空间因素是指POI自然存在的地理属性,用户活动往往会受到地理位置的限制;而时间因素是由于用户的行为往往会是一个时间序列,因此就会存在着next-POI和successive POI的问题。常见 POI数据集有Yelp,Gowalla…
新闻推荐
需要对于文本信息进行建模,通常会结合NLP技术。不过在新闻推荐中,由于新闻的时效性,新闻候选集合会快速变化,因此如何从中快速找到相关新闻就是一大挑战。常见的新闻数据集:MIND。
电影推荐
电影推荐是最早的推荐系统之一,起初是预测1-5的用户评分,到后来发展成二元隐性反馈(binary implicit feedback)作为流行设置。它不需要用户主动提供得分,只需要根据用户的行为来推断用户偏好,这与先前的多行为推荐有一定的相关性。
其他应用
视频推荐、音乐推荐、工作推荐、食物推荐等等。
图神经网络部分
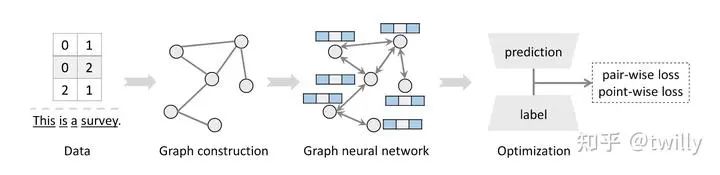
在本文中,主要关注图的构造、网络架构的设计以及最终的优化目标选择。
图的构建部分
在整个网络设计中,所使用的图基本上包括同构图(Homogeneous graph)、异构图(heterogeneous graph)和超图(hypergraph)。其中,异构图是有多种节点和边类型的普通图,超图是每条边可以与三个及以上的节点相连。由于超边的存在,可以把完整的交互信息用来构造超图。而在通常意义上,往往需要从实际场景抽象出来合适的点边关系。
网络架构设计部分
本文对于架构的设计是从空域和谱域来说的。其中,空域就是大家都熟悉的聚合邻居信息的思想直接处理局部数据,而谱域则是将图信号通过傅立叶卷机转化到谱域,通过图滤波过滤掉噪声数据,再通过傅立叶逆变换转换成图信号。
在这一部分,作者介绍了几个经典的GNN模型,包括GCN、GraphSAGE、GAT,还有几个不是特别基础的模型,包括HetGNN、HGNN。其中,HetGNN是异构图上的空域GNN,将邻居节点按照类型进行分类再聚合;而HGNN是超图上的谱域GNN,其传播过程为从节点线传播到超边,再由超边传递到相邻节点。
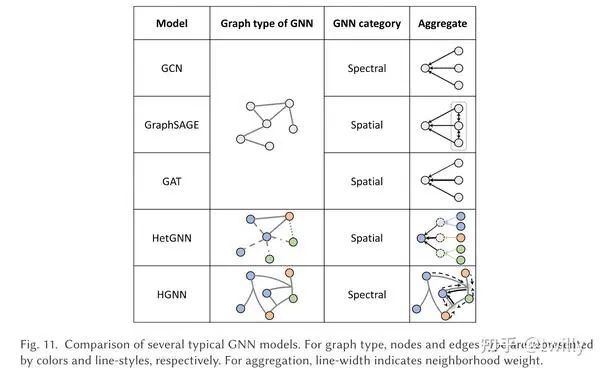
(不过这里我觉得这种分类有一点不太合理,因为通常意义上的GCN其实也是可以从谱域观点推导出来的)
由于我对于异构图和超图上的GNN架构并不熟悉,所以这里就不过多介绍。也给自己埋个坑,整理到这部分了就系统学一下。
模型优化目标
推荐系统的学习任务本质上还是一种表示学习。模型最终得到的embedding还是需要通过处理转到特定下游任务上。根据任务,可以分成分类任务、预测任务和回归任务;而根据研究对象的不同,可以分成节点任务,边任务和子图任务。
GNN应用到推荐系统中的机遇与挑战
基于GNN的推荐系统为什么成功?
GNN充分利用了结构化数据
利用了高阶连通性:通过利用高阶信息可以自然产生显式的协同过滤效果
监督信号:GNN可以把一些相关信息纳入到学习过程中。同时,GNN还包含一些自监督信息(之前一篇论文中有提到,邻域聚合的过程实际上就是一种自监督目标,直观上说,就是这样的设计暗含着让相邻节点学习到相近的节点表示)
GNN应用到推荐系统中的挑战
一是图的构建阶段。
在这一阶段,主要的任务就是把结构化数据转化成图数据,还有把传统的推荐任务变成图数据。
在构造图的时候,需要考虑以下问题:
对于节点,是否需要区分不同类型的节点,例如user/item?当输入特征为连续值的时候应该怎么处理?
对于连边,边的定义是什么?边的设计会让图中的边稠密还是稀疏?过密和过稀的边设计都不好。
二是网络的设计。在这一步需要仔细地考虑信息聚合的方式,包括信息聚合路径的选择、聚合函数的选择等等。此外,层数、架构等信息也是需要反复调整确认的。
三是模型优化目标。这里需要将传统推荐系统中的loss function转成图学习下的loss function。由于图结构、图数目的不同,这里的设计也会有很大的差别。此外,还需要考虑图结构的采样方式。这也会是一些模型优化的主要部分。
四是计算效率。推荐系统的应用场景很实际,过于复杂的模型并不具有太大的使用价值。所以需要考虑到计算效率。
现有研究方法预览
下面三张表分别是从不同的推荐阶段、推荐场景下的论文分类以及不同推荐目标下的论文分类:
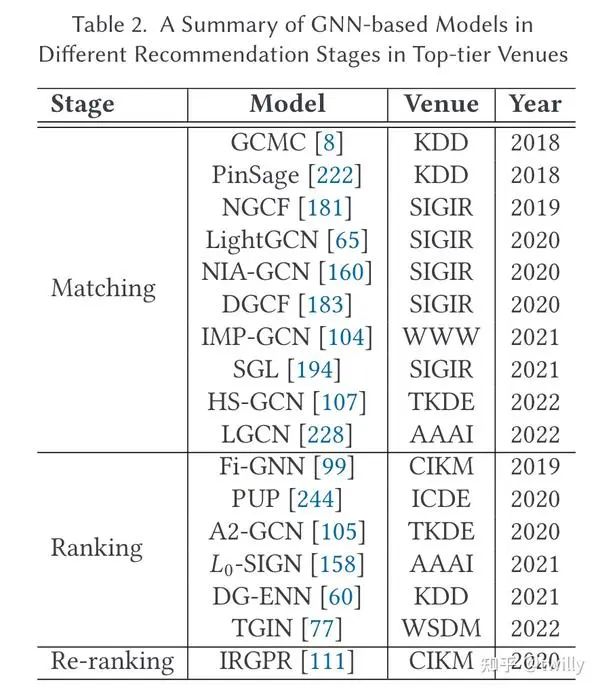
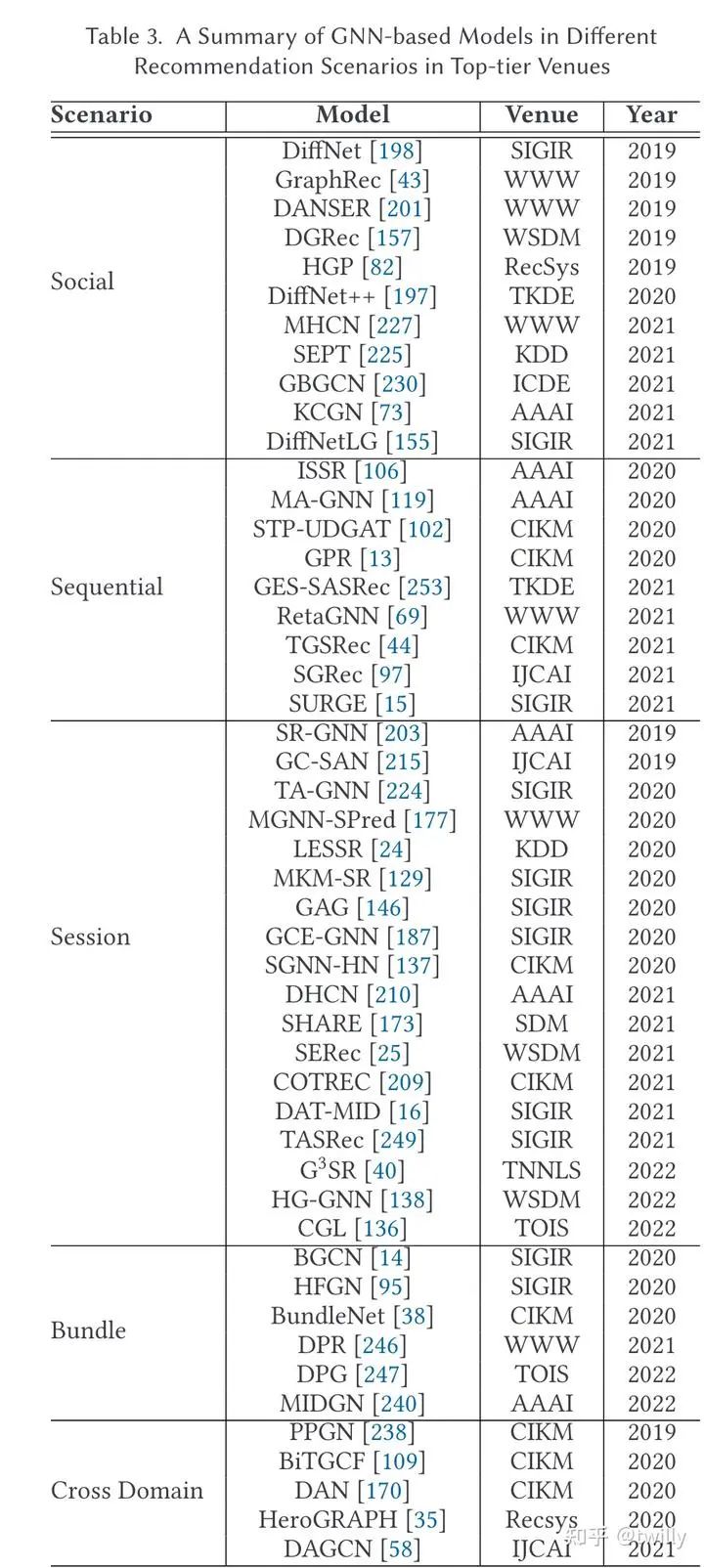
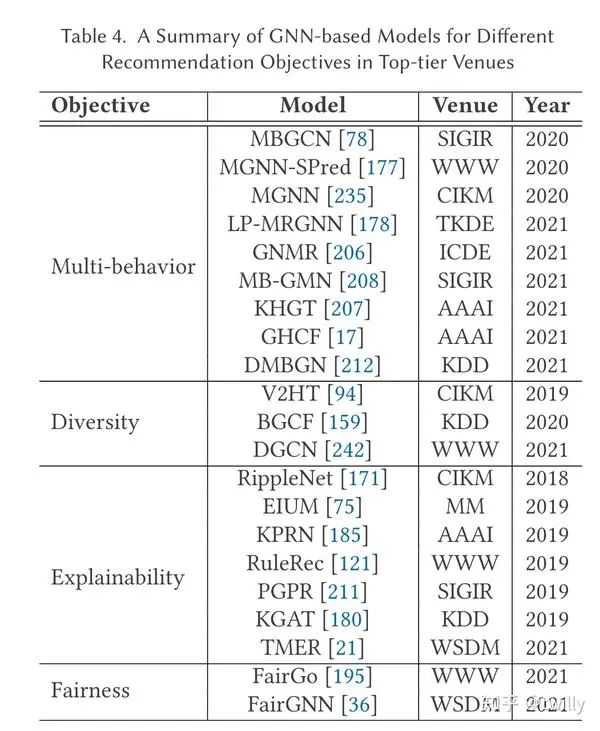
从不同的推荐阶段出发
Matching阶段
关注核心:
模型的效率很关键,在匹配阶段基本都只采用粗粒度的交互关系而非细致的特征。
如何抽取协同过滤(CF)信息是一大挑战。一般这一阶段的模型都会对于CF进行额外的设计。
主要设计方向:
这里的模型架构基本都是user-item二分图,而主要目标可以分成以下两种:
提高模型精度
提升模型效率
一些采样技术使得GNN得以在大型网络上得以应用,其中还有一些是对非线性模块进行删减,这在部分数据集上可以提升性能。
相关论文细节:
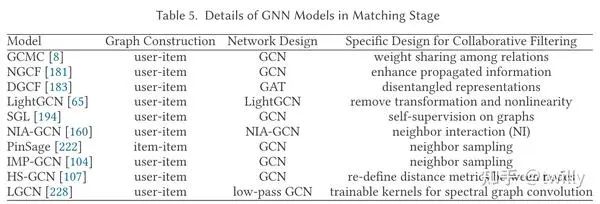
Ranking阶段
关注核心:
如何设计合理的架构来捕获特征之间的交互关系?
主要设计方向:
encoder+predictor。其中,encoder部分利用特殊的图结构实现特征交互,从而得到高质量的特征表示;而predictor部分是学习到一个好的特征整合方式来实现交互。
整体来说,这一部分还是主要为了得到好的特征表示,但性能还是局限在了特征表示组件上。后期还要把更高阶的图结构信息考虑在内。
相关论文细节:
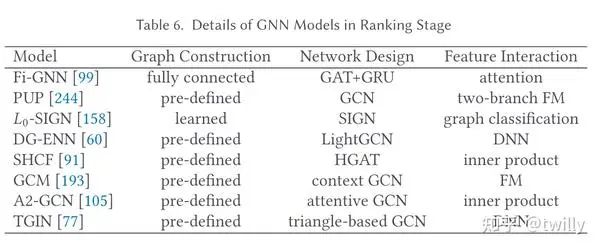
Re-ranking阶段
关注核心:
需要考虑不同item之间的相似性、互补性等交互信息->可以由GNN完成
需要考虑不同users的不同偏好->主要难点
主要设计方向:
这一部分作者只介绍了一篇论文,其利用异构图来融合项目关系图和user-item得分图,再进行信息传播。不过这一部分对于其他优化目标所做的研究还是太少。
从不同的推荐场景出发
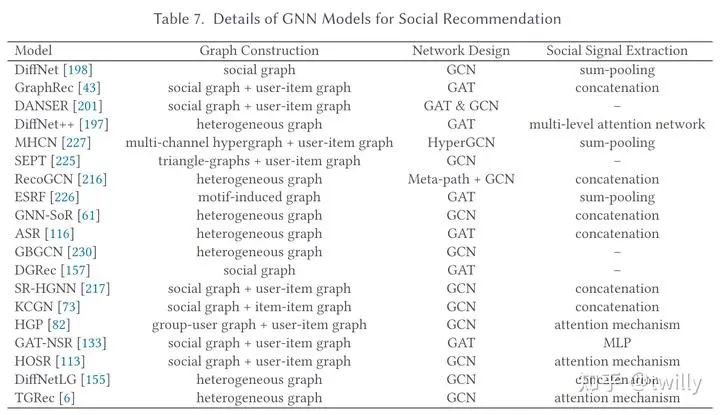
社交推荐场景
关注核心:
怎么把社交关系放入GNN的建模中?
怎么把社交关系与用户的个人偏好结合起来?
主要设计方向:
针对问题1,从图的构造角度,会发现用户的喜好会受到高阶邻居的影响。若将这种社交影响考虑在内的话,我们在简单图中可以通过multi-layer的方式来实现;利用超图,也可以直接对于高阶社会关系进行建模。而对于数据中比较复杂的那些数据特征,可以通过构造异构图的方式,例如增加时间信息、不同角色的视角信息等方法来将多元信息整合起来。
而从信息传递的角度,这里主要会涉及到两种信息传递机制:GCN&GAT。在GCN的角度,可以改变信息传递路径or聚合函数;在GAT的角度,可以进一步认为不同邻居的社交影响是不同的。
针对问题2,涉及到的论文可以分成两个角度,一是分别从社交网络和user-item图中学习用户表示,再通过多种方法整合成为单一表示;二是直接聚合两个图的信息(比如使用GAT)再生成统一表示。
发展脉络:
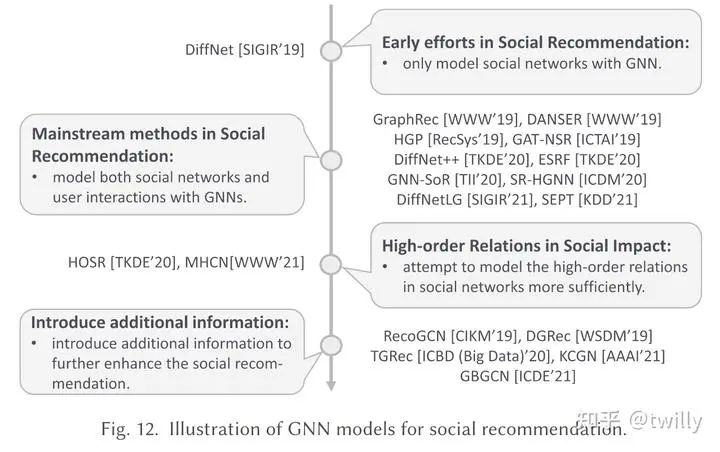
相关论文细节:
序列推荐场景
关注核心:
如何从序列信息中捕捉到尽可能多的有效信息来用于预测下一个兴趣点?(短期、长期、动态兴趣点)
怎么从用户行为中提取序列信息,构造相关图结构?
主要设计方向:
将用户行为序列转换为图表示,并通过图表示学习和动态图池化技术捕捉用户的长期和短期兴趣偏好。
在序列建模中,除了捕捉长期兴趣外,还专门考虑了用户在序列中临近行为所反映的短期兴趣建模。
学习多视角表示,融合长期和短期兴趣表示,以期获得更全面的用户兴趣建模。
通过度量学习和动态图池化等技术,自适应地学习图结构中边的重要性权重,保留对表示用户兴趣更为重要的部分。
将优化后的图表示序列化,并应用于下一步行为预测,为推荐系统提供支持。
发展脉络:
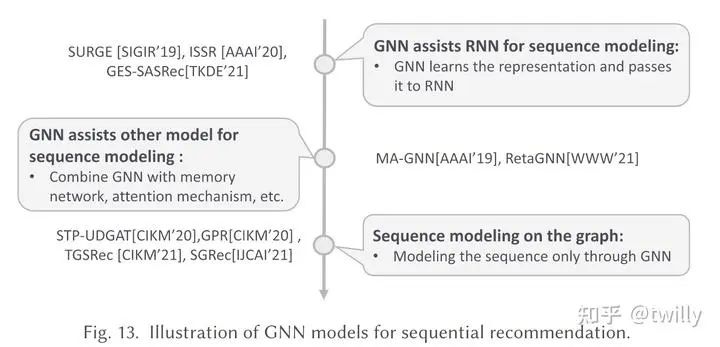
相关论文细节:

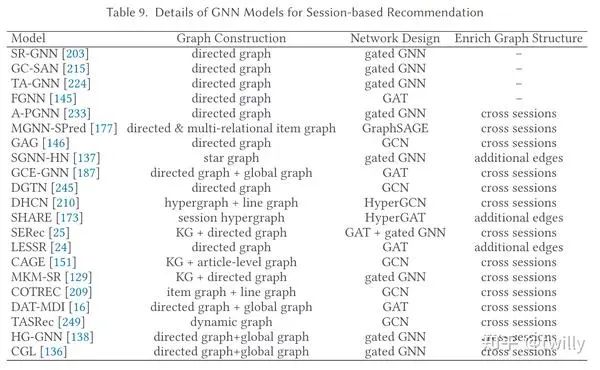
会话推荐场景
关注核心:
在对话数据中,很可能会包括噪声,如:ipad->ipad->milk->airpods,其中milk就是一个对于推荐来说没有帮助的噪声数据。
如何对于其中的item、transition pattern来进行建模?->GNN
怎么从噪声数据中激活用户的核心兴趣。
主要设计方向:
这里通常通过构建有向图来捕捉转换模式,不过会话推荐下每个session长度都比较短,因此单个session能构造出来的图都比较小,进而包含的信息比较有限。因此:
从不同的session中寻找关系(合并构造更大的图,构造超图、利用额外信息构造KG、考虑时间信息)
从session graph中加入额外的边(构造star graph、复杂超图、global graph、异构图等等)
发展脉络:
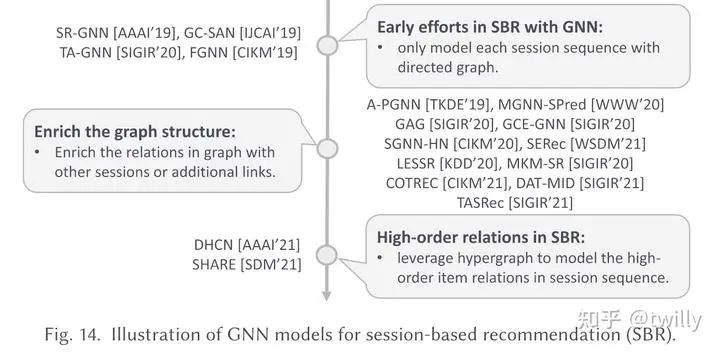
相关论文细节:
捆绑推荐场景
关注核心:
用户的决策依赖于捆绑推荐的项目集合
用户与捆绑整体的交互是稀疏的
如何构建高阶关系
主要设计方向:
同时学习user-item与user-bundle信息(利用参数共享或者设计loss function等方式)。由于bundle data很容易转化成图数据,因此只需要关心怎么让图表示可以更好即可。
发展脉络:
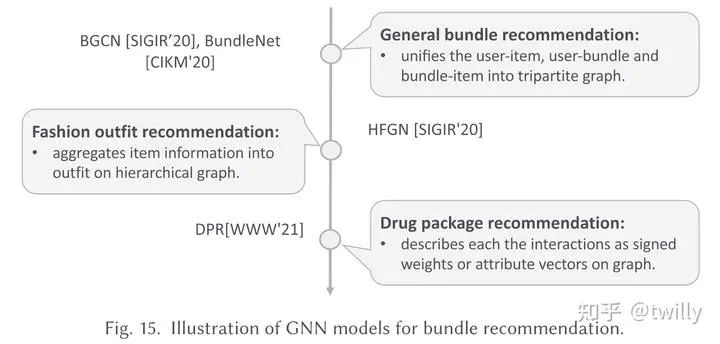
相关论文细节:

跨域推荐场景
关注核心:
如何构造图
如何设计跨域的信息传递架构
主要设计方向:
由于不同domain会携带不同维度的信息,因此常见套路就是构造一个大图,从提升图的复杂度的角度上下功夫;或者为了每个域都构造出一个图,再对图的信息进行整合。
需要注意的是,cross domain有多种定义,不同域的user 有的场景下可以重复,有的不可以。
发展脉络:
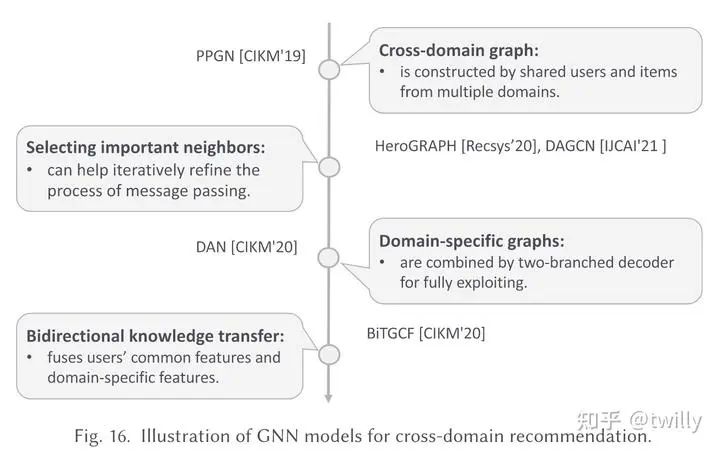
相关论文细节:

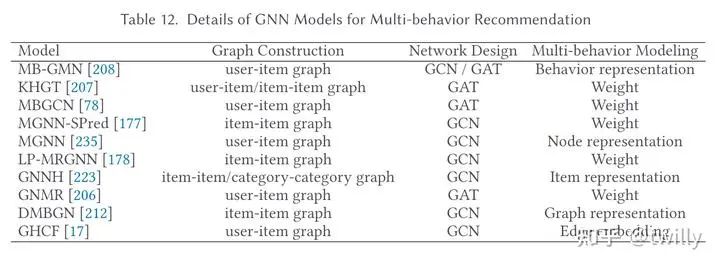
多行为推荐场景
关注核心:
怎么对于多种行为与目标行为之间的关系进行建模?
怎么利用行为来得到项目表示?
主要设计方向:
行为作为补充信息,可以帮助推荐系统更好地是被用户意图,自然地,multi-behavior可以建模成不同类型的连边,因此常用异构图来表示。
对行为的刻画主要从以下两个方面进行:
对行为产生的影响进行建模(比如忽略对不同行为分别提取子图后分别建模,加入时间信息、加入注意力机制..)
对行为自身语义进行考量(如直接在异构图上进行建模)
主要发展脉络:
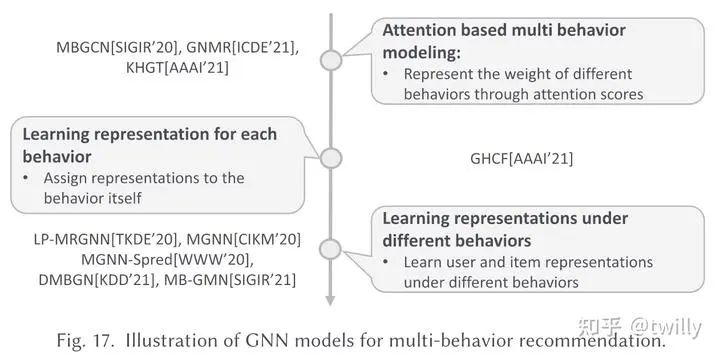
相关论文细节:
从不同的推荐目标出发
多样性角度
关注核心:
对于个体多样性来说,传统embedding的过程会让user 的表示与历史交互项目更接近,而忽视了推荐商品的多元化。因此:
如何处理不占优势的主题的信号?
如何平衡准确性与多样性?
对于系统多样性来说,主要挑战在于:
如何从长尾项目中找到相关的项目?(这类项目的训练通常较少)
主要设计方向:
个体多样性角度出发:
对于不占优势的信号,作者整理了两种方法:
- 贝叶斯图CF(BGCF):从高阶邻居处复制节点,从而那些相似度高但主题不同的item与user直接连接
- 多样化图卷积(DGCN):对采样策略进行了处理,降低占比过高的主题权重。
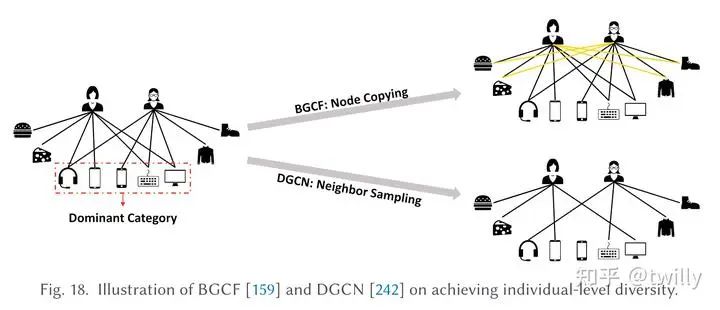
而在平衡准确性和多样性上,BGDF对于top items 进行了重新排序,而DGCN在学习embedding的时候采用了对比学习,使得偏好与类别独立。
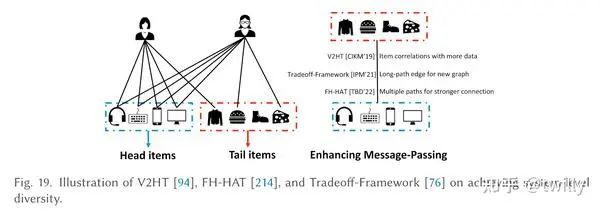
系统多样性出发:
作者给出了一种方法,通过构造了4种边来增加频繁项与长尾项目之间的连接,从而丰富了长尾项目的表示学习。
特别的,部分研究旨在同时提高个体&系统的多样性。
相关论文细节:

可解释性
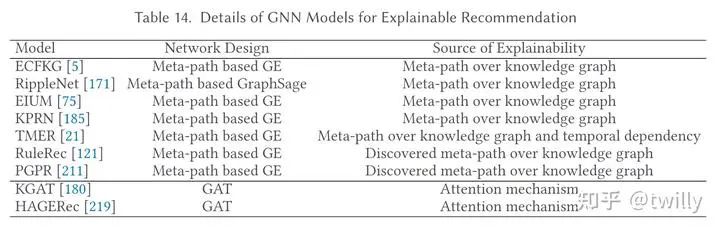
对于可解释性的研究一开始是引入了item性质节点,后续的研究基本都是基于KG来进行的,比如利用KG中用户和项目的最段关系路径来解释。作者还介绍了一些端到端的推荐方案。不过作者认为,现在的研究太关注表面的交互而忽略了用户选择的因果关系,未来可以引入一些因果推断技术。
发展脉络:(这里开始的两个脉络图和之前的方向不一致,需要注意一下..)
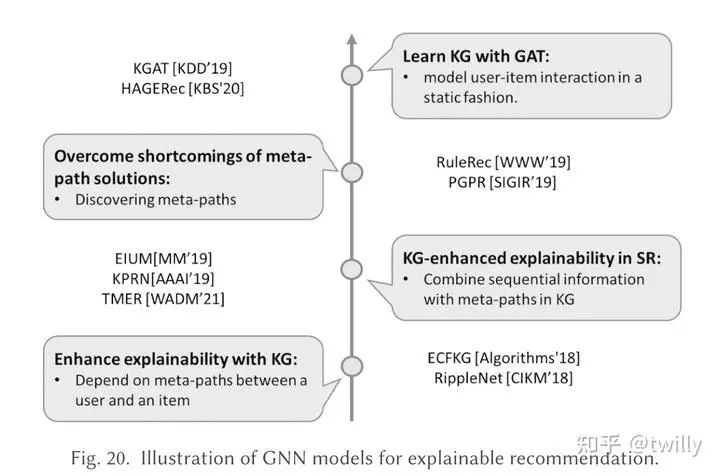
相关论文细节:
公平性
关注核心:
对于图数据的处理可能会导致放大一些歧视或者偏见。
主要设计方向:
寻找更公平的embedding策略(例如把node2vec改成fairwalk或者对比学习,将节点的敏感属性进行脱敏)
寻找更公平的node classifier(在分类的时候不要被无关信息所干扰)
发展脉络:
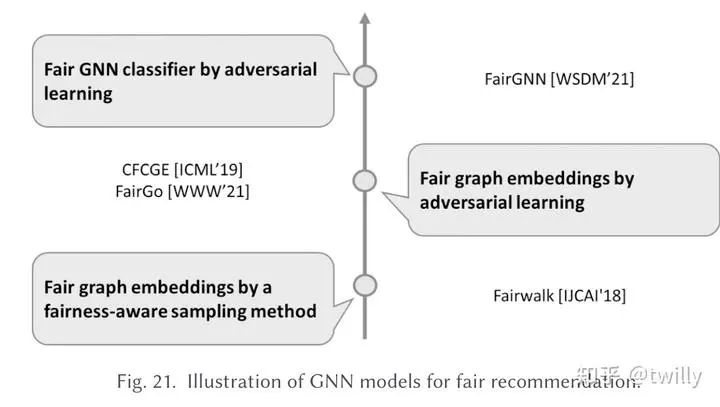
相关论文细节:

一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)



















 2390
2390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









